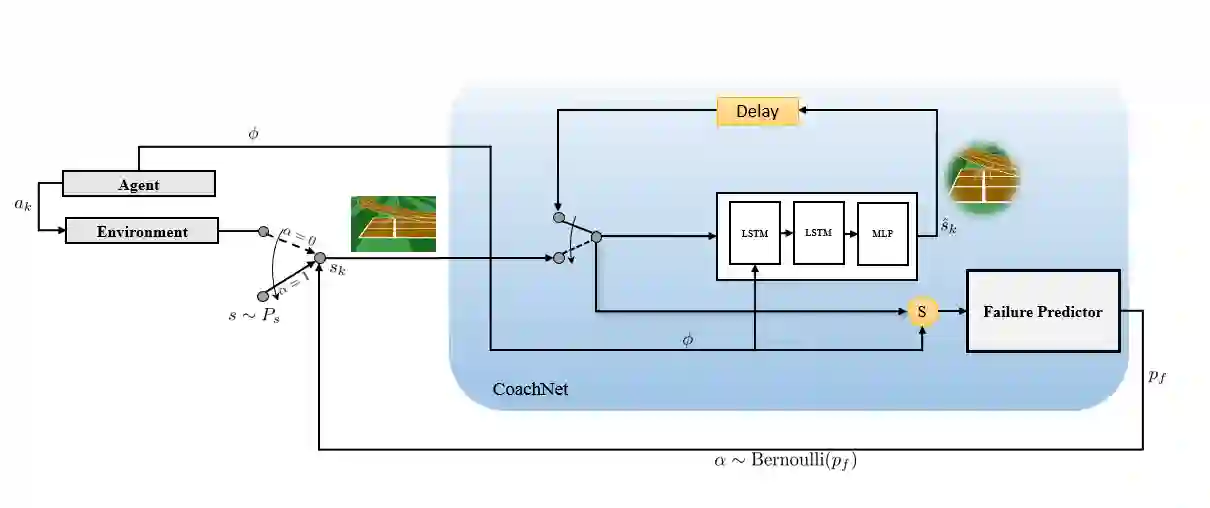
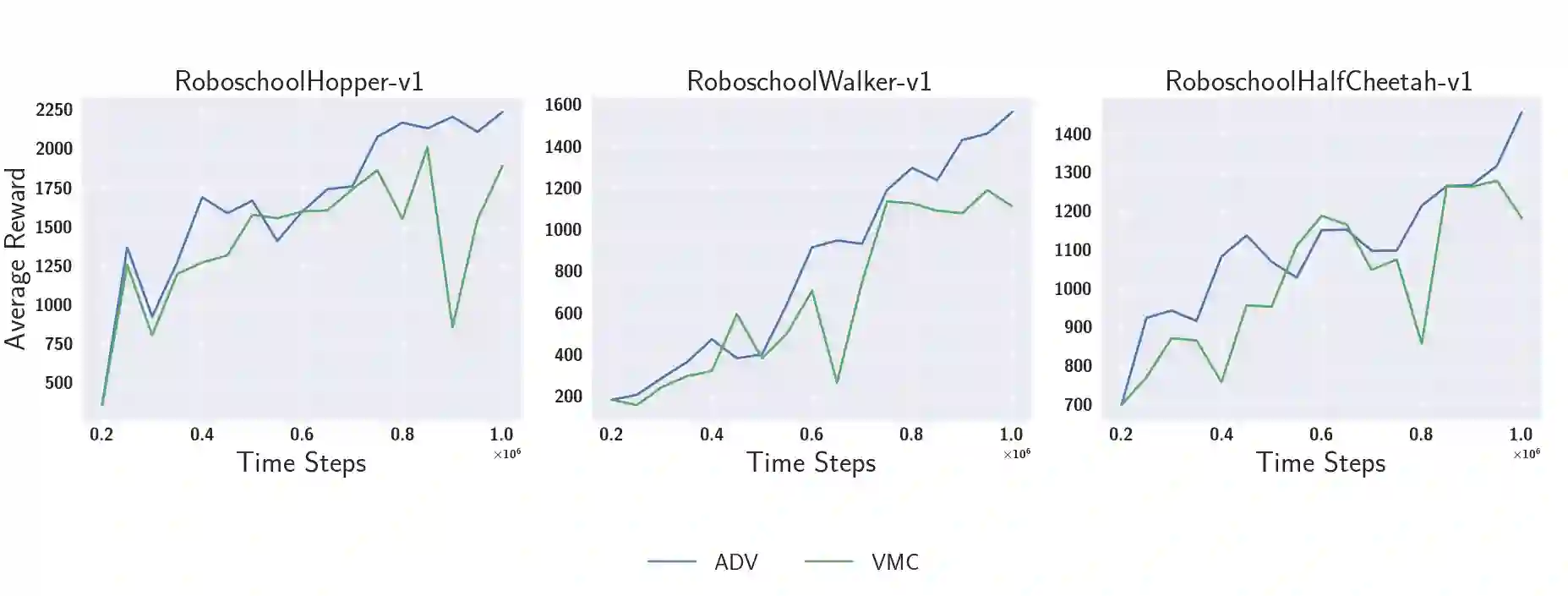
Despite the recent successes of reinforcement learning in games and robotics, it is yet to become broadly practical. Sample efficiency and unreliable performance in rare but challenging scenarios are two of the major obstacles. Drawing inspiration from the effectiveness of deliberate practice for achieving expert-level human performance, we propose a new adversarial sampling approach guided by a failure predictor named "CoachNet". CoachNet is trained online along with the agent to predict the probability of failure. This probability is then used in a stochastic sampling process to guide the agent to more challenging episodes. This way, instead of wasting time on scenarios that the agent has already mastered, training is focused on the agent's "weak spots". We present the design of CoachNet, explain its underlying principles, and empirically demonstrate its effectiveness in improving sample efficiency and test-time robustness in common continuous control tasks.
翻译:尽管最近在游戏和机器人方面的强化学习取得了成功,但这一可能性还有待广泛实践。在罕见但具有挑战性的情景中,抽样效率和不可靠的表现是两大障碍。我们从实现专家一级人类业绩的审慎做法的有效性中得到启发,我们提议了一个新的对抗性抽样方法,由名为“CoachNet”的失败预测师指导。CootNet与代理商一起在网上接受培训,以预测失败概率。然后在随机抽样过程中使用这一概率来引导代理商更具有挑战性的事件。这样,培训不是浪费时间在代理商已经掌握的情景上,而是侧重于该代理商的“弱点点 ” 。 我们介绍CoachNet的设计,解释其基本原则,并用经验证明其在提高样本效率和测试时间的稳健性,共同的连续控制任务方面的有效性。