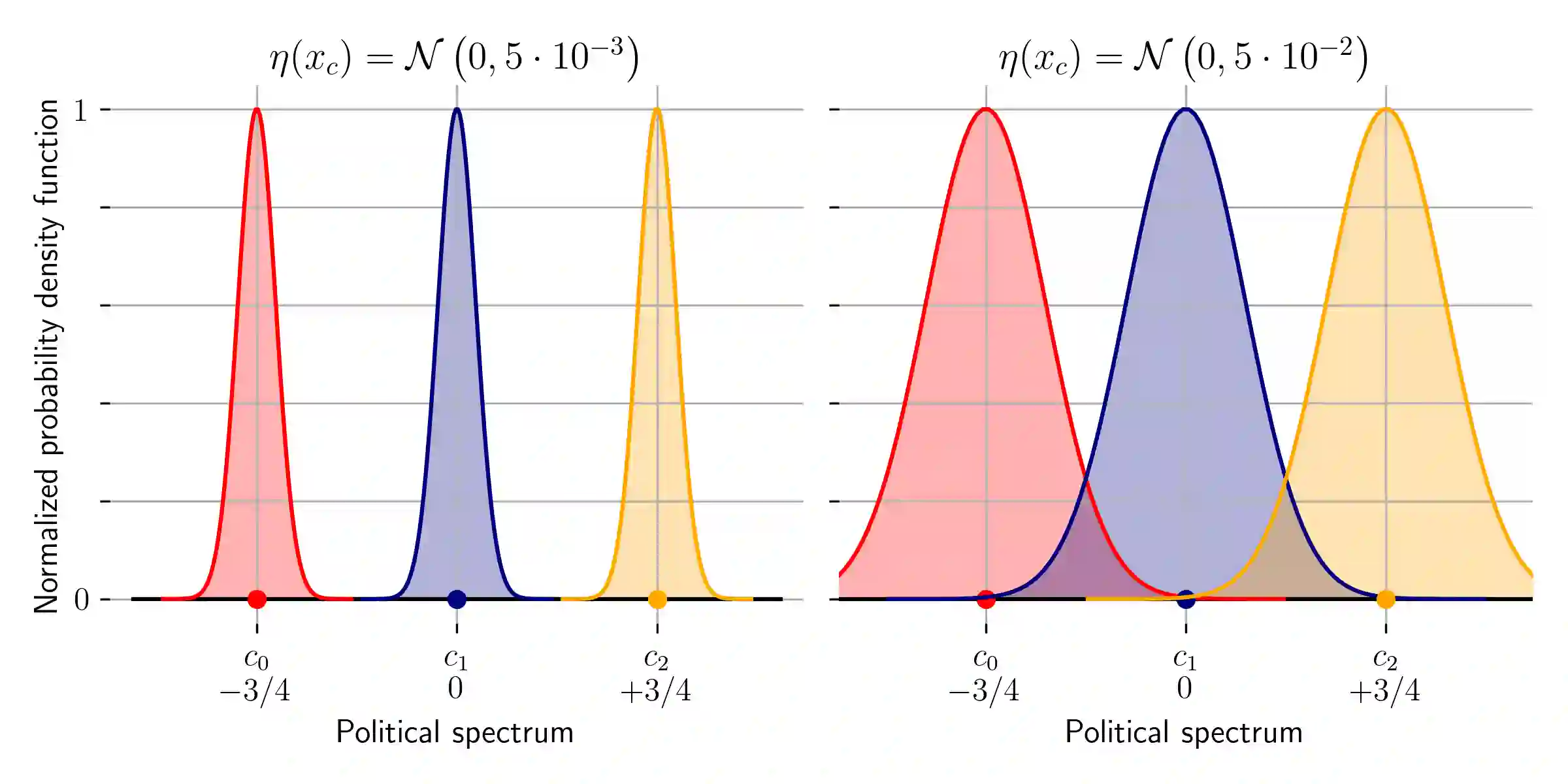
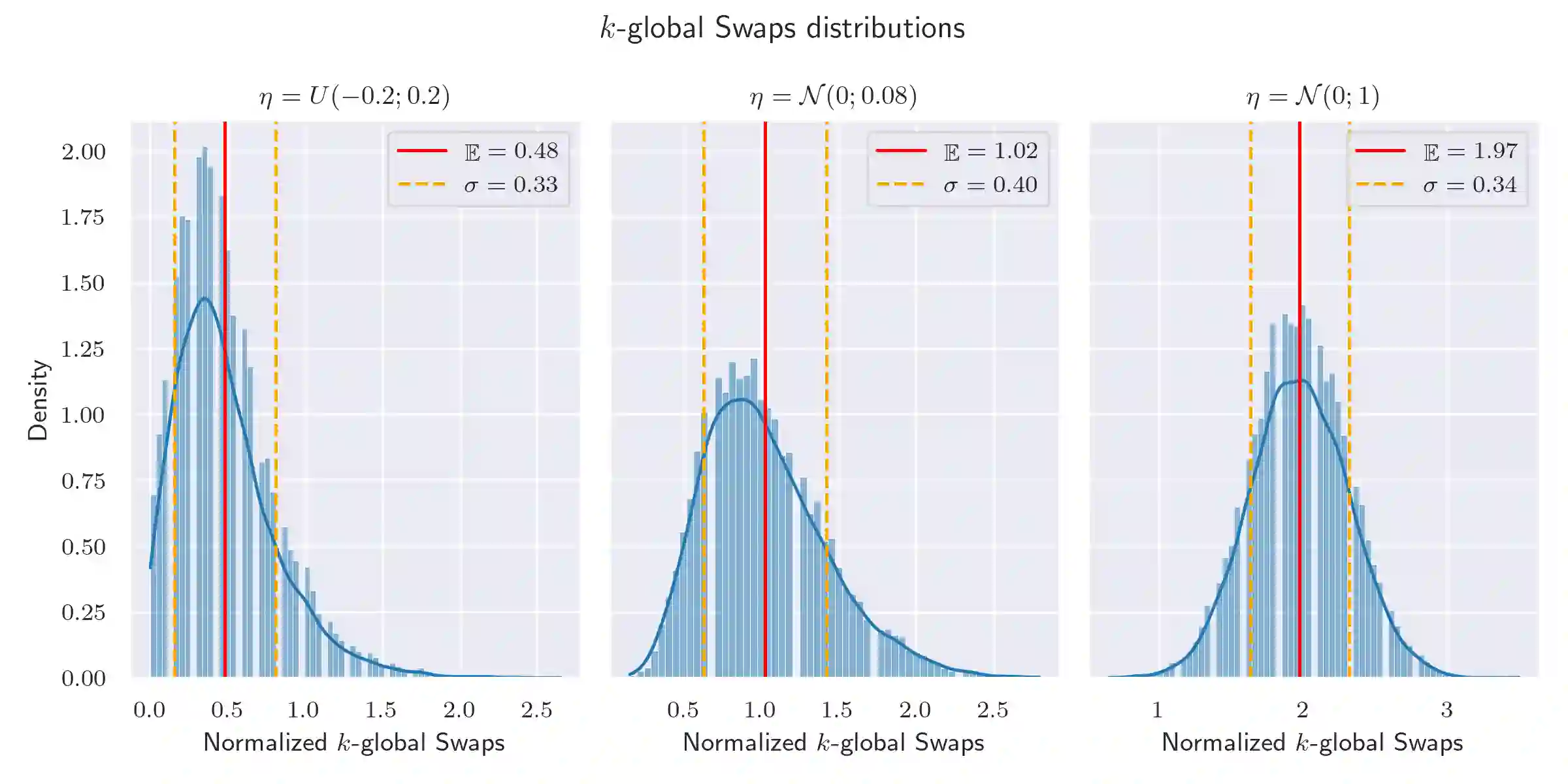
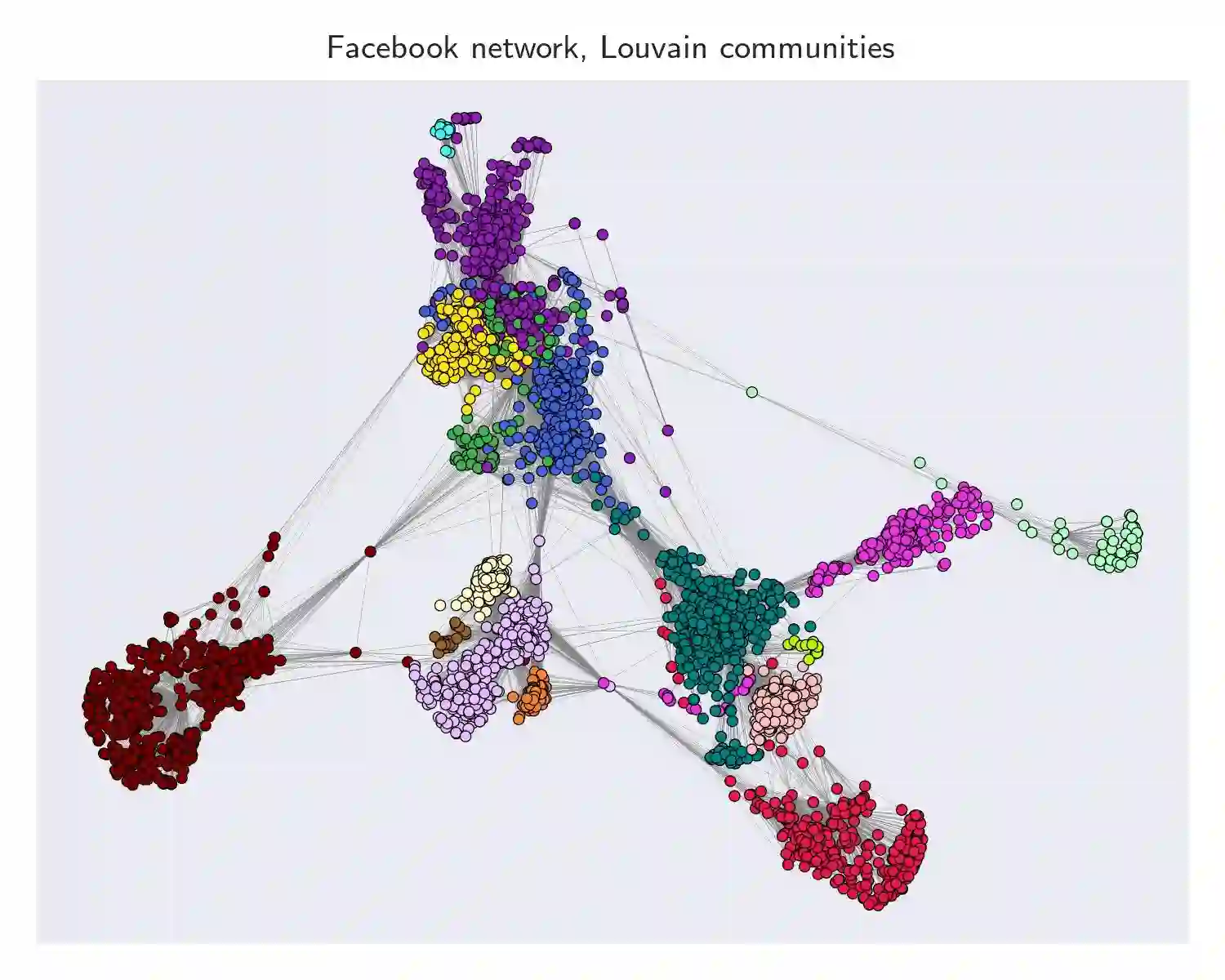
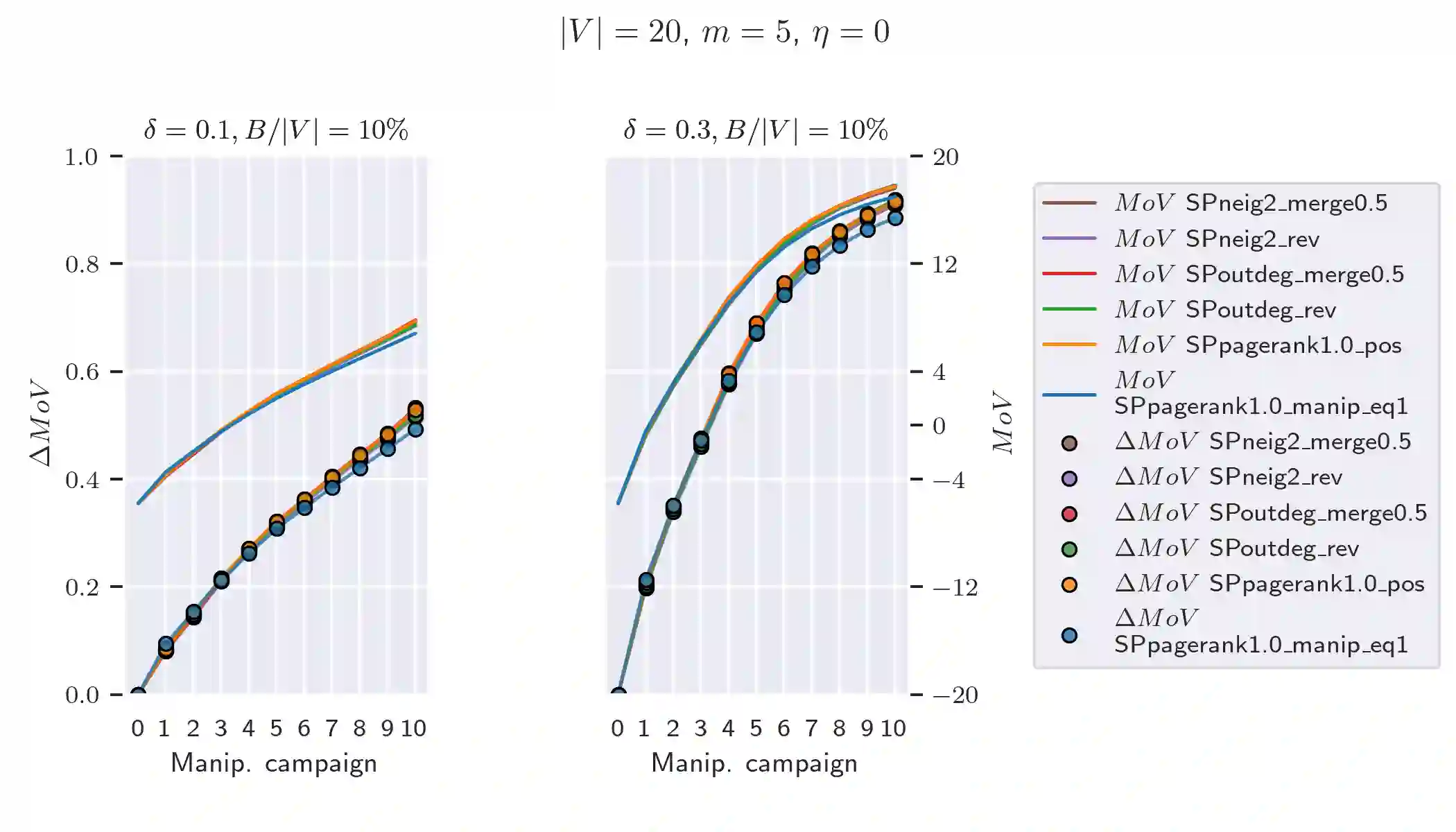
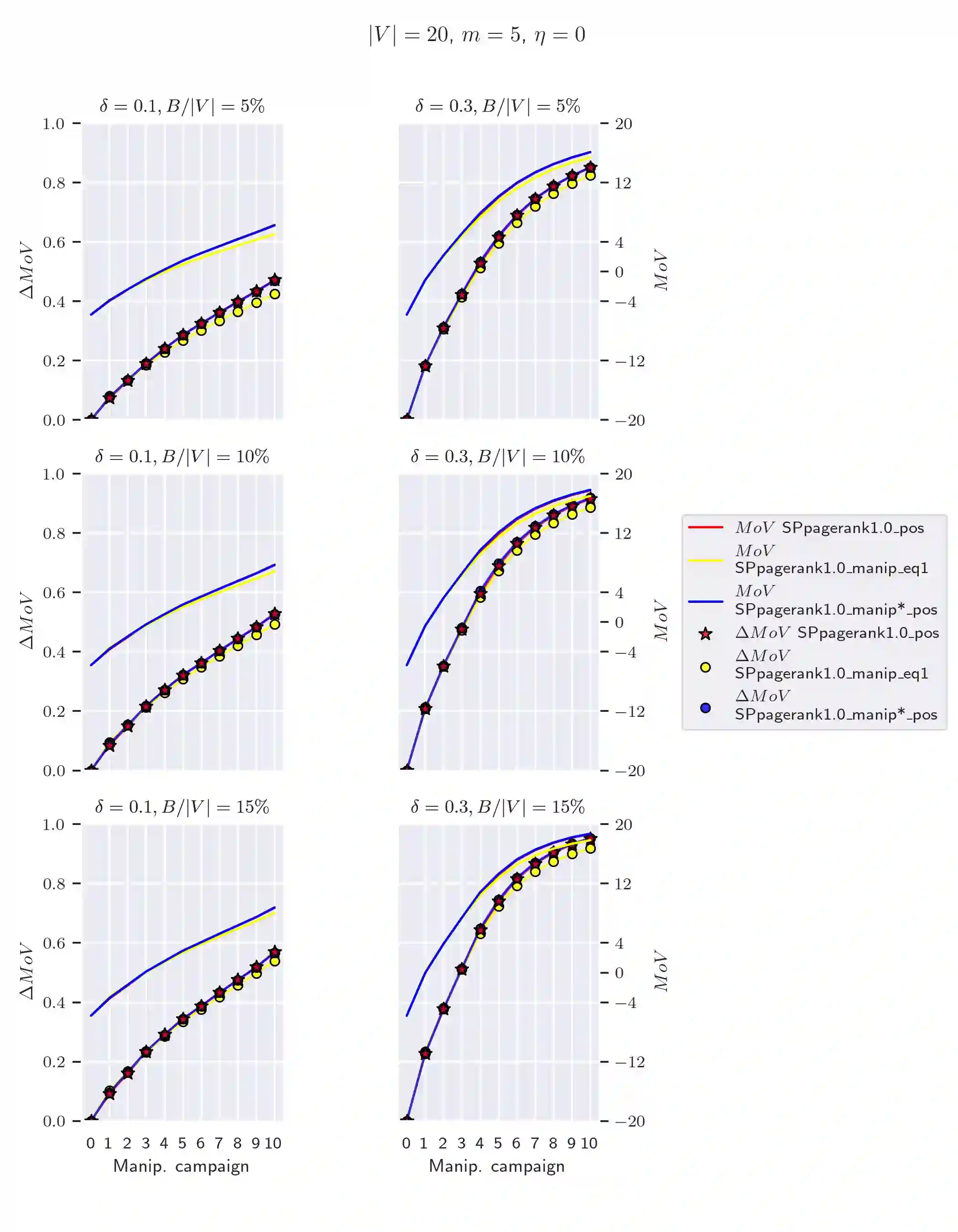
Several elections run in the last years have been characterized by attempts to manipulate the result of the election through the diffusion of fake or malicious news over social networks. This problem has been recognized as a critical issue for the robustness of our democracy. Analyzing and understanding how such manipulations may occur is crucial to the design of effective countermeasures to these practices. Many studies have observed that, in general, to design an optimal manipulation is usually a computationally hard task. Nevertheless, literature on bribery in voting and election manipulation has frequently observed that most hardness results melt down when one focuses on the setting of (nearly) single-peaked agents, i.e., when each voter has a preferred candidate (usually, the one closer to her own belief) and preferences of remaining candidates are inversely proportional to the distance between the candidate position and the voter's belief. Unfortunately, no such analysis has been done for election manipulations run in social networks. In this work, we try to close this gap: specifically, we consider a setting for election manipulation that naturally raises (nearly) single-peaked preferences, and we evaluate the complexity of election manipulation problem in this setting: while most of the hardness and approximation results still hold, we will show that single-peaked preferences allow to design simple, efficient and effective heuristics for election manipulation.
翻译:近几年的多次选举中,通过社交网络传播虚假或恶意新闻来操纵选举结果的现象屡见不鲜。这一问题已被视为对我们民主制度稳健性的关键挑战。分析并理解此类操纵如何发生,对于设计有效的反制措施至关重要。多项研究普遍观察到,设计最优操纵策略通常是一项计算上困难的任务。然而,关于投票贿赂与选举操纵的文献经常指出,当聚焦于(近似)单峰偏好投票者(即每位投票者都有一个偏好候选者——通常最接近其自身信念,而其余候选者的偏好程度则与候选者立场和投票者信念之间的距离成反比)的情境时,大多数困难性结果会消解。遗憾的是,针对社交网络中选举操纵问题的此类分析尚属空白。本研究尝试填补这一缺口:我们构建了一个自然产生(近似)单峰偏好的选举操纵场景,并在此场景下评估选举操纵问题的计算复杂性。结果表明,尽管大部分困难性结论与近似结果仍然成立,但单峰偏好特性使得设计简单、高效且实用的选举操纵启发式算法成为可能。