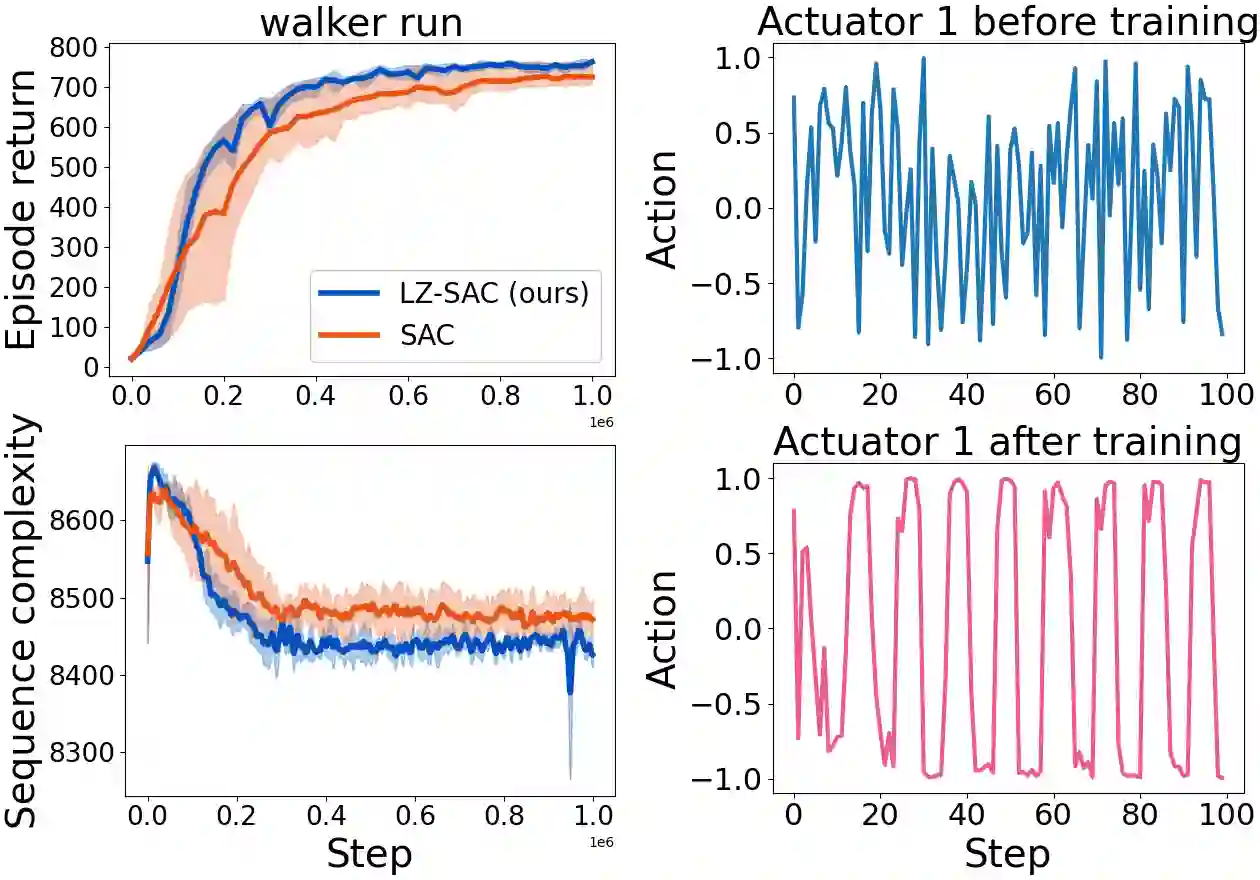
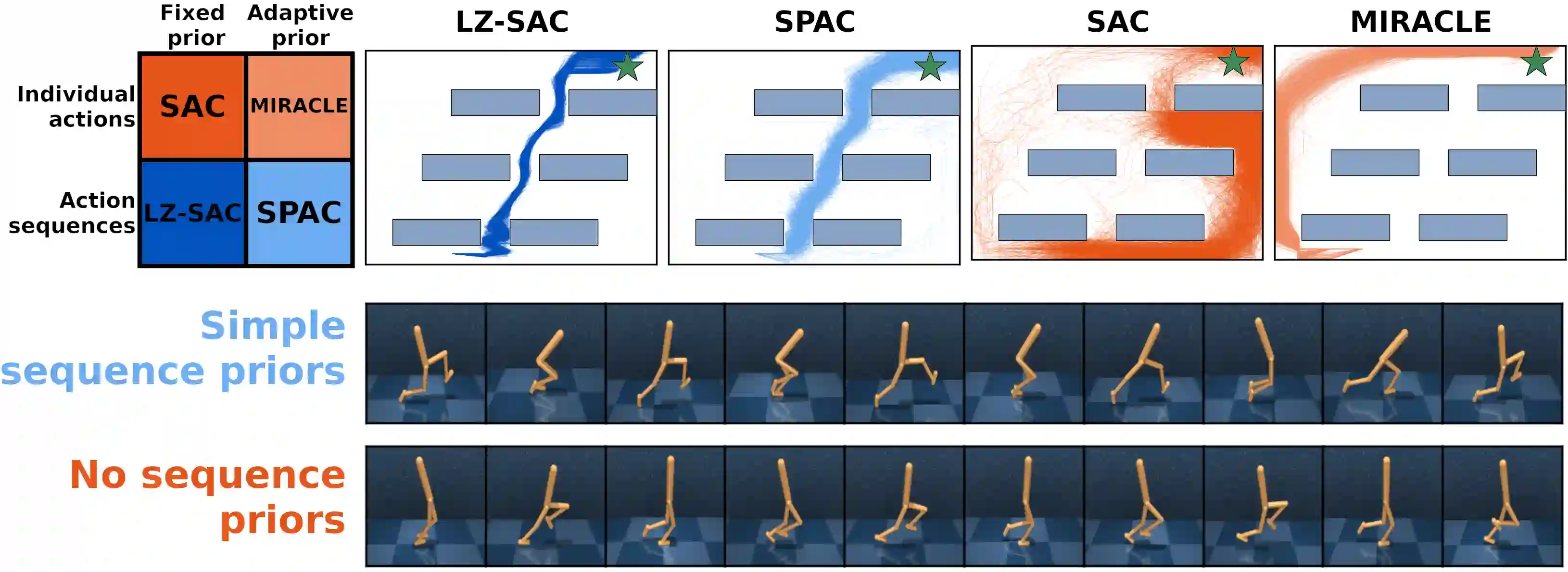
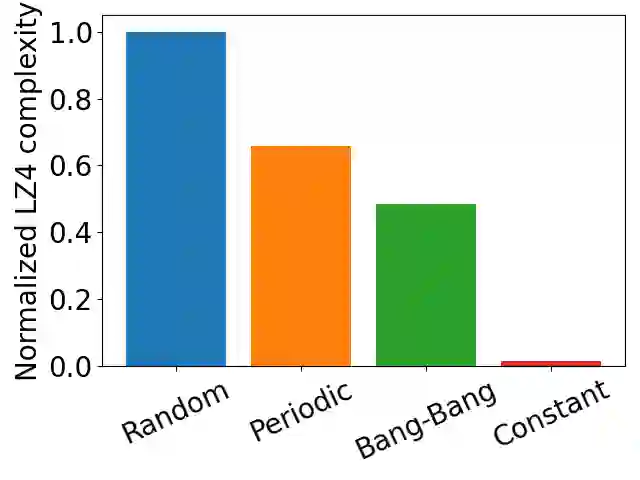
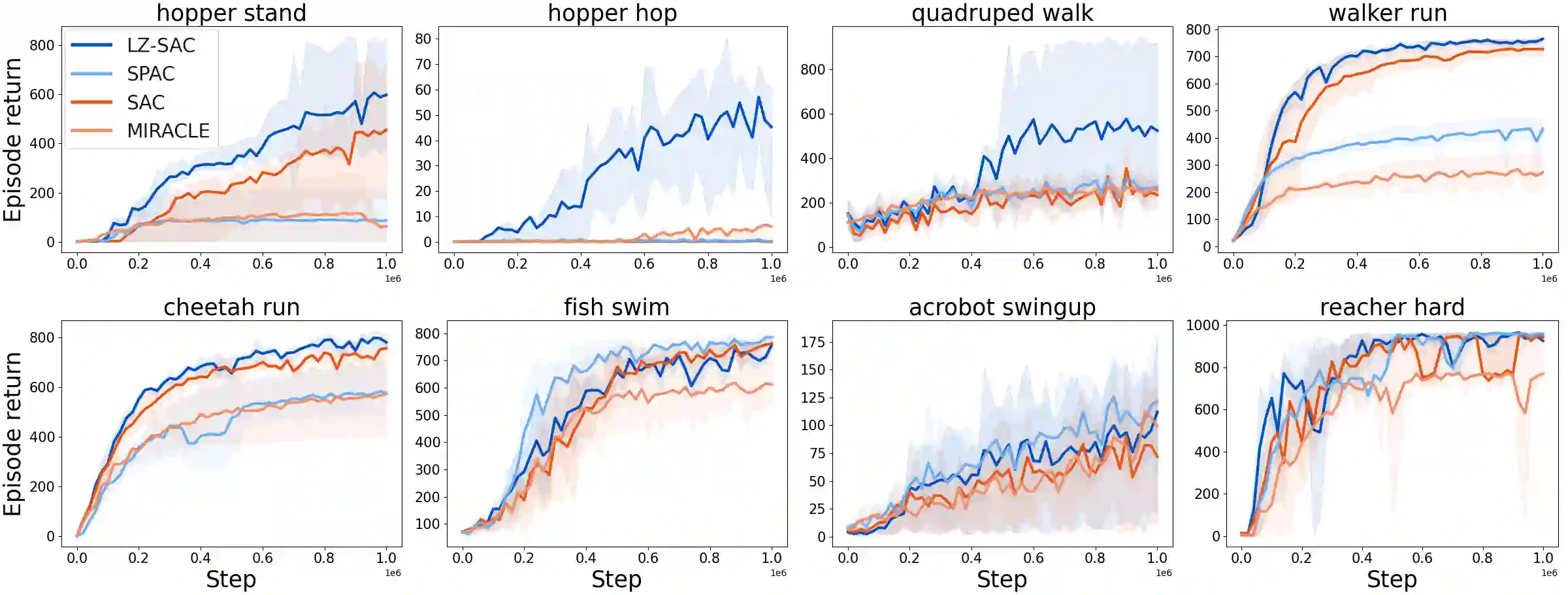
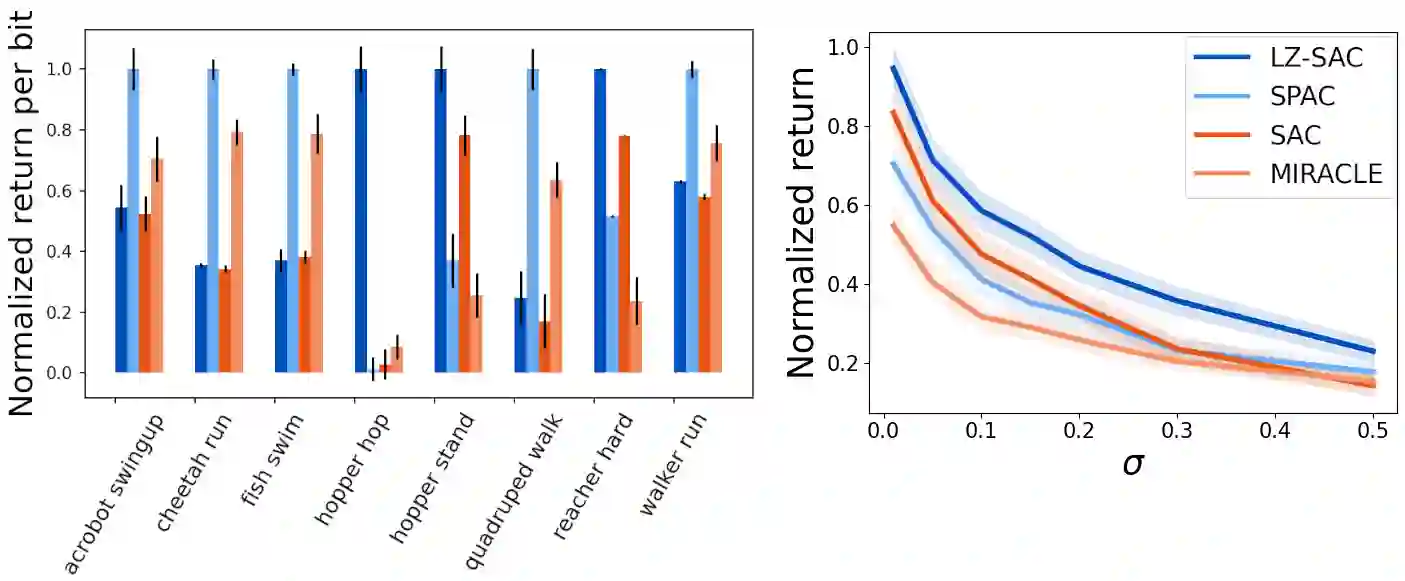
Everything else being equal, simpler models should be preferred over more complex ones. In reinforcement learning (RL), simplicity is typically quantified on an action-by-action basis -- but this timescale ignores temporal regularities, like repetitions, often present in sequential strategies. We therefore propose an RL algorithm that learns to solve tasks with sequences of actions that are compressible. We explore two possible sources of simple action sequences: Sequences that can be learned by autoregressive models, and sequences that are compressible with off-the-shelf data compression algorithms. Distilling these preferences into sequence priors, we derive a novel information-theoretic objective that incentivizes agents to learn policies that maximize rewards while conforming to these priors. We show that the resulting RL algorithm leads to faster learning, and attains higher returns than state-of-the-art model-free approaches in a series of continuous control tasks from the DeepMind Control Suite. These priors also produce a powerful information-regularized agent that is robust to noisy observations and can perform open-loop control.
翻译:在其他条件相同的情况下,应优先选择更简单的模型而非复杂模型。在强化学习(RL)中,简单性通常基于逐动作进行量化——但这种时间尺度忽略了序列策略中常见的时间规律性(如重复模式)。因此,我们提出一种能够学习通过可压缩动作序列来解决问题的强化学习算法。我们探索了两种可能的简单动作序列来源:可通过自回归模型学习的序列,以及可通过现成数据压缩算法进行压缩的序列。将这些偏好提炼为序列先验后,我们推导出一个新颖的信息论目标函数,该函数激励智能体在最大化奖励的同时遵循这些先验来学习策略。我们证明,在DeepMind控制套件的一系列连续控制任务中,该强化学习算法能实现更快的学习速度,并比最先进的无模型方法获得更高的回报。这些先验还生成了一个强大的信息正则化智能体,该智能体对噪声观测具有鲁棒性,并能执行开环控制。