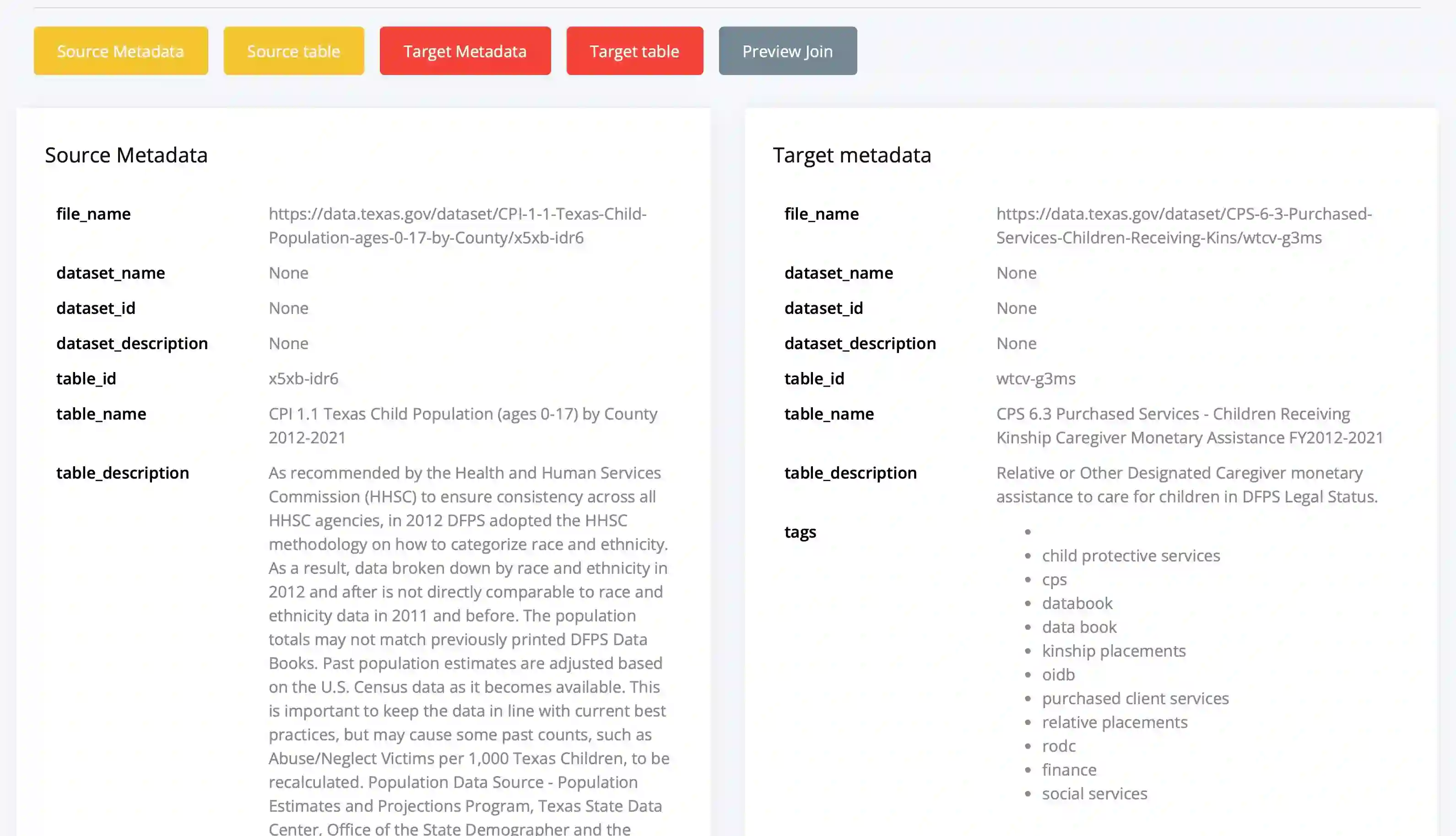
Joinable Column Discovery is a critical challenge in automating enterprise data analysis. While existing approaches focus on syntactic overlap and semantic similarity, there remains limited understanding of which methods perform best for different data characteristics and how multiple criteria influence discovery effectiveness. We present a comprehensive experimental evaluation of joinable column discovery methods across diverse scenarios. Our study compares syntactic and semantic techniques on seven benchmarks covering relational databases and data lakes. We analyze six key criteria -- unique values, intersection size, join size, reverse join size, value semantics, and metadata semantics -- and examine how combining them through ensemble ranking affects performance. Our analysis reveals differences in method behavior across data contexts and highlights the benefits of integrating multiple criteria for robust join discovery. We provide empirical evidence on when each criterion matters, compare pre-trained embedding models for semantic joins, and offer practical guidelines for selecting suitable methods based on dataset characteristics. Our findings show that metadata and value semantics are crucial for data lakes, size-based criteria play a stronger role in relational databases, and ensemble approaches consistently outperform single-criterion methods.
翻译:可连接列发现是自动化企业数据分析中的关键挑战。现有方法主要关注语法重叠和语义相似性,但对于不同数据特征下何种方法表现最优、以及多准则如何影响发现效果的理解仍然有限。本文对多种场景下的可连接列发现方法进行了全面的实验评估。研究在涵盖关系型数据库和数据湖的七个基准测试上比较了语法与语义技术。我们分析了六个关键准则——唯一值数量、交集大小、连接大小、反向连接大小、值语义和元数据语义——并探讨了通过集成排序组合这些准则对性能的影响。分析揭示了不同数据情境下方法行为的差异,并强调了整合多准则对实现稳健连接发现的优势。我们提供了关于各准则适用场景的实证证据,比较了用于语义连接的预训练嵌入模型,并基于数据集特征给出了选择合适方法的实用指南。研究结果表明:元数据和值语义对数据湖至关重要,基于大小的准则在关系型数据库中作用更显著,而集成方法始终优于单准则方法。