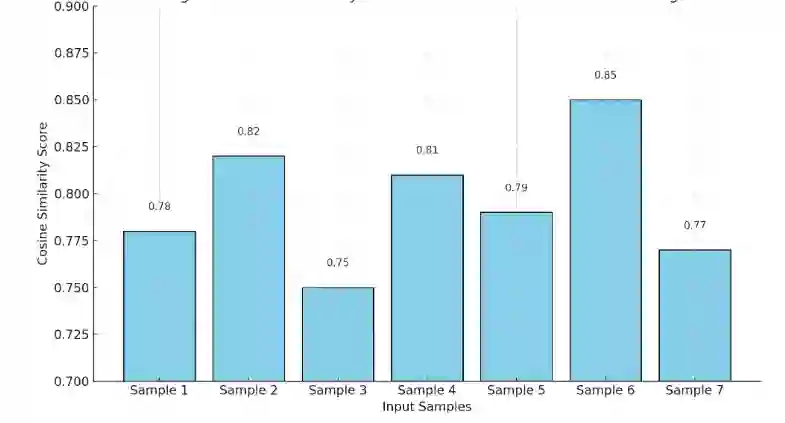
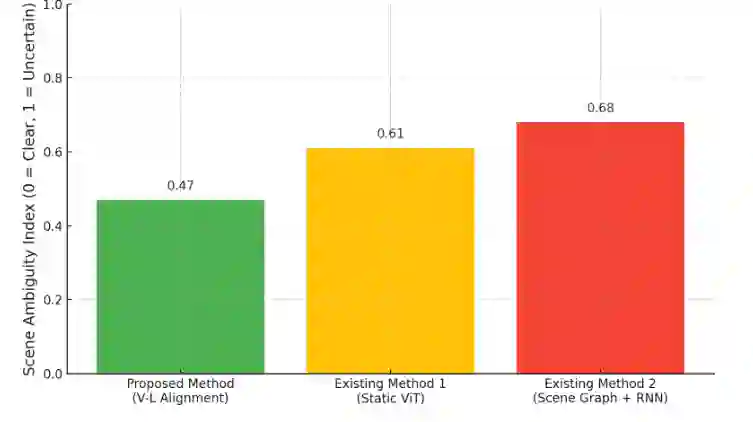
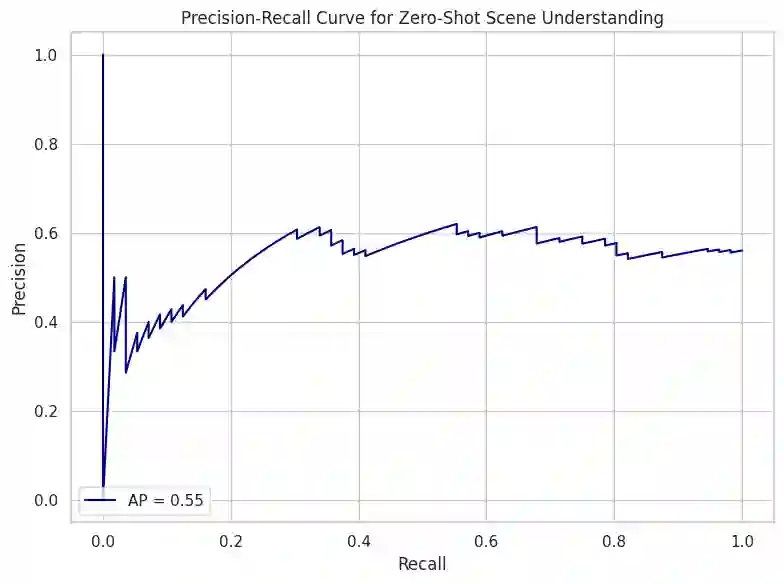
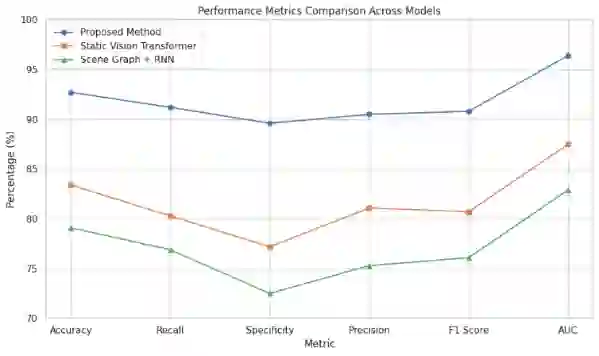
In real-world environments, AI systems often face unfamiliar scenarios without labeled data, creating a major challenge for conventional scene understanding models. The inability to generalize across unseen contexts limits the deployment of vision-based applications in dynamic, unstructured settings. This work introduces a Dynamic Context-Aware Scene Reasoning framework that leverages Vision-Language Alignment to address zero-shot real-world scenarios. The goal is to enable intelligent systems to infer and adapt to new environments without prior task-specific training. The proposed approach integrates pre-trained vision transformers and large language models to align visual semantics with natural language descriptions, enhancing contextual comprehension. A dynamic reasoning module refines predictions by combining global scene cues and object-level interactions guided by linguistic priors. Extensive experiments on zero-shot benchmarks such as COCO, Visual Genome, and Open Images demonstrate up to 18% improvement in scene understanding accuracy over baseline models in complex and unseen environments. Results also show robust performance in ambiguous or cluttered scenes due to the synergistic fusion of vision and language. This framework offers a scalable and interpretable approach for context-aware reasoning, advancing zero-shot generalization in dynamic real-world settings.
翻译:在真实世界环境中,人工智能系统常面临缺乏标注数据的陌生场景,这对传统场景理解模型构成了重大挑战。无法在未见过的上下文之间进行泛化,限制了基于视觉的应用在动态、非结构化环境中的部署。本研究提出了一种动态上下文感知场景推理框架,该框架利用视觉-语言对齐来解决零样本真实世界场景问题。其目标是使智能系统能够在无需先验任务特定训练的情况下,推断并适应新环境。所提出的方法整合了预训练的视觉Transformer和大型语言模型,以将视觉语义与自然语言描述对齐,从而增强上下文理解能力。一个动态推理模块通过结合全局场景线索和由语言先验引导的对象级交互,来优化预测结果。在COCO、Visual Genome和Open Images等零样本基准数据集上进行的大量实验表明,在复杂和未见过的环境中,场景理解准确率相较于基线模型提升了高达18%。结果还显示,由于视觉与语言的协同融合,该框架在模糊或杂乱场景中表现出鲁棒性能。该框架为上下文感知推理提供了一种可扩展且可解释的方法,推动了动态真实世界场景中零样本泛化能力的发展。