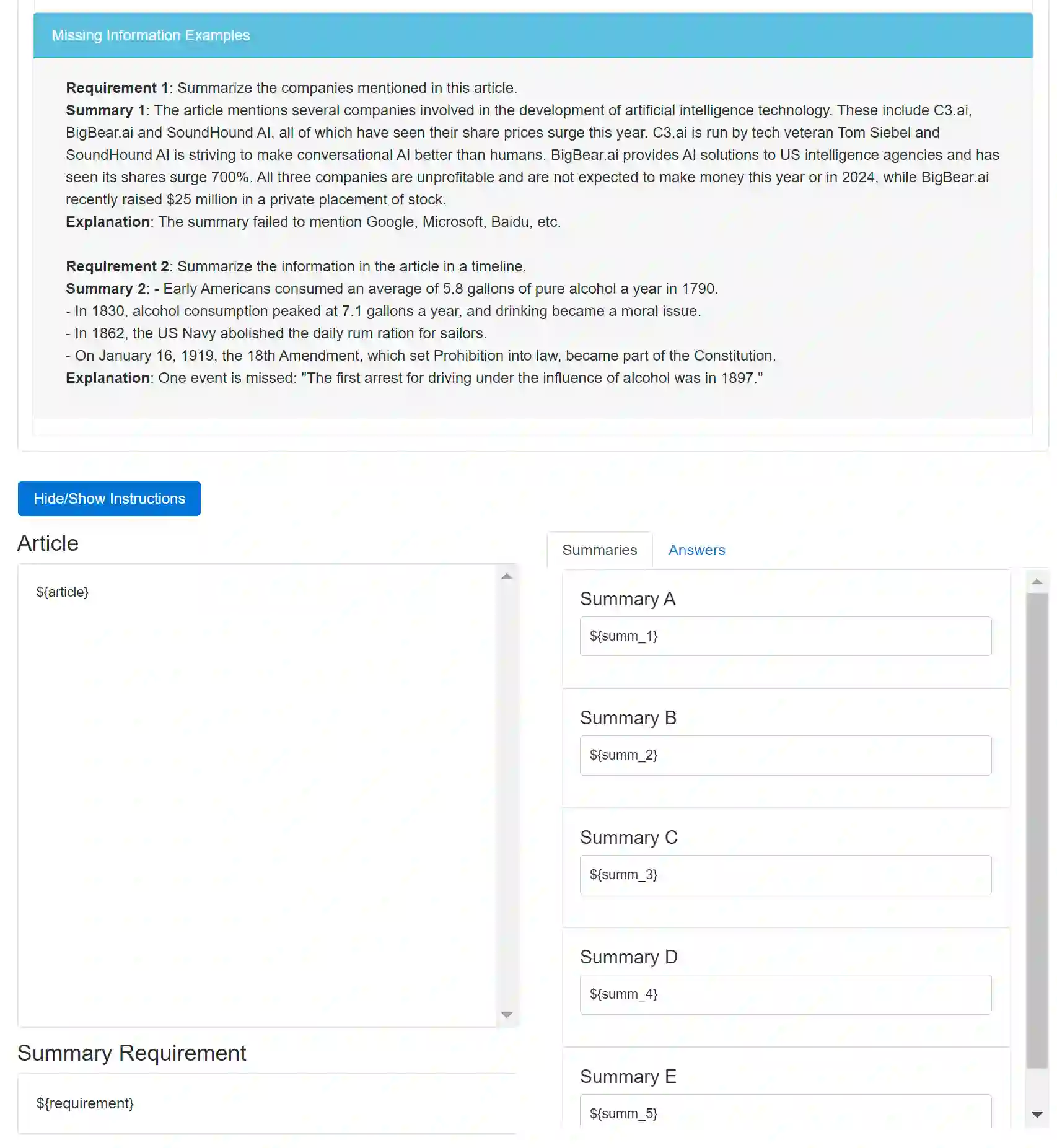
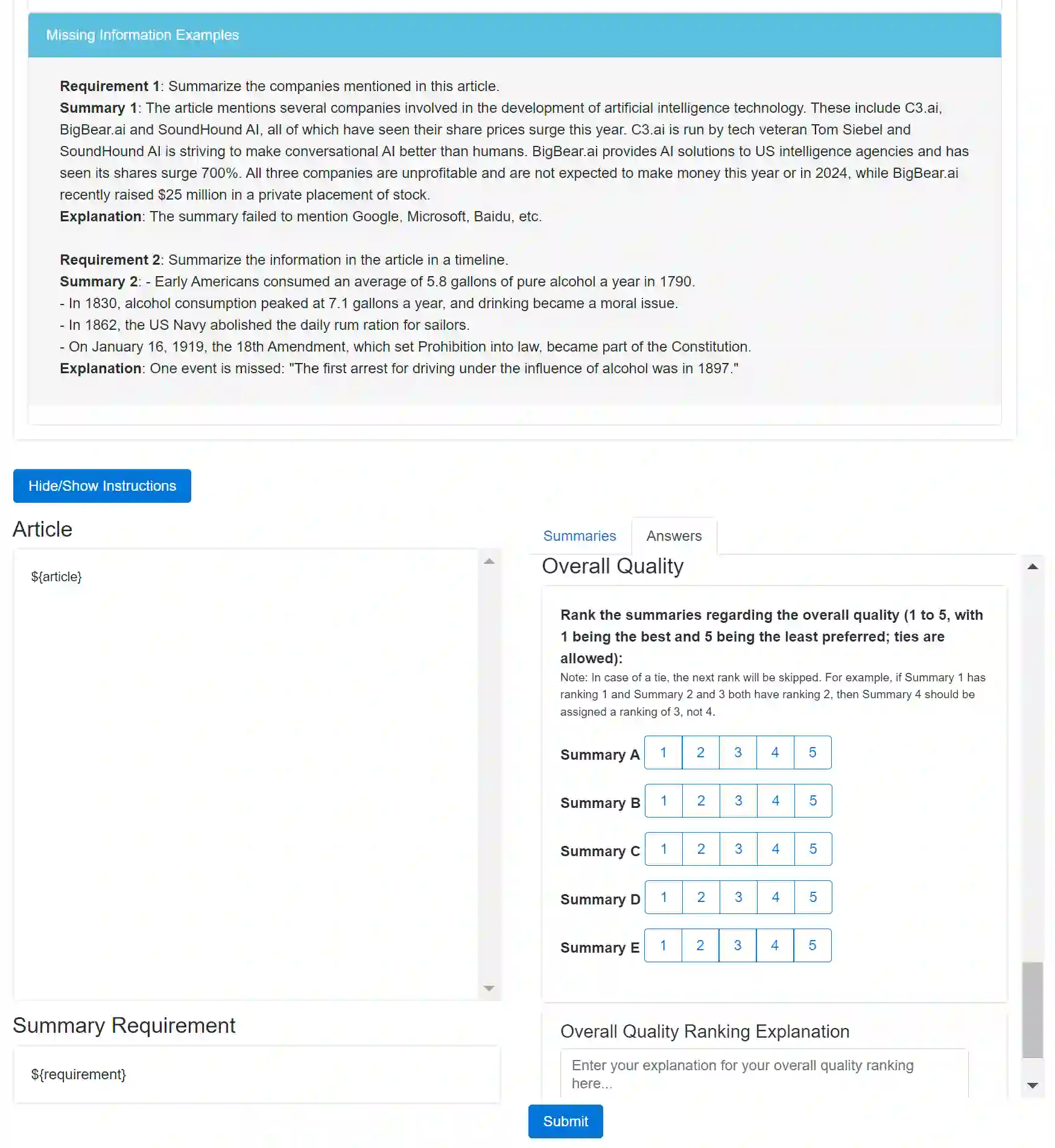
While large language models (LLMs) already achieve strong performance on standard generic summarization benchmarks, their performance on more complex summarization task settings is less studied. Therefore, we benchmark LLMs on instruction controllable text summarization, where the model input consists of both a source article and a natural language requirement for the desired summary characteristics. To this end, we curate an evaluation-only dataset for this task setting and conduct human evaluation on 5 LLM-based summarization systems. We then benchmark LLM-based automatic evaluation for this task with 4 different evaluation protocols and 11 LLMs, resulting in 40 evaluation methods in total. Our study reveals that instruction controllable text summarization remains a challenging task for LLMs, since (1) all LLMs evaluated still make factual and other types of errors in their summaries; (2) all LLM-based evaluation methods cannot achieve a strong alignment with human annotators when judging the quality of candidate summaries; (3) different LLMs show large performance gaps in summary generation and evaluation. We make our collected benchmark, InstruSum, publicly available to facilitate future research in this direction.
翻译:尽管大型语言模型(LLMs)已在标准通用摘要基准上展现出强大性能,但它们在更复杂摘要任务场景中的表现仍缺乏研究。为此,我们针对指令可控文本摘要任务对LLMs进行基准测试——该任务中模型输入同时包含源文章和对目标摘要特征的自然语言要求。我们为这一任务场景构建了仅含评估数据的专用数据集,并对5个基于LLM的摘要系统开展了人工评估。随后,我们采用4种不同评估协议与11个LLM,系统性地对基于LLM的自动评估方法进行基准测试,共计形成40种评估方法。研究表明,指令可控文本摘要对LLMs仍是具有挑战性的任务,因为:(1)所有被评估的LLM生成的摘要仍存在事实性及其他类型错误;(2)所有基于LLM的评估方法在判断候选摘要质量时均无法与人工标注达成高度一致;(3)不同LLM在摘要生成与评估能力上存在显著差距。我们公开共享所构建的基准数据集InstruSum,以推动该方向的后续研究。