
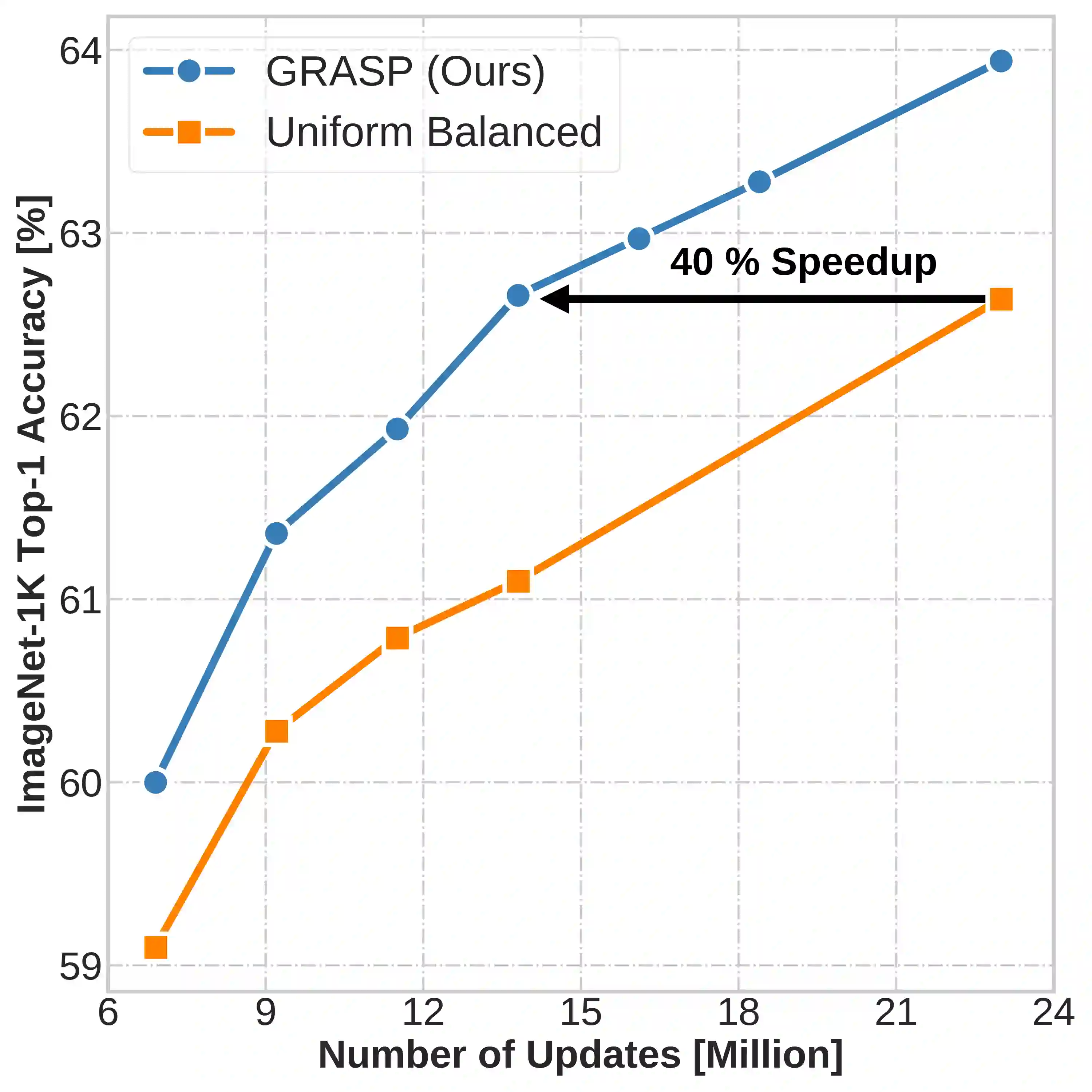
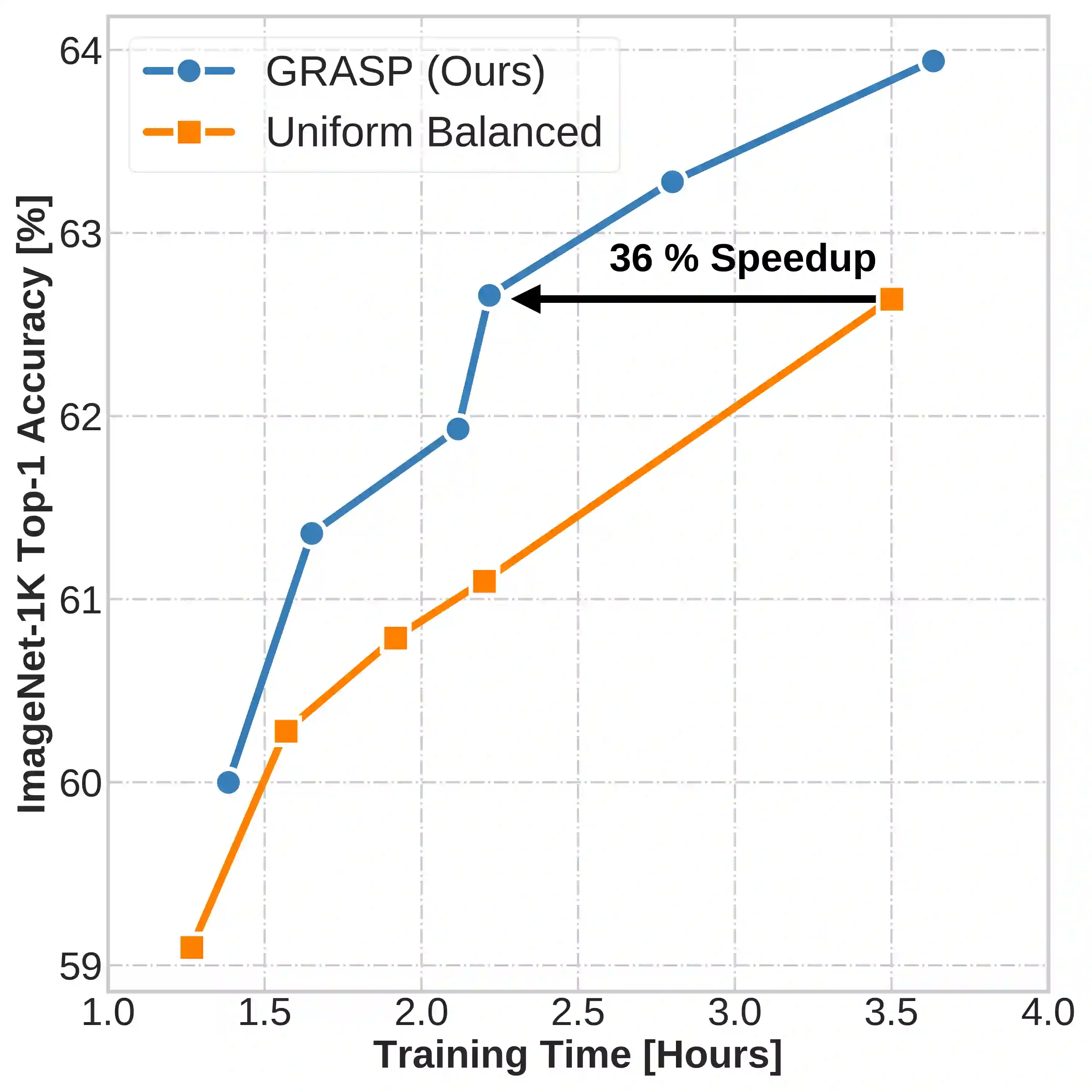
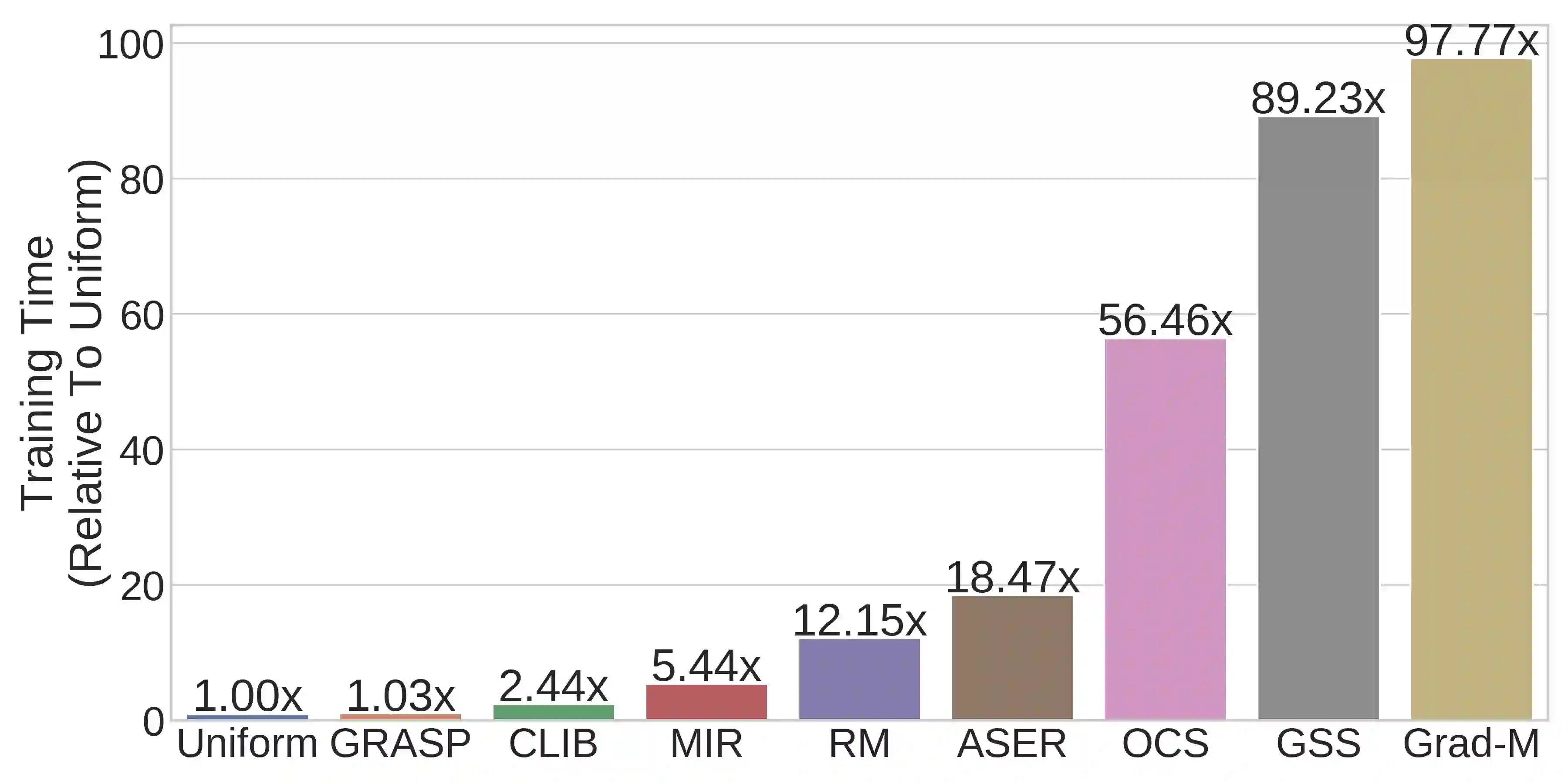
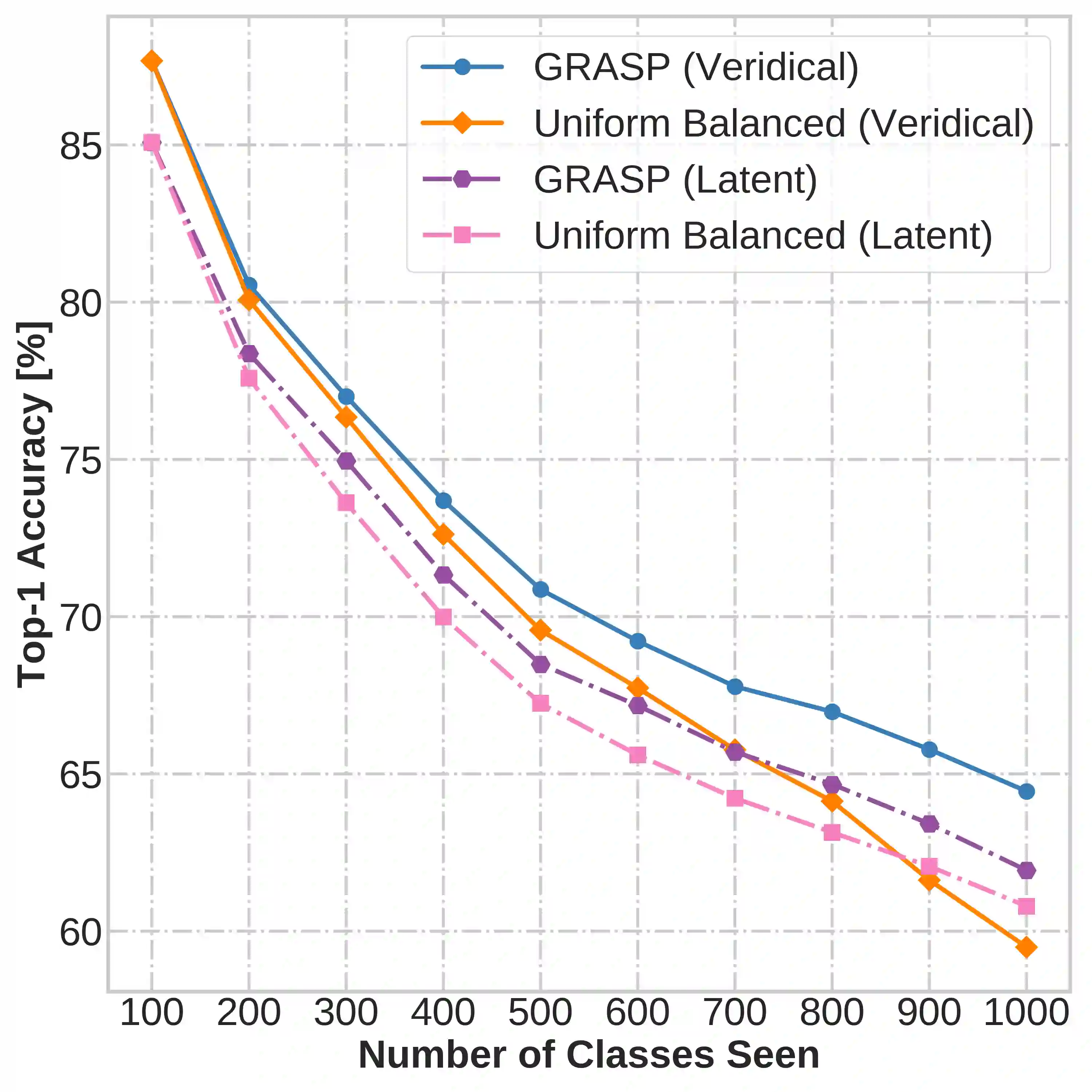
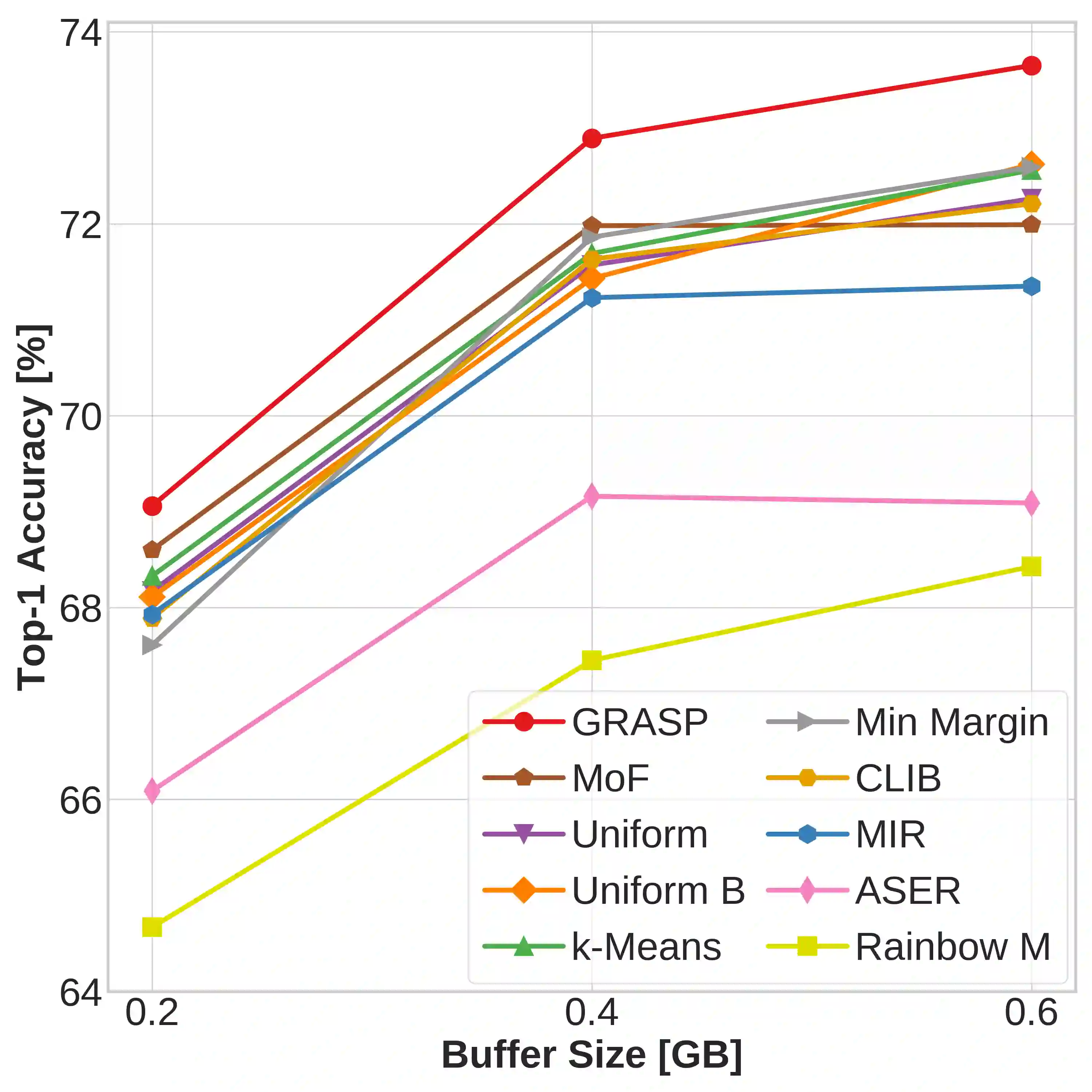
Continual learning (CL) in deep neural networks (DNNs) involves incrementally accumulating knowledge in a DNN from a growing data stream. A major challenge in CL is that non-stationary data streams cause catastrophic forgetting of previously learned abilities. A popular solution is rehearsal: storing past observations in a buffer and then sampling the buffer to update the DNN. Uniform sampling in a class-balanced manner is highly effective, and better sample selection policies have been elusive. Here, we propose a new sample selection policy called GRASP that selects the most prototypical (easy) samples first and then gradually selects less prototypical (harder) examples. GRASP has little additional compute or memory overhead compared to uniform selection, enabling it to scale to large datasets. Compared to 17 other rehearsal policies, GRASP achieves higher accuracy in CL experiments on ImageNet. Compared to uniform balanced sampling, GRASP achieves the same performance with 40% fewer updates. We also show that GRASP is effective for CL on five text classification datasets.
翻译:持续学习(CL)在深度神经网络(DNN)中涉及从不断增长的数据流中逐步积累DNN的知识。CL面临的主要挑战是非平稳数据流会导致先前所学能力的灾难性遗忘。一种流行的解决方案是回放:将过去的观测结果存储在缓冲区中,然后对缓冲区进行采样以更新DNN。基于类别平衡的均匀采样非常有效,而更优的样本选择策略一直难以实现。在此,我们提出一种名为GRASP的新型样本选择策略,该策略首先选择最具原型性(简单)的样本,然后逐步选择原型性较低(较难)的样本。与均匀选择相比,GRASP几乎没有额外的计算或内存开销,使其能够扩展至大规模数据集。在与17种其他回放策略的比较中,GRASP在ImageNet上的持续学习实验中实现了更高准确率。与均匀平衡采样相比,GRASP在减少40%更新次数的情况下达到了相同性能。我们还表明GRASP在五个文本分类数据集上的持续学习中是有效的。
相关内容

Source: Apple - iOS 8

