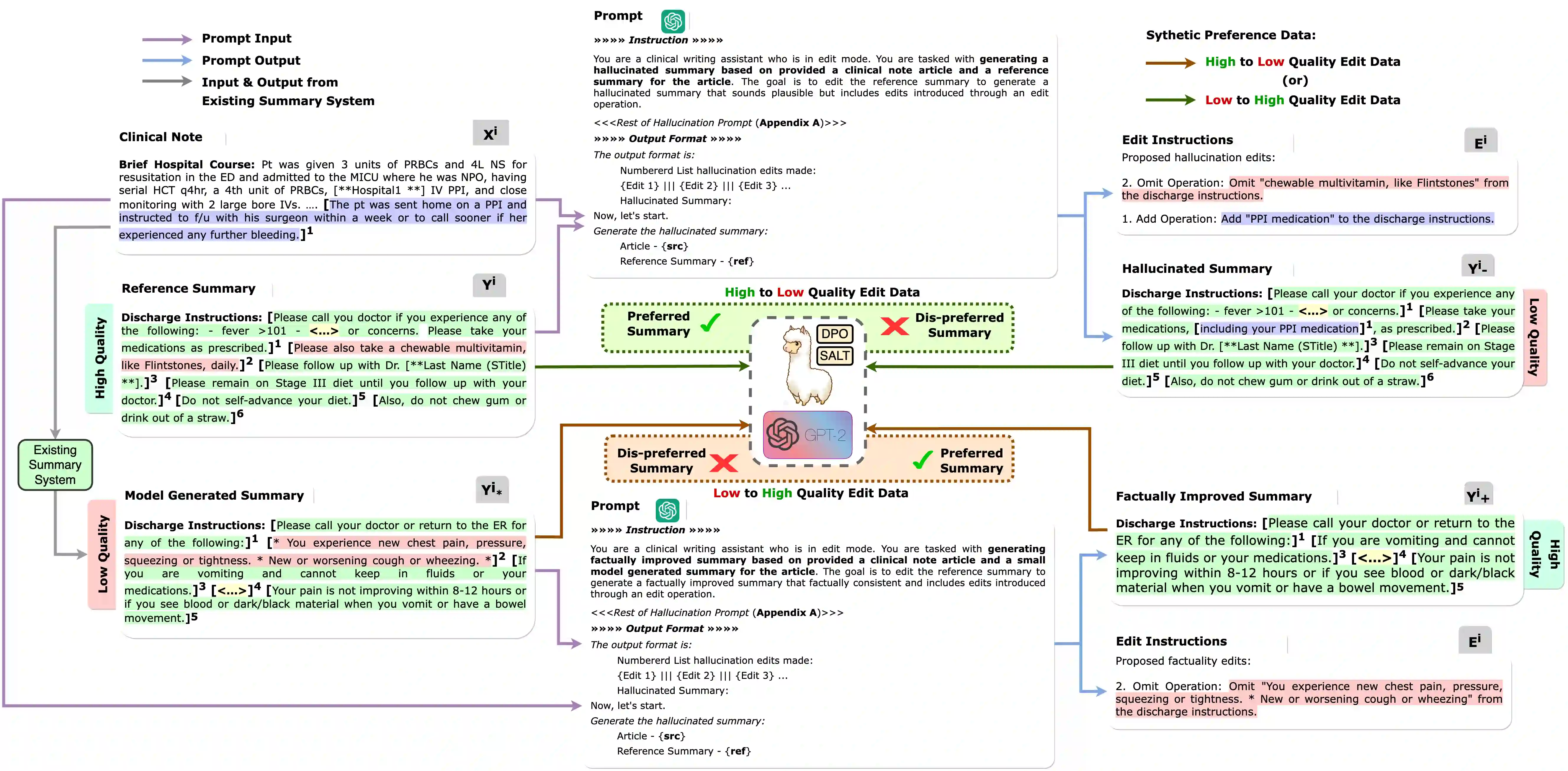
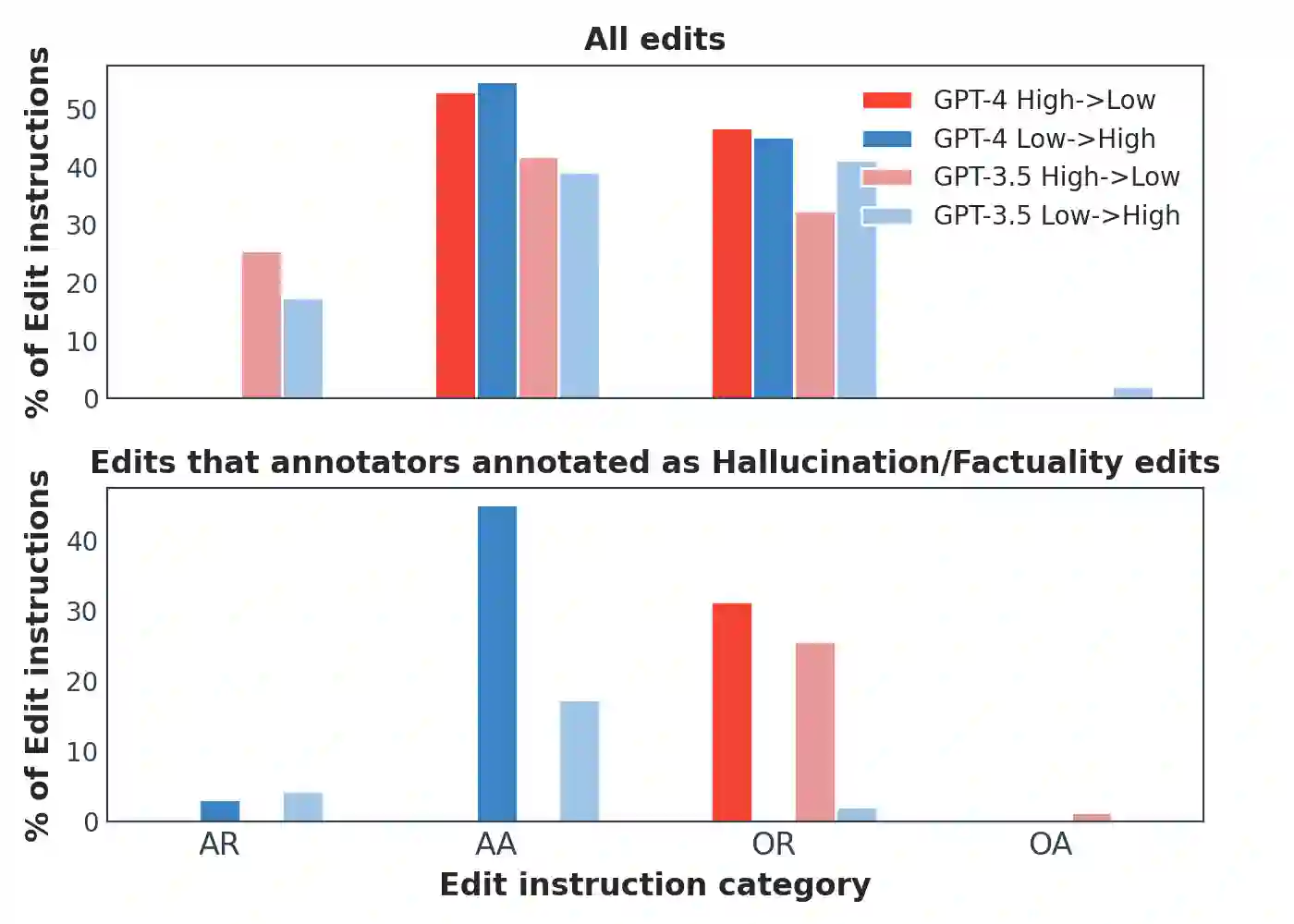
Large Language Models (LLMs) such as GPT and Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes GPT-3.5 and GPT-4 to generate high-quality feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback, mirroring the practical scenario in which medical professionals refine AI system outputs without the need for additional annotations. Despite GPT's proven expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on its capacity to deliver expert-level edit feedback for improving weaker LMs or LLMs generation quality. This work leverages GPT's advanced capabilities in clinical NLP to offer expert-level edit feedback. Through the use of two distinct alignment algorithms (DPO and SALT) based on GPT edit feedback, our goal is to reduce hallucinations and align closely with medical facts, endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of GPT edits in enhancing the alignment of clinical factuality.
翻译:GPT和Llama等大型语言模型在摘要任务中取得了显著成就,但在临床自然语言处理应用中面临事实不准确的严峻问题——这类错误可能引发严重后果。针对事实对齐任务中专家标注数据成本高昂且稀缺的挑战,本研究提出创新性流水线,利用GPT-3.5和GPT-4生成高质量反馈以增强临床病历总结的事实一致性。研究重点聚焦编辑反馈机制,模拟医疗专业人员无需额外标注即可优化人工智能系统输出的实际场景。尽管GPT在医学执照考试等临床自然语言处理任务中已展现专业能力,但目前鲜有研究探讨其能否提供专家级编辑反馈以提升弱语言模型或大型语言模型的生成质量。本研究充分发挥GPT在临床自然语言处理中的先进能力,提供专家级别的编辑反馈。通过基于GPT编辑反馈的两种不同对齐算法(DPO和SALT),旨在减少幻觉现象并紧密贴合医学事实,力求缩小人工智能生成内容与事实准确性之间的鸿沟。这凸显了GPT编辑在提升临床事实对齐方面的巨大潜力。