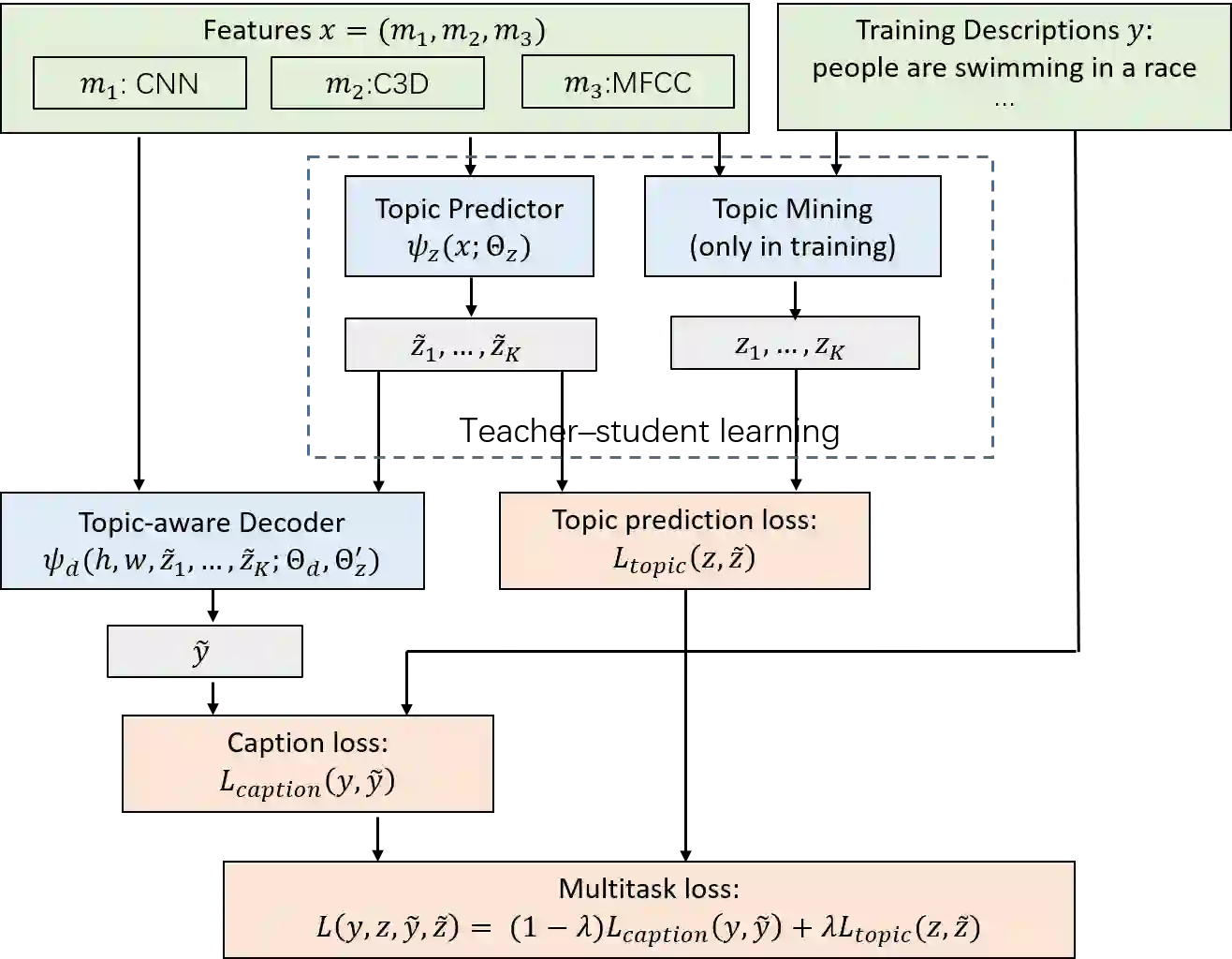
The topic diversity of open-domain videos leads to various vocabularies and linguistic expressions in describing video contents, and therefore, makes the video captioning task even more challenging. In this paper, we propose an unified caption framework, M&M TGM, which mines multimodal topics in unsupervised fashion from data and guides the caption decoder with these topics. Compared to pre-defined topics, the mined multimodal topics are more semantically and visually coherent and can reflect the topic distribution of videos better. We formulate the topic-aware caption generation as a multi-task learning problem, in which we add a parallel task, topic prediction, in addition to the caption task. For the topic prediction task, we use the mined topics as the teacher to train a student topic prediction model, which learns to predict the latent topics from multimodal contents of videos. The topic prediction provides intermediate supervision to the learning process. As for the caption task, we propose a novel topic-aware decoder to generate more accurate and detailed video descriptions with the guidance from latent topics. The entire learning procedure is end-to-end and it optimizes both tasks simultaneously. The results from extensive experiments conducted on the MSR-VTT and Youtube2Text datasets demonstrate the effectiveness of our proposed model. M&M TGM not only outperforms prior state-of-the-art methods on multiple evaluation metrics and on both benchmark datasets, but also achieves better generalization ability.
翻译:开放域视频的主题多样性导致描述视频内容时词汇和语言表达的多样化,这使得视频描述生成任务更具挑战性。本文提出统一描述框架M&M TGM,该框架以无监督方式从数据中挖掘多模态主题,并利用这些主题引导描述解码器。相较于预定义主题,挖掘的多模态主题在语义和视觉上具有更强的一致性,能更准确反映视频的主题分布。我们将主题感知的描述生成建模为多任务学习问题:在描述任务之外增设并行任务——主题预测。对于主题预测任务,以挖掘出的主题为教师信号训练学生主题预测模型,该模型学习从视频多模态内容中预测潜在主题,为学习过程提供中间监督。针对描述任务,我们提出新型主题感知解码器,利用潜在主题的引导生成更精确详尽的视频描述。整个学习过程采用端到端方式同时优化两个任务。在MSR-VTT和Youtube2Text数据集上的大量实验验证了模型有效性。M&M TGM不仅在多个评估指标和两个基准数据集上全面超越现有最优方法,还展现出更强的泛化能力。