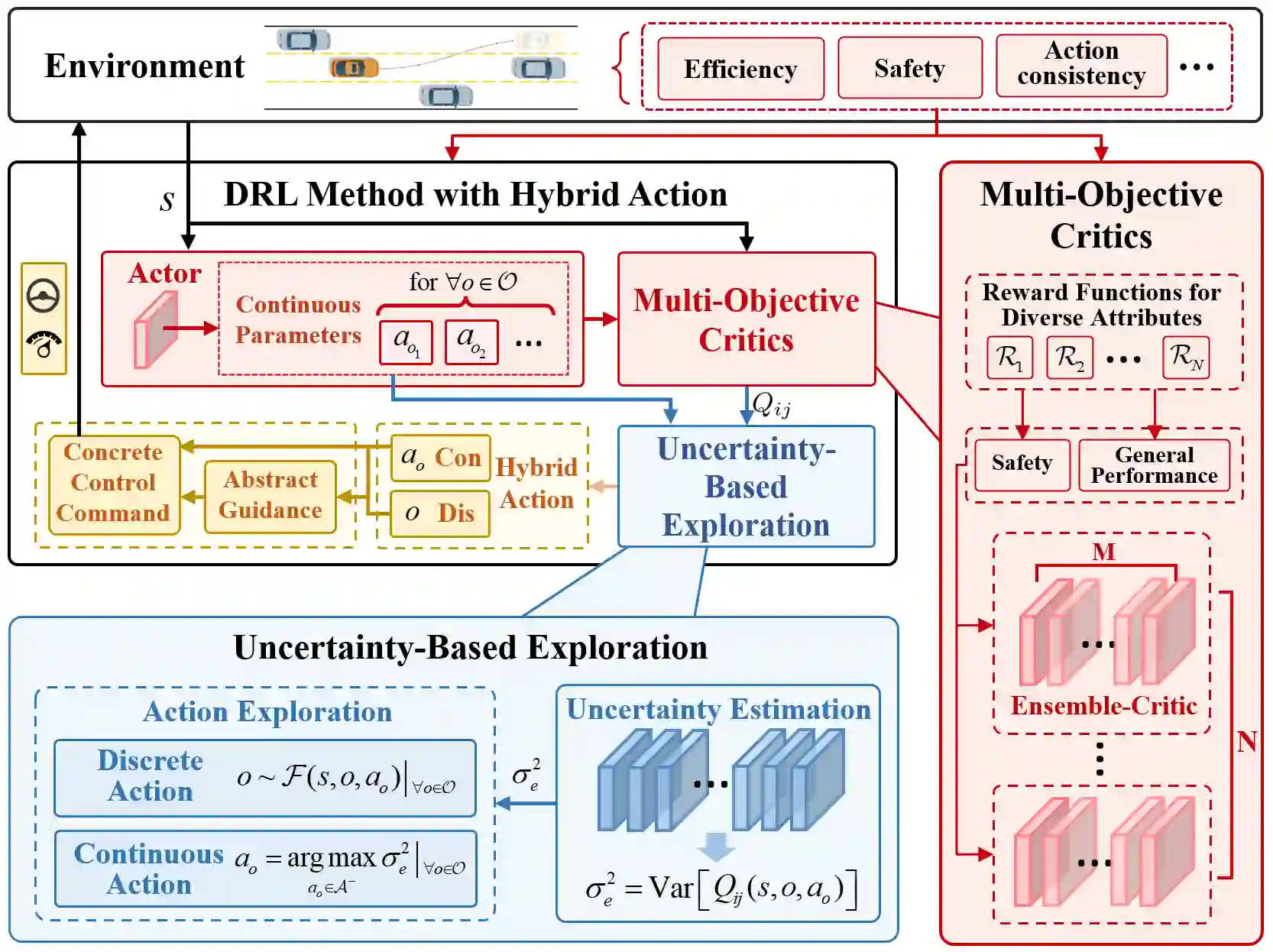
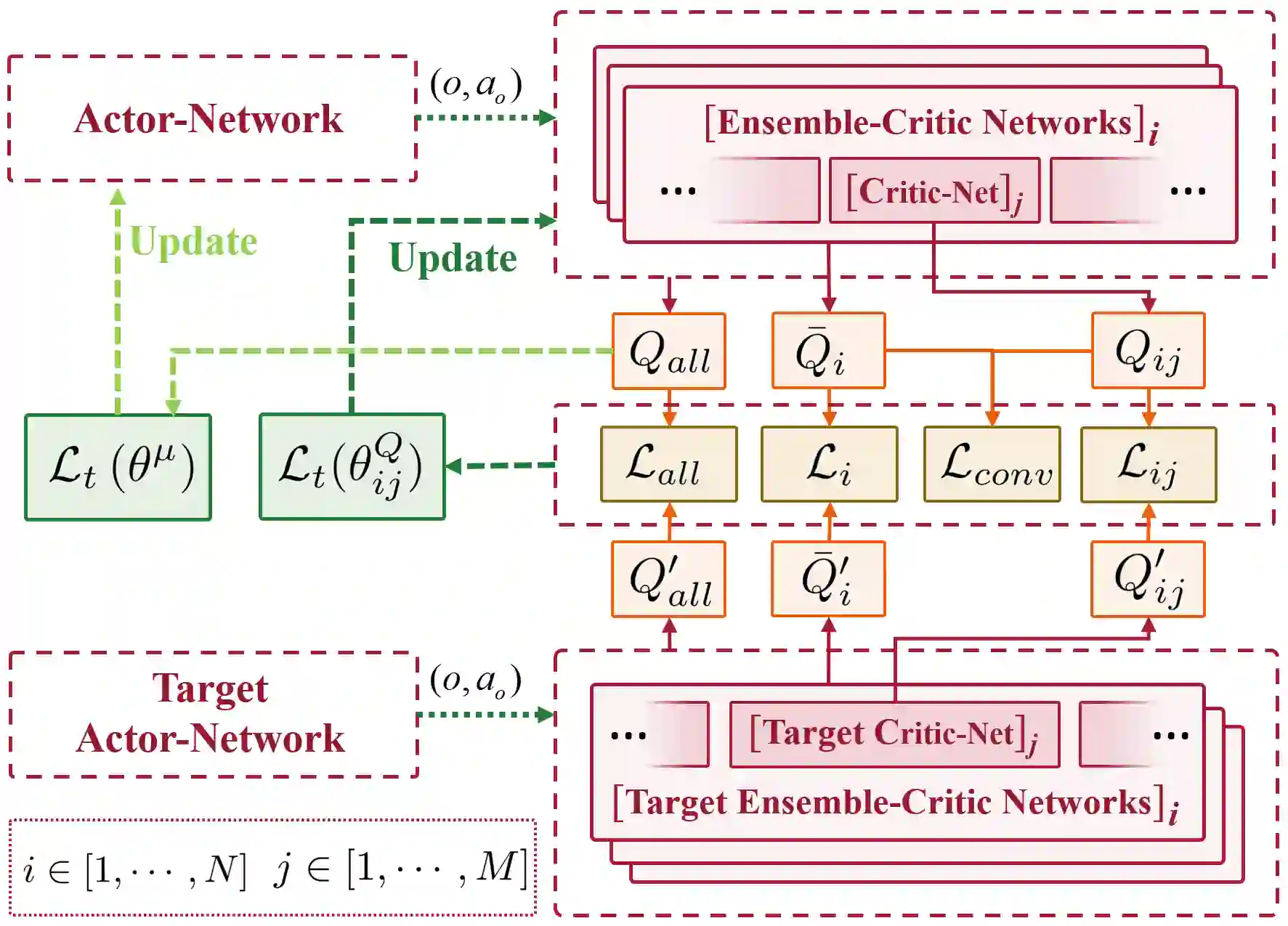
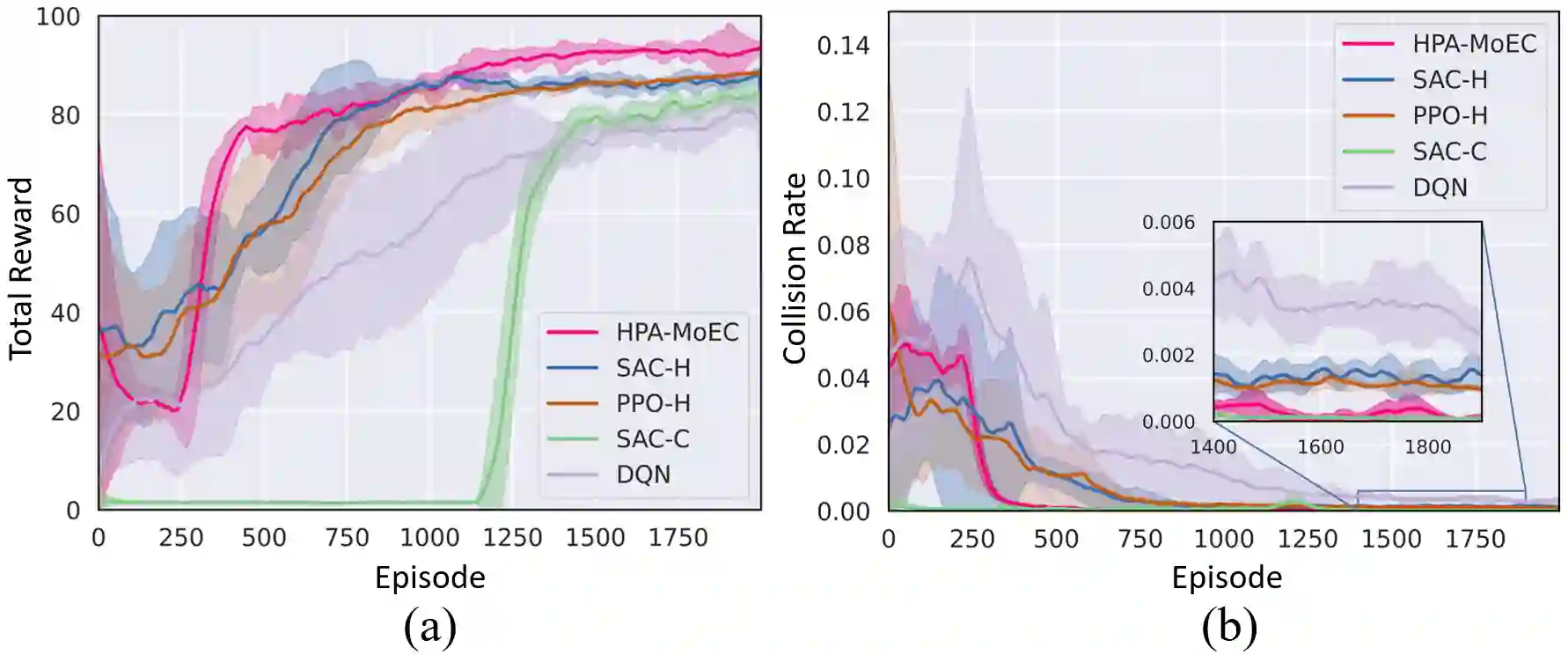
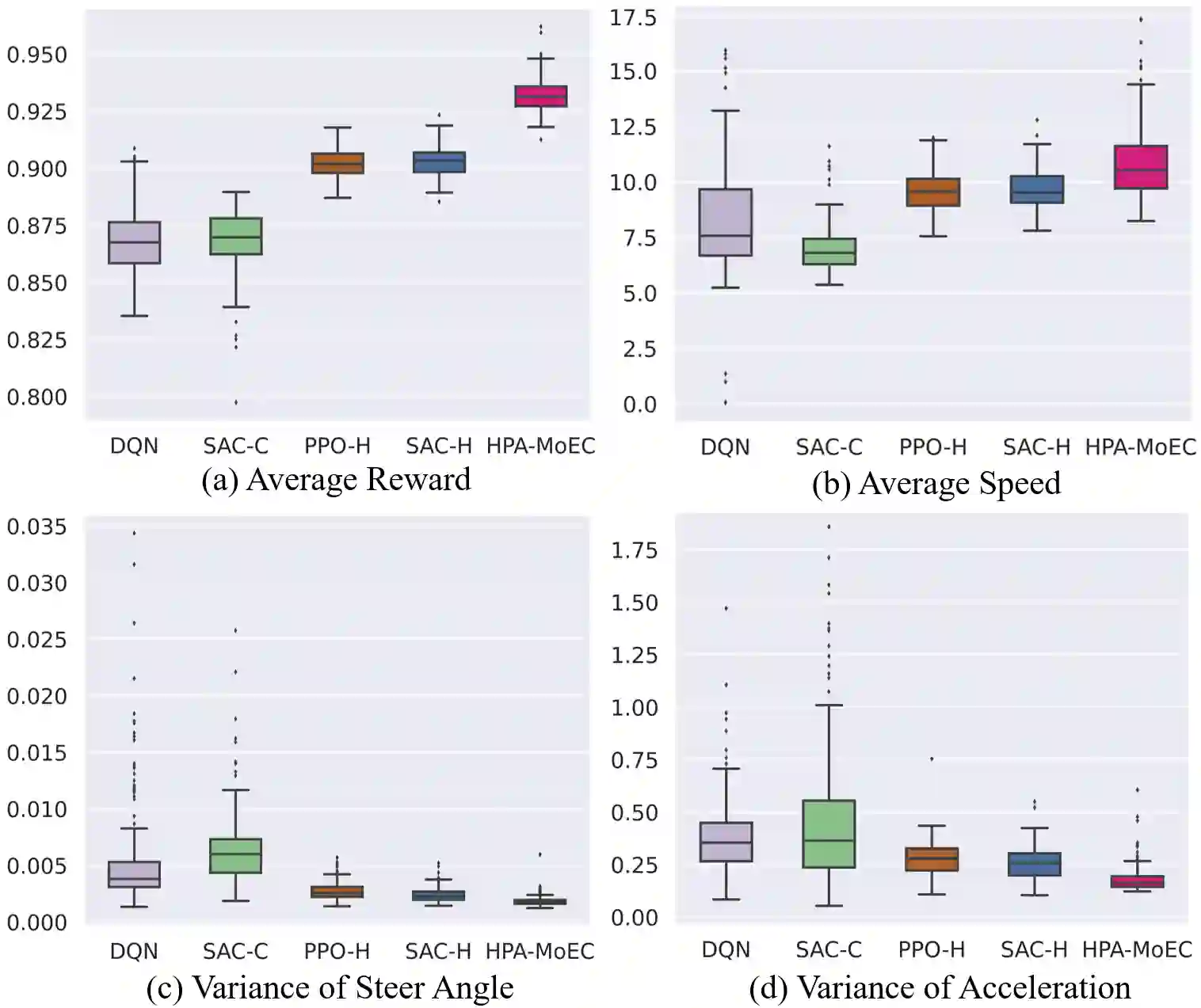
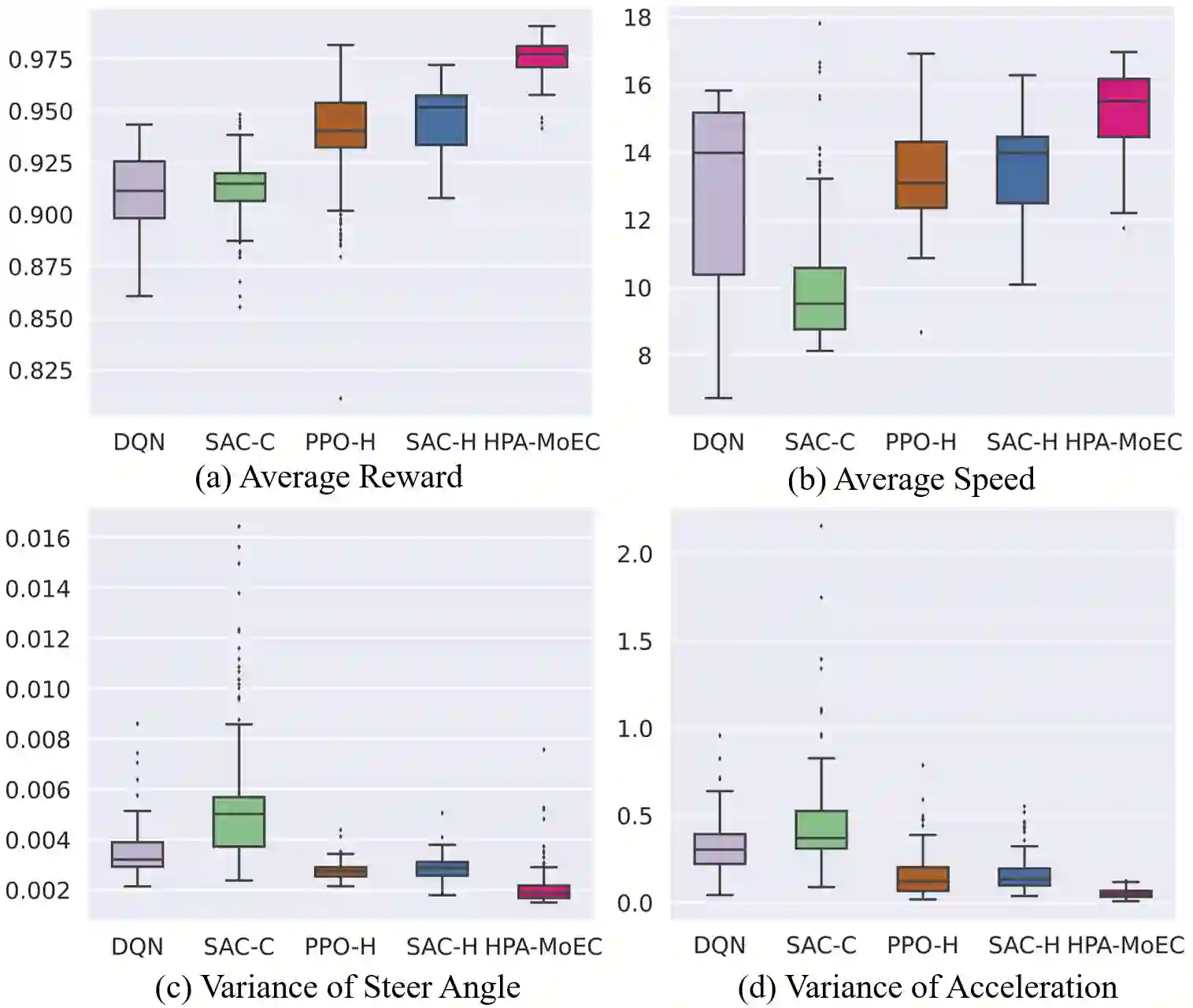
Reinforcement Learning (RL) has shown excellent performance in solving decision-making and control problems of autonomous driving, which is increasingly applied in diverse driving scenarios. However, driving is a multi-attribute problem, leading to challenges in achieving multi-objective compatibility for current RL methods, especially in both policy execution and policy iteration. On the one hand, the common action space structure with single action type limits driving flexibility or results in large behavior fluctuations during policy execution. On the other hand, the multi-attribute weighted single reward function result in the agent's disproportionate attention to certain objectives during policy iterations. To this end, we propose a Multi-objective Ensemble-Critic reinforcement learning method with Hybrid Parametrized Action for multi-objective compatible autonomous driving. Specifically, a parameterized action space is constructed to generate hybrid driving actions, combining both abstract guidance and concrete control commands. A multi-objective critics architecture is constructed considering multiple attribute rewards, to ensure simultaneously focusing on different driving objectives. Additionally, uncertainty-based exploration strategy is introduced to help the agent faster approach viable driving policy. The experimental results in both the simulated traffic environment and the HighD dataset demonstrate that our method can achieve multi-objective compatible autonomous driving in terms of driving efficiency, action consistency, and safety. It enhances the general performance of the driving while significantly increasing training efficiency.
翻译:强化学习(Reinforcement Learning, RL)在解决自动驾驶的决策与控制问题上展现出卓越性能,并日益广泛地应用于多样化的驾驶场景。然而,驾驶是一个多属性问题,这导致当前RL方法在实现多目标兼容性方面面临挑战,尤其在策略执行与策略迭代两个层面。一方面,采用单一动作类型的常见动作空间结构限制了驾驶的灵活性,或在策略执行过程中导致较大的行为波动。另一方面,基于多属性加权构建的单一奖励函数,使得智能体在策略迭代过程中对某些目标关注失衡。为此,我们提出一种采用混合参数化动作的多目标集成-评论家强化学习方法,用于实现多目标兼容的自动驾驶。具体而言,该方法构建了一个参数化动作空间以生成混合驾驶动作,结合了抽象引导指令与具体控制命令;构建了一个考虑多属性奖励的多目标评论家架构,以确保同时关注不同的驾驶目标。此外,引入了基于不确定性的探索策略,以帮助智能体更快地逼近可行的驾驶策略。在模拟交通环境及HighD数据集上的实验结果表明,所提方法在驾驶效率、动作一致性与安全性方面均能实现多目标兼容的自动驾驶,在提升驾驶综合性能的同时,显著提高了训练效率。