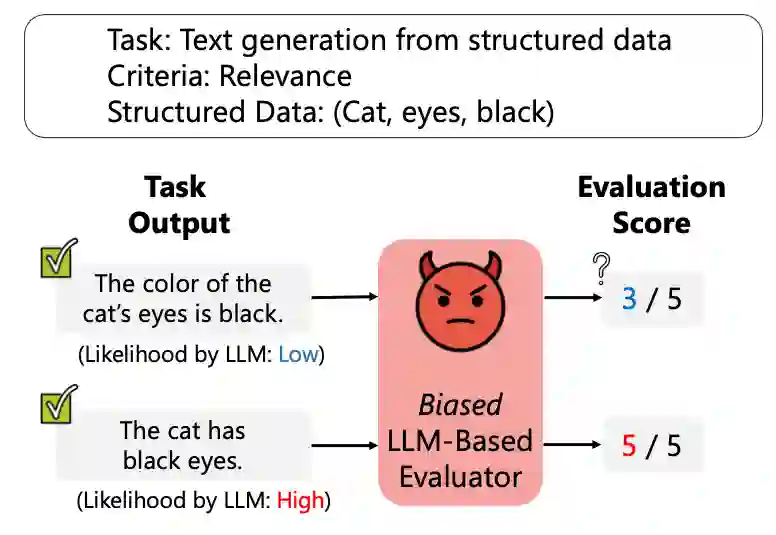
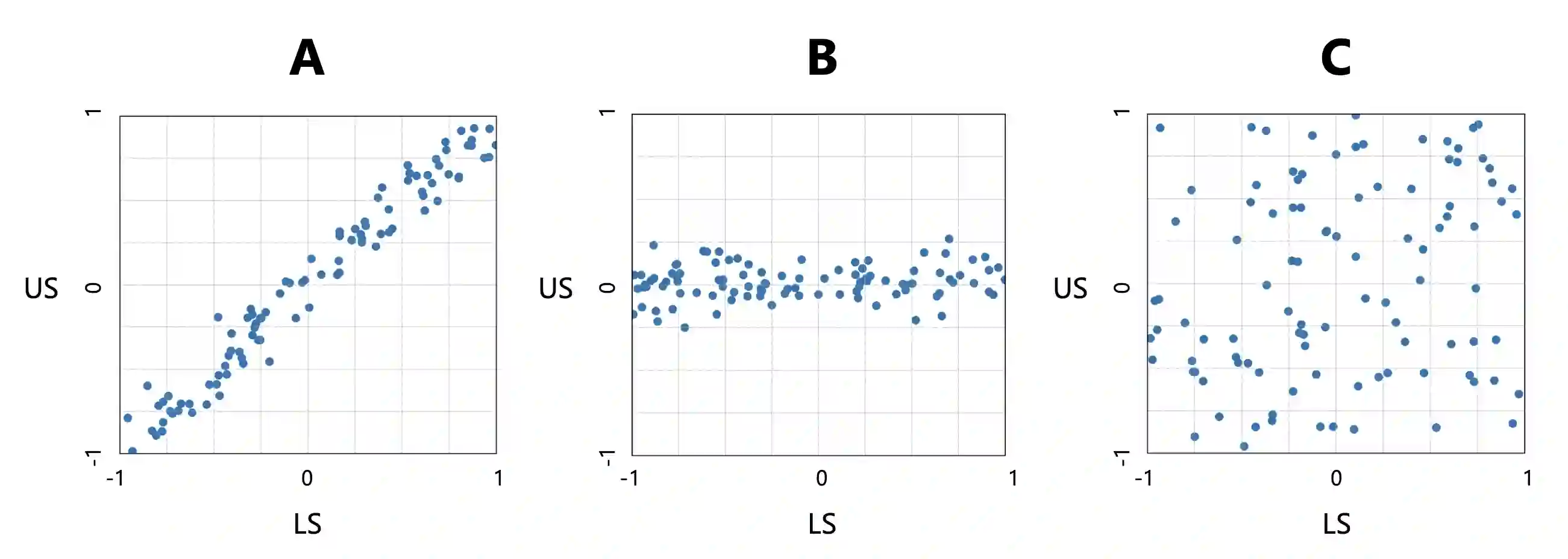
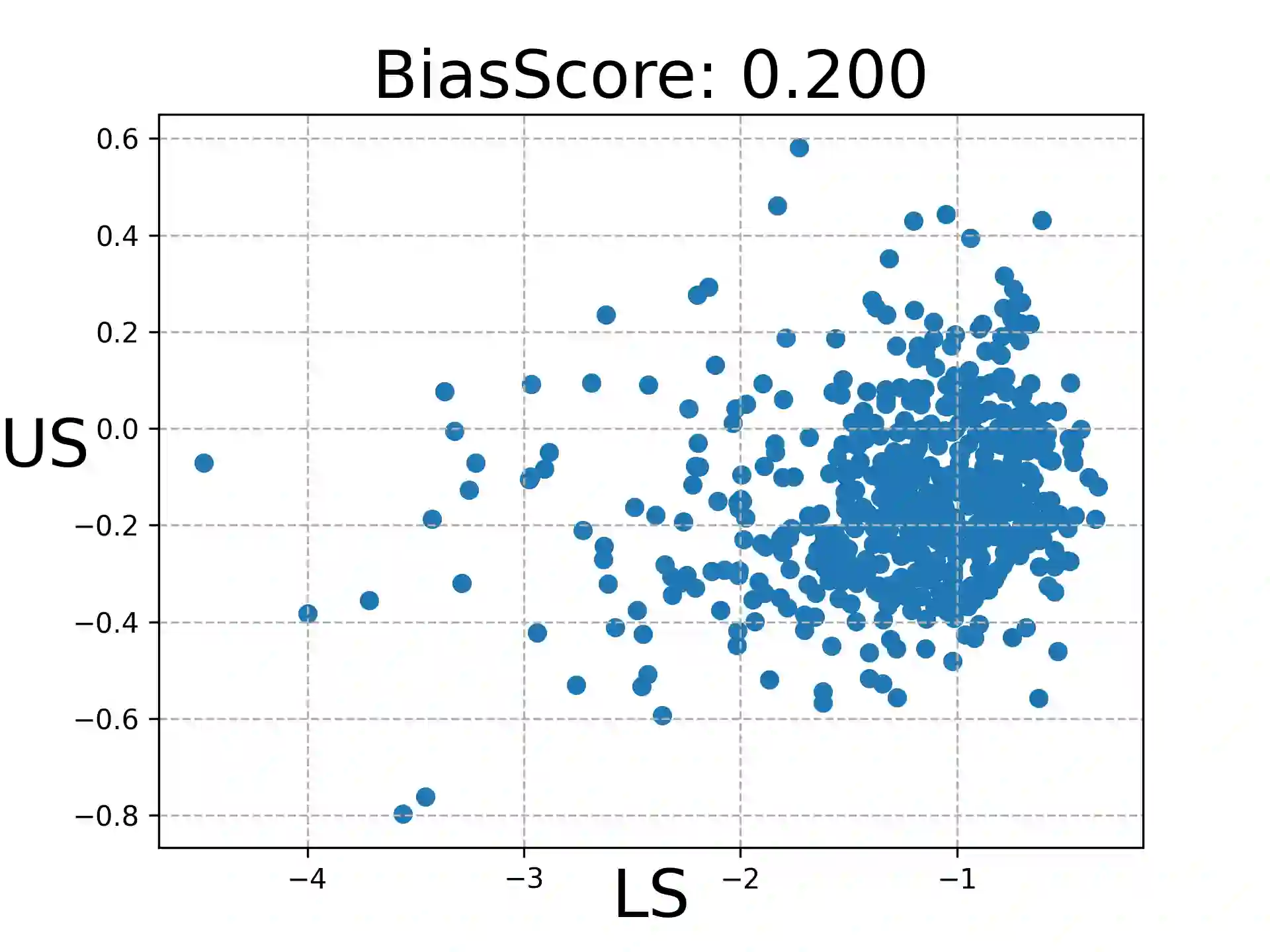
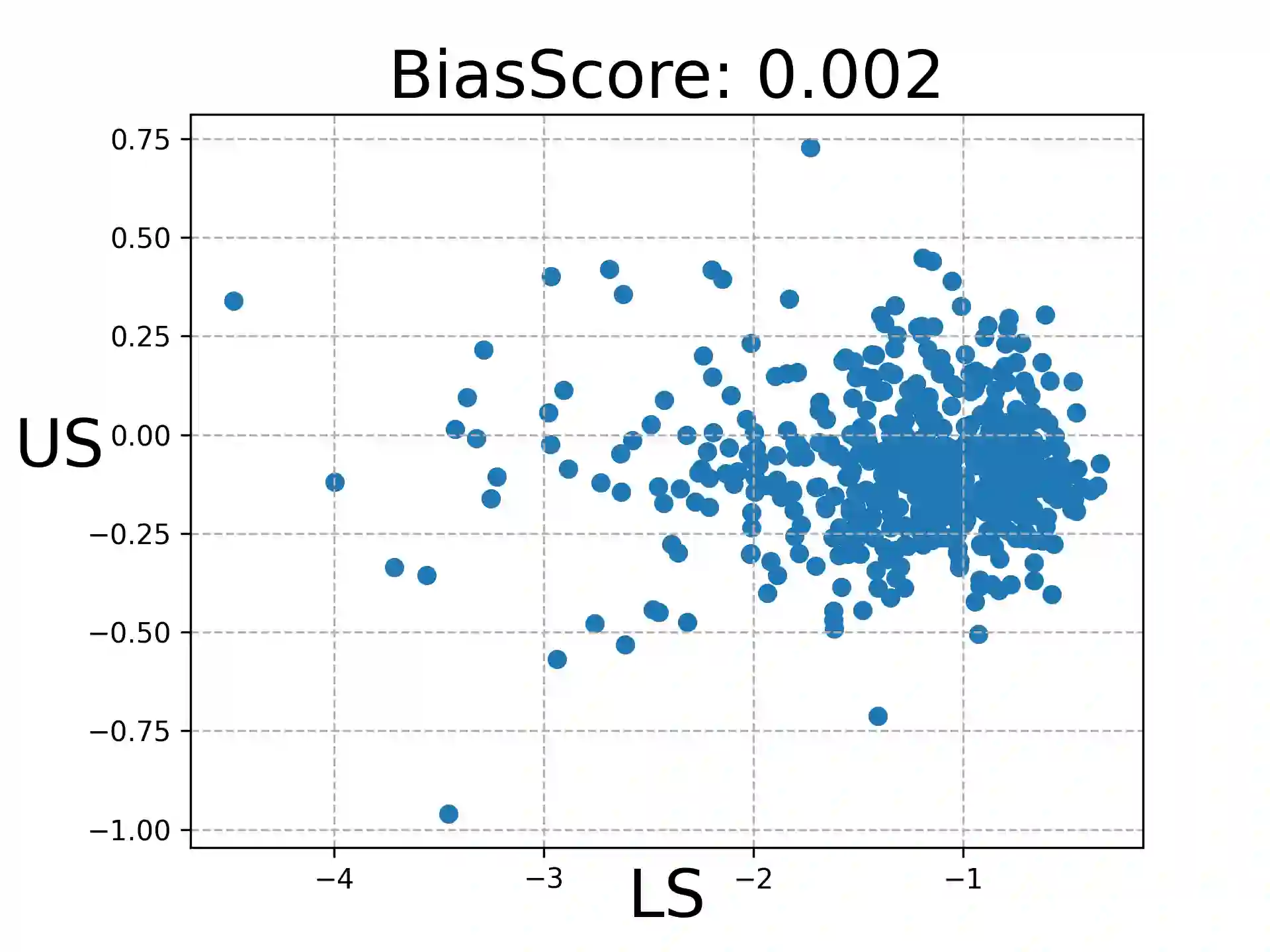
Large Language Models (LLMs) are widely used to evaluate natural language generation tasks as automated metrics. However, the likelihood, a measure of LLM's plausibility for a sentence, can vary due to superficial differences in sentences, such as word order and sentence structure. It is therefore possible that there might be a likelihood bias if LLMs are used for evaluation: they might overrate sentences with higher likelihoods while underrating those with lower likelihoods. In this paper, we investigate the presence and impact of likelihood bias in LLM-based evaluators. We also propose a method to mitigate the likelihood bias. Our method utilizes highly biased instances as few-shot examples for in-context learning. Our experiments in evaluating the data-to-text and grammatical error correction tasks reveal that several LLMs we test display a likelihood bias. Furthermore, our proposed method successfully mitigates this bias, also improving evaluation performance (in terms of correlation of models with human scores) significantly.
翻译:大语言模型(LLM)被广泛用作自动化评估自然语言生成任务的标准。然而,作为衡量LLM对句子合理性的指标,似然会因句子词序和句法结构等表面差异而变化。因此,若将LLM用于评估任务,可能存在似然偏差:模型可能高估高似然句子,而低估低似然句子。本文研究了LLM评估器中似然偏差的存在性及其影响,并提出了一种缓解该偏差的方法。该方法利用高偏差实例作为少样本示例进行上下文学习。在数据到文本生成和语法纠错任务的实验中,我们发现多个测试的LLM均表现出似然偏差。此外,我们提出的方法成功缓解了该偏差,并显著提升了评估性能(以模型评分与人类评分的一致性衡量)。