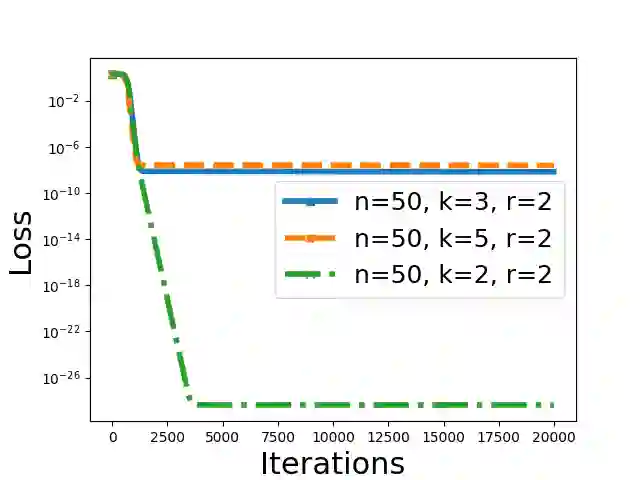
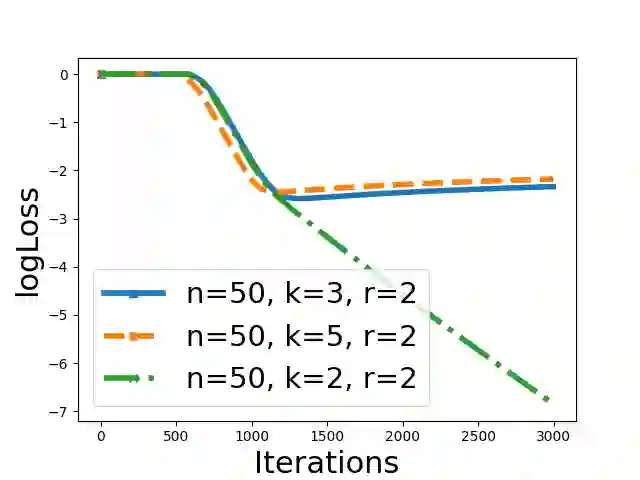
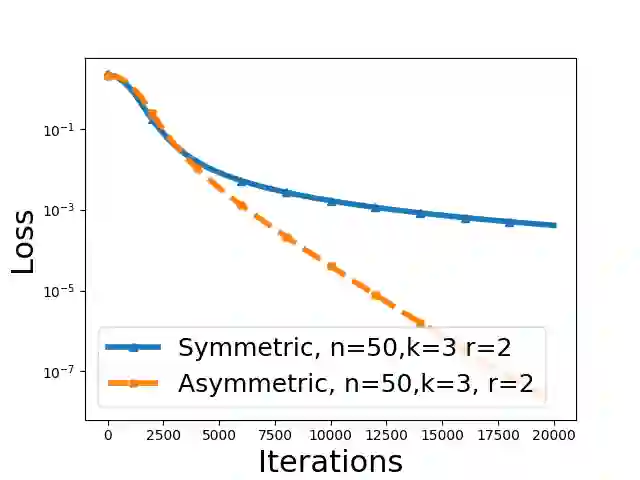
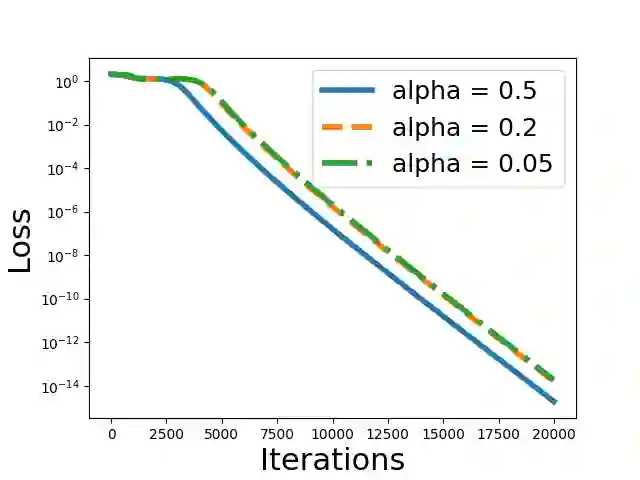
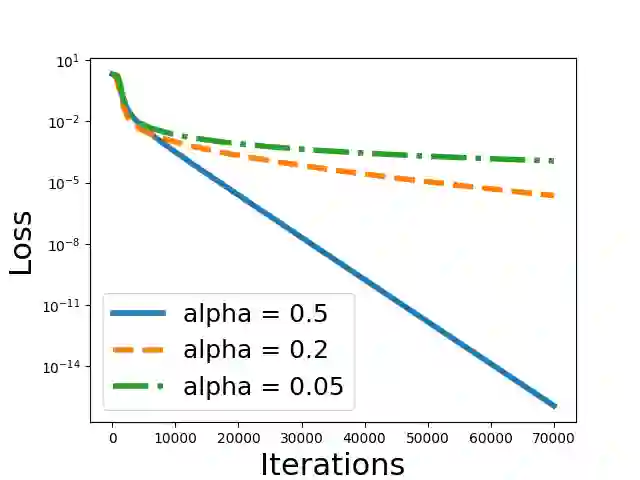
This paper rigorously shows how over-parameterization changes the convergence behaviors of gradient descent (GD) for the matrix sensing problem, where the goal is to recover an unknown low-rank ground-truth matrix from near-isotropic linear measurements. First, we consider the symmetric setting with the symmetric parameterization where $M^* \in \mathbb{R}^{n \times n}$ is a positive semi-definite unknown matrix of rank $r \ll n$, and one uses a symmetric parameterization $XX^\top$ to learn $M^*$. Here $X \in \mathbb{R}^{n \times k}$ with $k > r$ is the factor matrix. We give a novel $\Omega (1/T^2)$ lower bound of randomly initialized GD for the over-parameterized case ($k >r$) where $T$ is the number of iterations. This is in stark contrast to the exact-parameterization scenario ($k=r$) where the convergence rate is $\exp (-\Omega (T))$. Next, we study asymmetric setting where $M^* \in \mathbb{R}^{n_1 \times n_2}$ is the unknown matrix of rank $r \ll \min\{n_1,n_2\}$, and one uses an asymmetric parameterization $FG^\top$ to learn $M^*$ where $F \in \mathbb{R}^{n_1 \times k}$ and $G \in \mathbb{R}^{n_2 \times k}$. Building on prior work, we give a global exact convergence result of randomly initialized GD for the exact-parameterization case ($k=r$) with an $\exp (-\Omega(T))$ rate. Furthermore, we give the first global exact convergence result for the over-parameterization case ($k>r$) with an $\exp(-\Omega(\alpha^2 T))$ rate where $\alpha$ is the initialization scale. This linear convergence result in the over-parameterization case is especially significant because one can apply the asymmetric parameterization to the symmetric setting to speed up from $\Omega (1/T^2)$ to linear convergence. On the other hand, we propose a novel method that only modifies one step of GD and obtains a convergence rate independent of $\alpha$, recovering the rate in the exact-parameterization case.
翻译:本文严格论证了过度参数化如何改变梯度下降(GD)在矩阵感知问题中的收敛行为,该问题的目标是从近各向同性线性测量中恢复未知的低秩真实矩阵。首先,我们考虑对称参数化下的对称情形:设$M^* \in \mathbb{R}^{n \times n}$为秩$r \ll n$的半正定未知矩阵,通过对称参数化$XX^\top$学习$M^*$,其中$X \in \mathbb{R}^{n \times k}$且$k > r$为因子矩阵。我们给出了随机初始化GD在过度参数化情形($k>r$)中新颖的$\Omega (1/T^2)$下界($T$为迭代次数)。这与精确参数化情形($k=r$)下$\exp (-\Omega (T))$的收敛速率形成鲜明对比。其次,我们研究非对称情形:设$M^* \in \mathbb{R}^{n_1 \times n_2}$为秩$r \ll \min\{n_1,n_2\}$的未知矩阵,通过非对称参数化$FG^\top$学习$M^*$,其中$F \in \mathbb{R}^{n_1 \times k}$,$G \in \mathbb{R}^{n_2 \times k}$。基于先前工作,我们给出了精确参数化情形($k=r$)下随机初始化GD的全局精确收敛结果,收敛速率为$\exp (-\Omega(T))$。进一步,我们首次建立了过度参数化情形($k>r$)下以$\exp(-\Omega(\alpha^2 T))$速率($\alpha$为初始化尺度)的全局精确收敛结果。该线性收敛结果在过度参数化情形中尤为重要,因为可将非对称参数化应用于对称情形,将收敛速度从$\Omega (1/T^2)$提升至线性收敛。另一方面,我们提出仅修改GD一步的新方法,获得与$\alpha$无关的收敛速率,恢复精确参数化情形的速率。