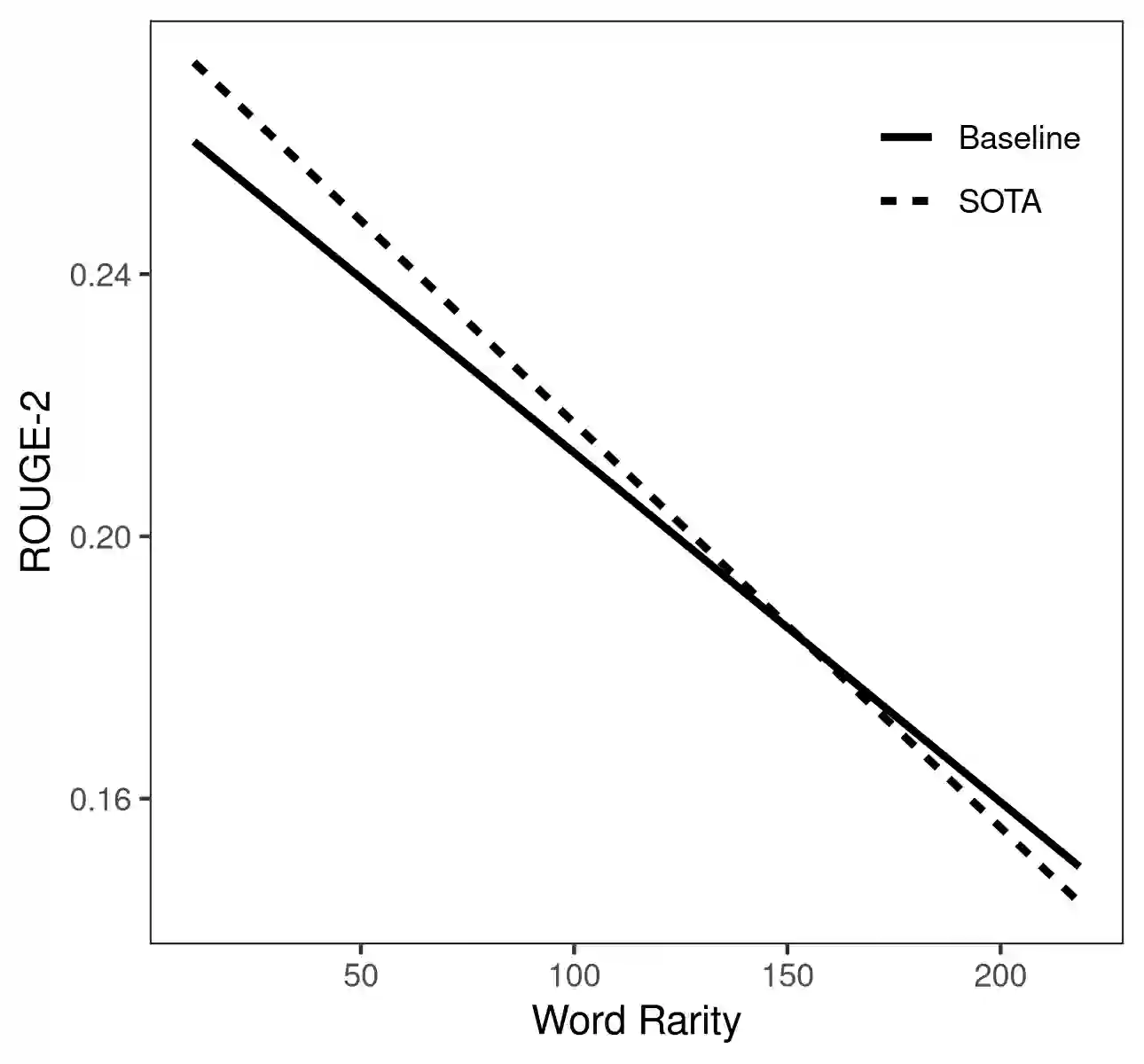
Reliability of machine learning evaluation -- the consistency of observed evaluation scores across replicated model training runs -- is affected by several sources of nondeterminism which can be regarded as measurement noise. Current tendencies to remove noise in order to enforce reproducibility of research results neglect inherent nondeterminism at the implementation level and disregard crucial interaction effects between algorithmic noise factors and data properties. This limits the scope of conclusions that can be drawn from such experiments. Instead of removing noise, we propose to incorporate several sources of variance, including their interaction with data properties, into an analysis of significance and reliability of machine learning evaluation, with the aim to draw inferences beyond particular instances of trained models. We show how to use linear mixed effects models (LMEMs) to analyze performance evaluation scores, and to conduct statistical inference with a generalized likelihood ratio test (GLRT). This allows us to incorporate arbitrary sources of noise like meta-parameter variations into statistical significance testing, and to assess performance differences conditional on data properties. Furthermore, a variance component analysis (VCA) enables the analysis of the contribution of noise sources to overall variance and the computation of a reliability coefficient by the ratio of substantial to total variance.
翻译:机器学习评估的可靠性——即跨重复模型训练运行中观测到的评估分数的一致性——受到可视为测量噪声的多种非确定性来源的影响。当前倾向于通过消除噪声来强制研究结果可重复性的趋势,忽视了实现层面固有的非确定性,并忽略了算法噪声因素与数据属性之间的关键交互效应。这限制了从此类实验中得出的结论范围。我们提议不消除噪声,而是将包括与数据属性交互作用在内的多种方差来源纳入机器学习评估的显著性与可靠性分析中,旨在超越特定训练模型实例进行推理。我们展示了如何利用线性混合效应模型(LMEMs)分析性能评估分数,并通过广义似然比检验(GLRT)进行统计推断。这使得我们能够将元参数变化等任意噪声来源纳入统计显著性检验,并评估条件于数据属性的性能差异。此外,方差分量分析(VCA)能够分析噪声来源对总体方差的贡献,并通过实质方差与总方差的比率计算可靠性系数。