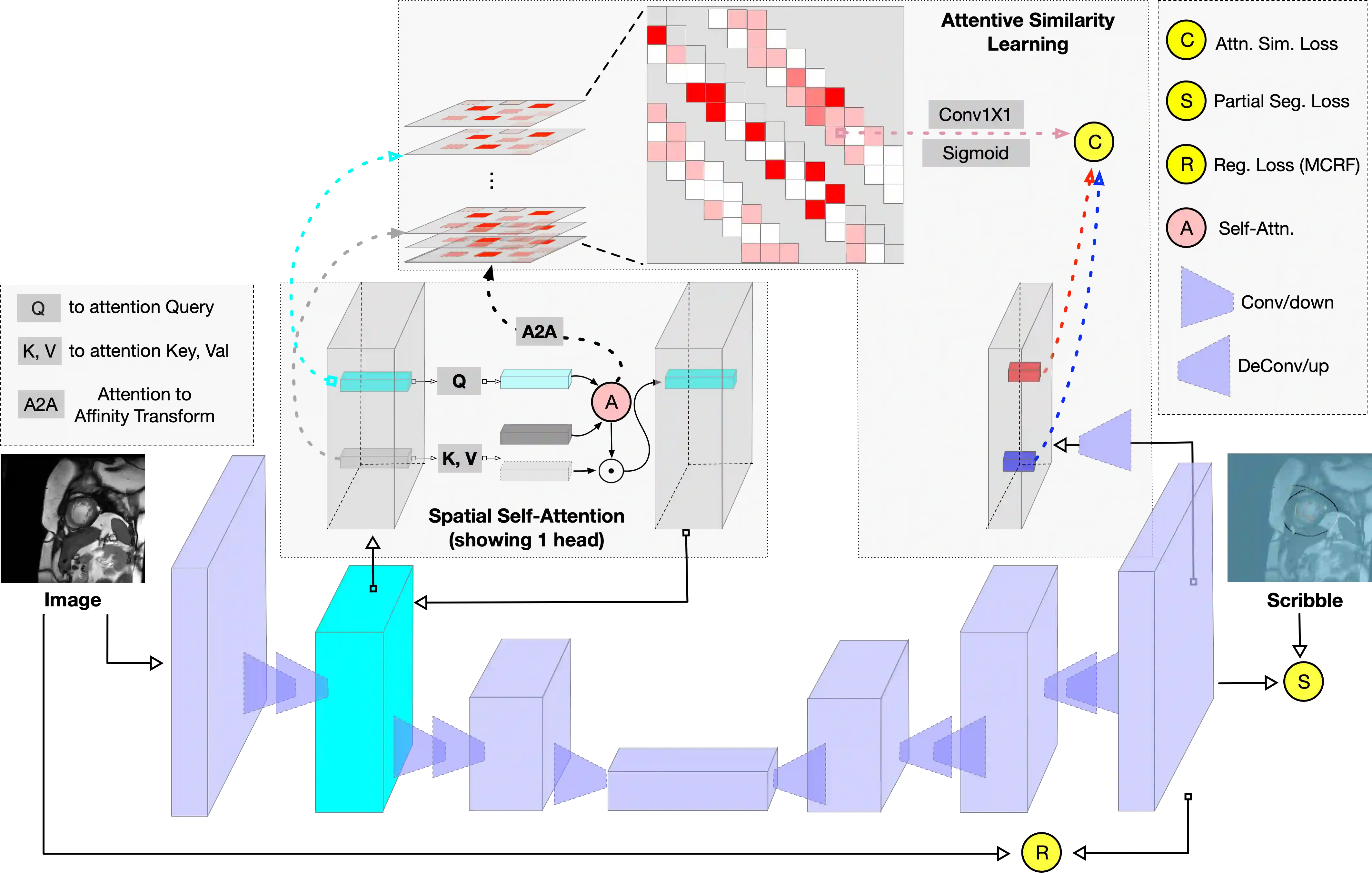
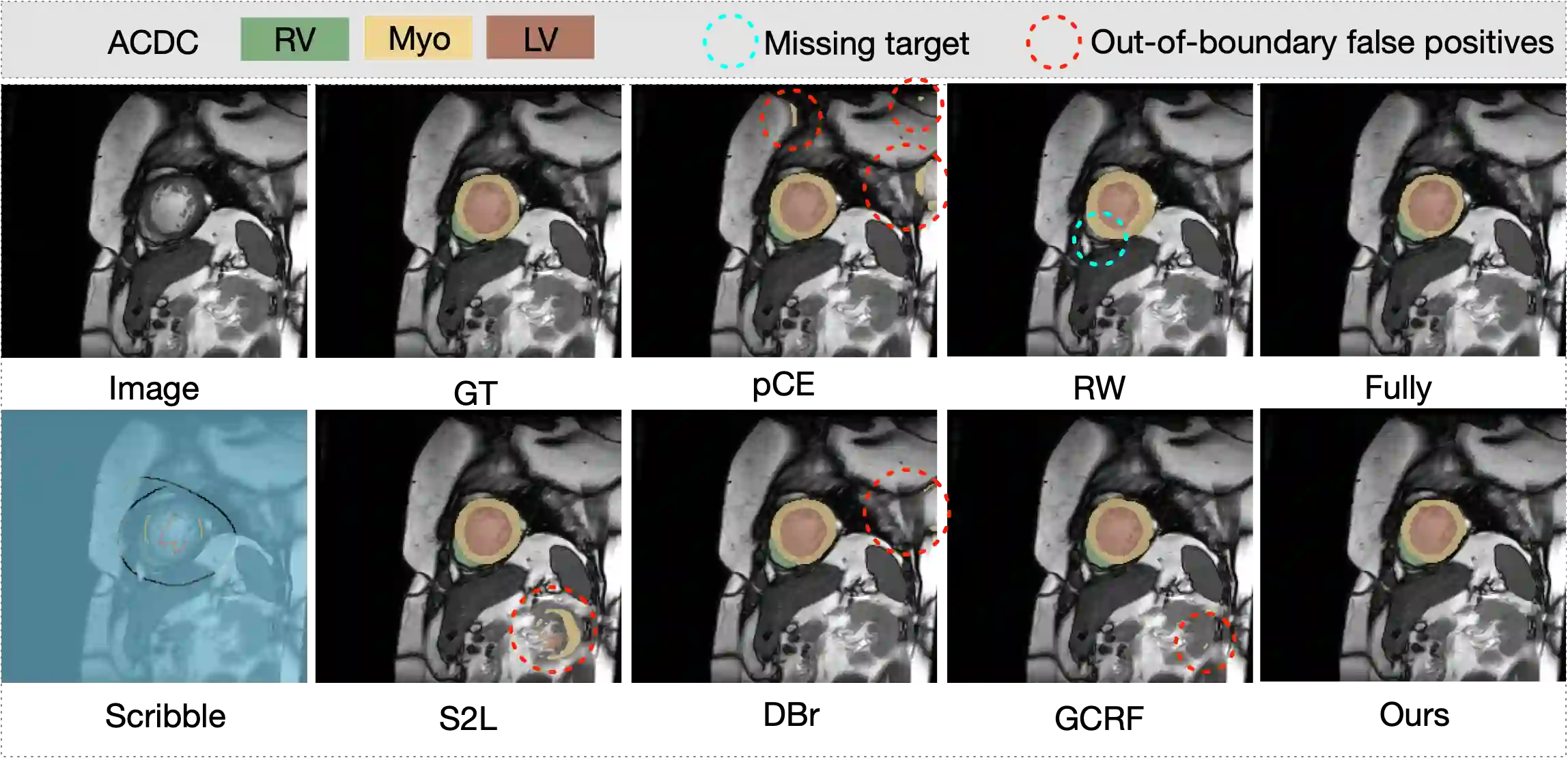
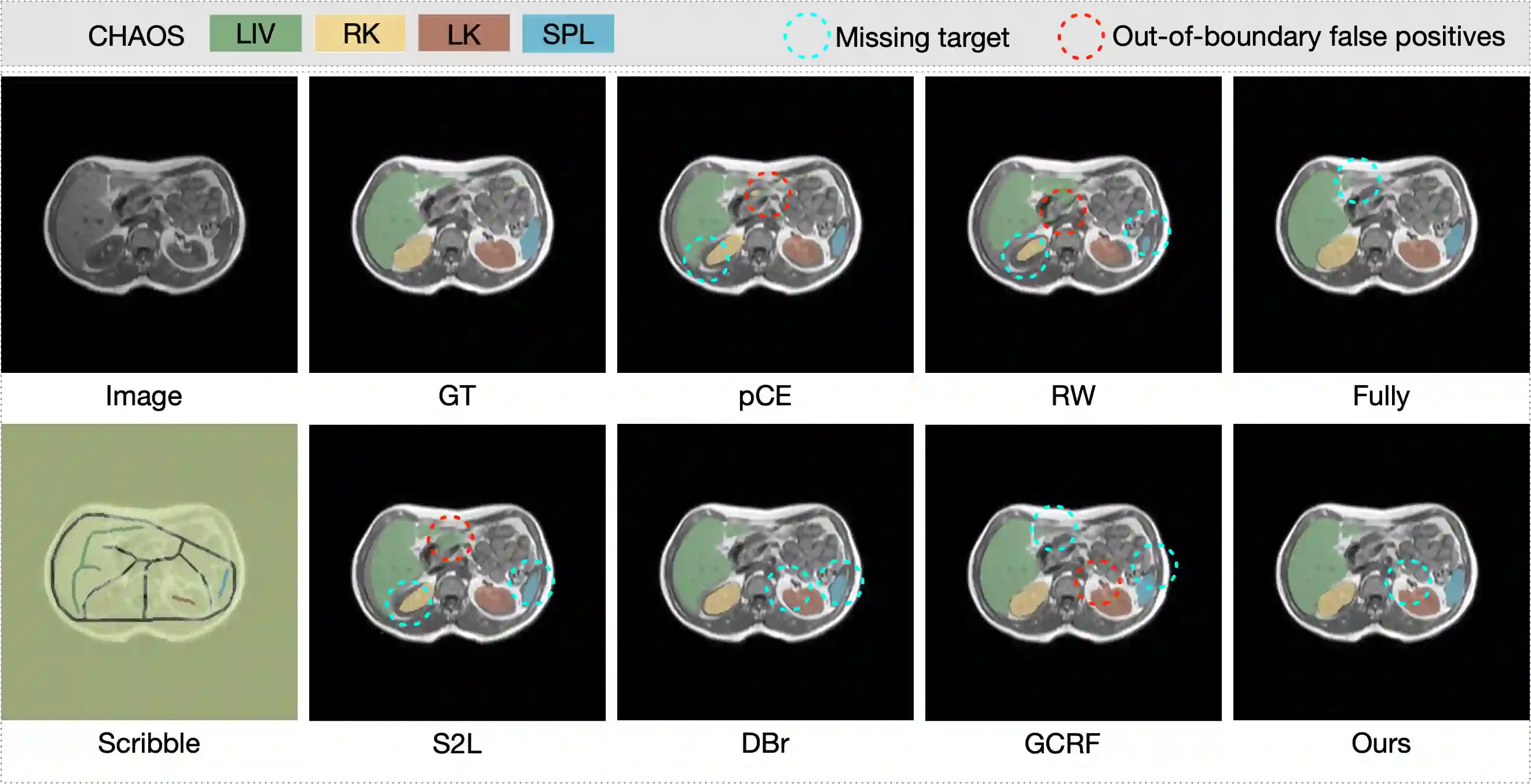
The success of deep networks in medical image segmentation relies heavily on massive labeled training data. However, acquiring dense annotations is a time-consuming process. Weakly-supervised methods normally employ less expensive forms of supervision, among which scribbles started to gain popularity lately thanks to its flexibility. However, due to lack of shape and boundary information, it is extremely challenging to train a deep network on scribbles that generalizes on unlabeled pixels. In this paper, we present a straightforward yet effective scribble supervised learning framework. Inspired by recent advances of transformer based segmentation, we create a pluggable spatial self-attention module which could be attached on top of any internal feature layers of arbitrary fully convolutional network (FCN) backbone. The module infuses global interaction while keeping the efficiency of convolutions. Descended from this module, we construct a similarity metric based on normalized and symmetrized attention. This attentive similarity leads to a novel regularization loss that imposes consistency between segmentation prediction and visual affinity. This attentive similarity loss optimizes the alignment of FCN encoders, attention mapping and model prediction. Ultimately, the proposed FCN+Attention architecture can be trained end-to-end guided by a combination of three learning objectives: partial segmentation loss, a customized masked conditional random fields and the proposed attentive similarity loss. Extensive experiments on public datasets (ACDC and CHAOS) showed that our framework not just out-performs existing state-of-the-art, but also delivers close performance to fully-supervised benchmark. Code will be available upon publication.
翻译:深度网络在医学图像分割中的成功高度依赖于大规模的标注训练数据。然而,获取密集标注是一个耗时过程。弱监督方法通常采用成本较低的监督形式,其中涂鸦标注因其灵活性近年逐渐受到青睐。但由于缺乏形状和边界信息,在涂鸦标注上训练的深度网络难以在未标注像素上实现良好泛化。本文提出一种简洁有效的涂鸦监督学习框架。受近期基于Transformer的分割技术启发,我们构建了一个可插拔的空间自注意力模块,可附着于任意全卷积网络(FCN)骨干的内部特征层上。该模块在保持卷积高效性的同时注入全局交互信息。基于该模块,我们提出一种归一化对称化注意力相似度度量。这种注意力相似性导出一种新型正则化损失,强制分割预测与视觉亲和度之间的一致性。该注意力相似性损失优化了FCN编码器、注意力映射与模型预测的对齐。最终,提出的FCN+注意力架构可端到端训练,由三种学习目标联合指导:局部分割损失、定制化掩码条件随机场以及所提出的注意力相似性损失。在公开数据集(ACDC和CHAOS)上的大量实验表明,我们的框架不仅超越现有最佳方法,而且性能接近全监督基准方法。代码将在发表后公开。