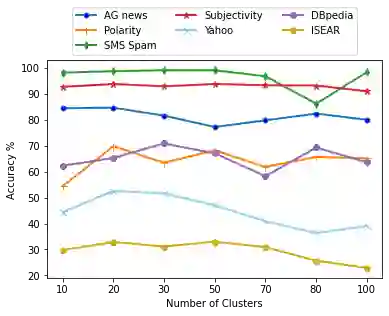
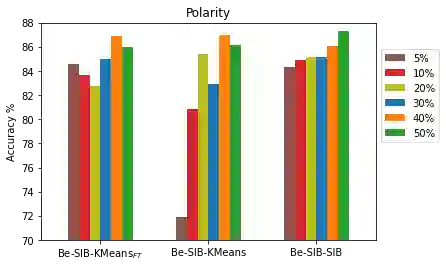
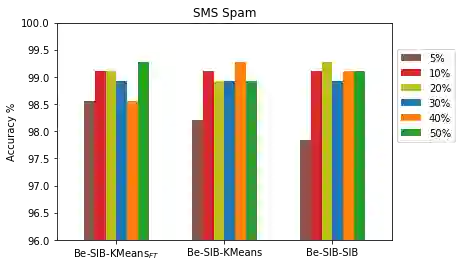
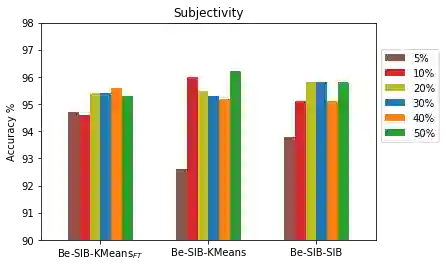
Language models such as Bidirectional Encoder Representations from Transformers (BERT) have been very effective in various Natural Language Processing (NLP) and text mining tasks including text classification. However, some tasks still pose challenges for these models, including text classification with limited labels. This can result in a cold-start problem. Although some approaches have attempted to address this problem through single-stage clustering as an intermediate training step coupled with a pre-trained language model, which generates pseudo-labels to improve classification, these methods are often error-prone due to the limitations of the clustering algorithms. To overcome this, we have developed a novel two-stage intermediate clustering with subsequent fine-tuning that models the pseudo-labels reliably, resulting in reduced prediction errors. The key novelty in our model, IDoFew, is that the two-stage clustering coupled with two different clustering algorithms helps exploit the advantages of the complementary algorithms that reduce the errors in generating reliable pseudo-labels for fine-tuning. Our approach has shown significant improvements compared to strong comparative models.
翻译:诸如双向编码器表示(BERT)等语言模型在包括文本分类在内的多种自然语言处理(NLP)和文本挖掘任务中已展现出显著效果。然而,部分任务仍对这些模型构成挑战,例如在标注样本有限条件下的文本分类问题,这可能导致冷启动困境。尽管已有研究尝试通过将单阶段聚类作为中间训练步骤与预训练语言模型相结合,生成伪标签以提升分类性能,但受限于聚类算法的固有缺陷,此类方法往往存在较高误差。为克服这一局限,我们提出了一种新颖的两阶段中间聚类方法,结合后续微调过程,能够可靠地建模伪标签,从而有效降低预测错误。IDoFew模型的关键创新在于:通过将两类不同聚类算法耦合的两阶段聚类策略,充分利用互补算法的优势,减少生成可靠伪标签过程中的误差,进而优化微调效果。与强对比模型相比,本方法取得了显著性能提升。