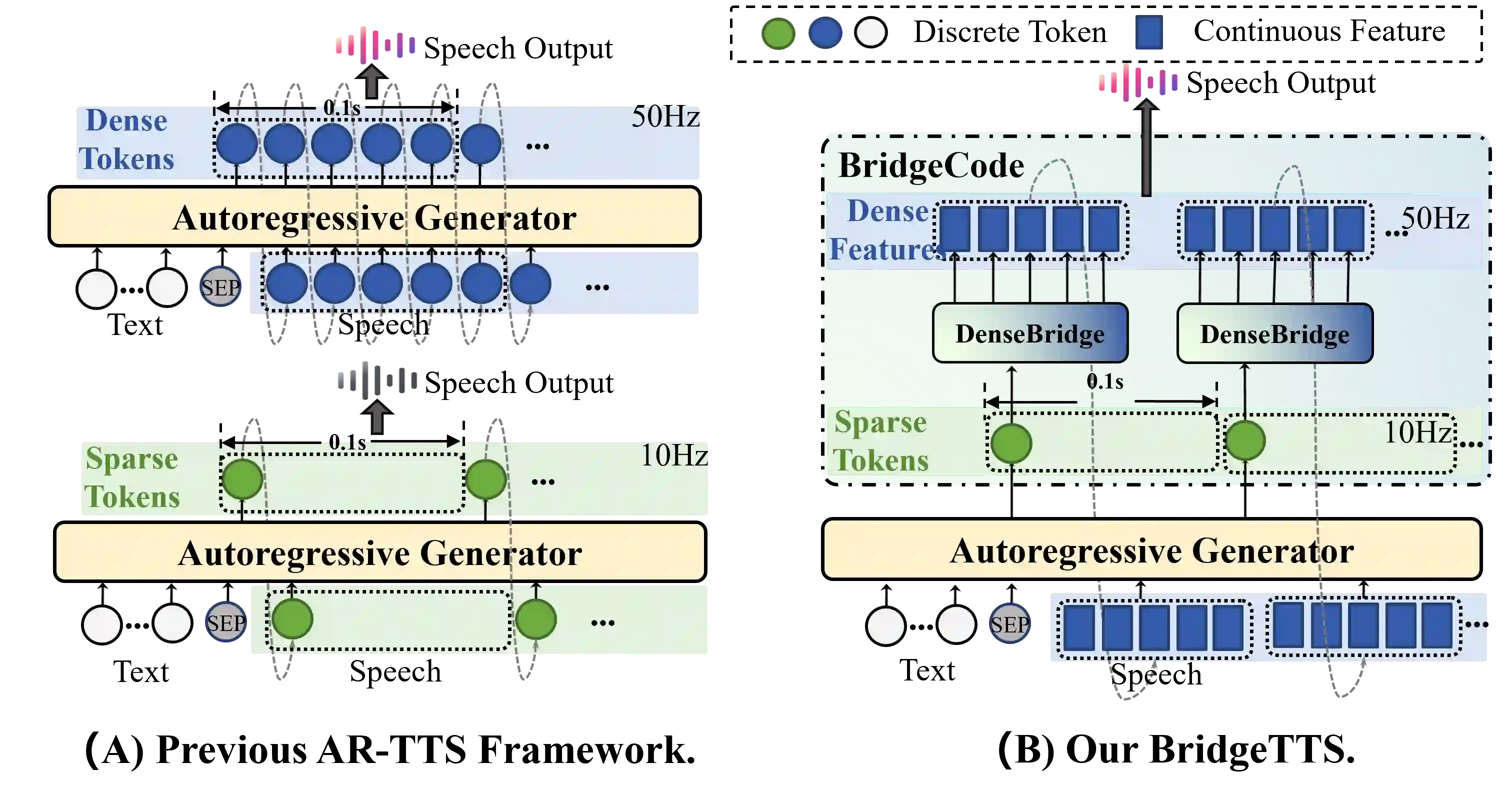
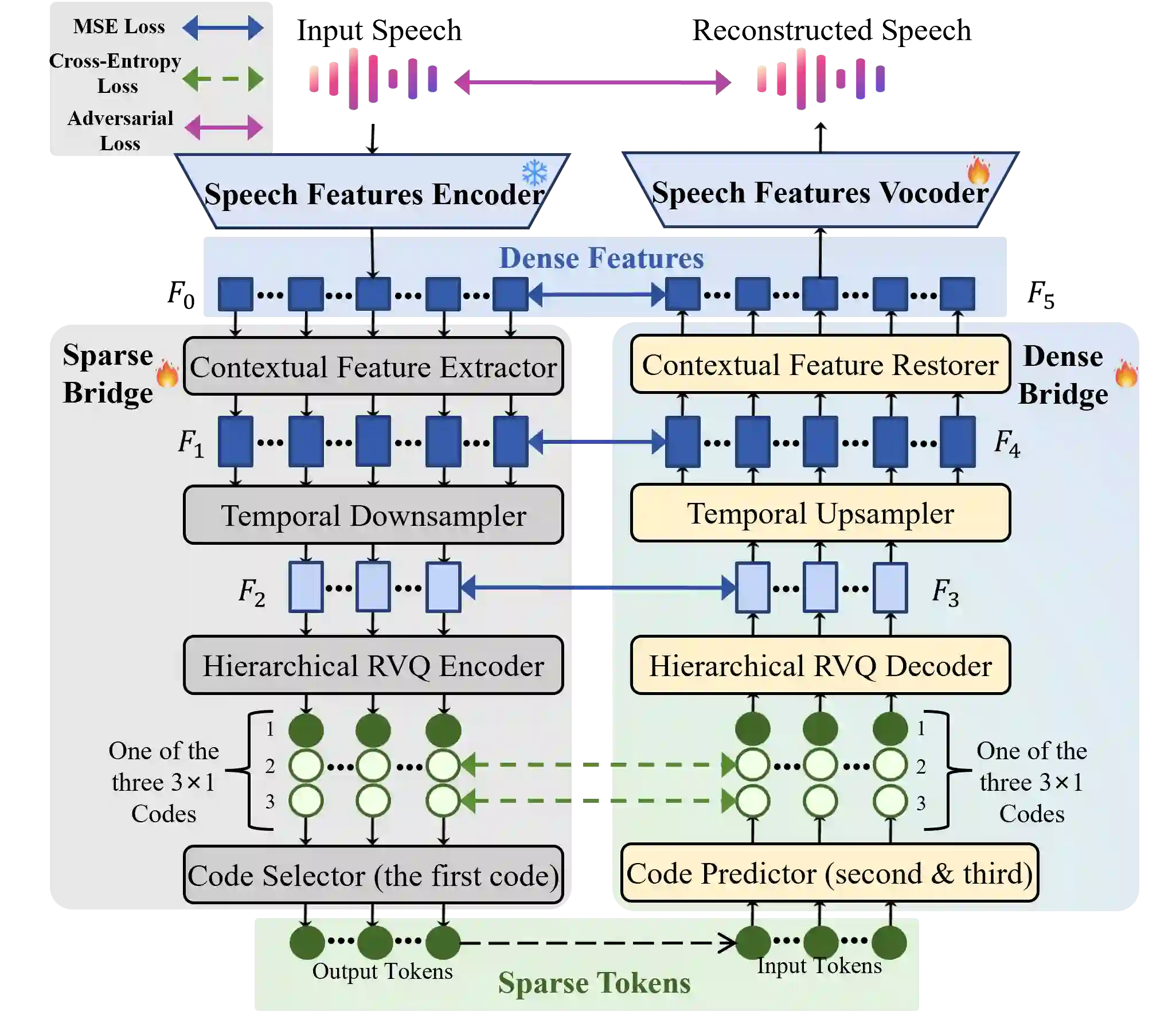
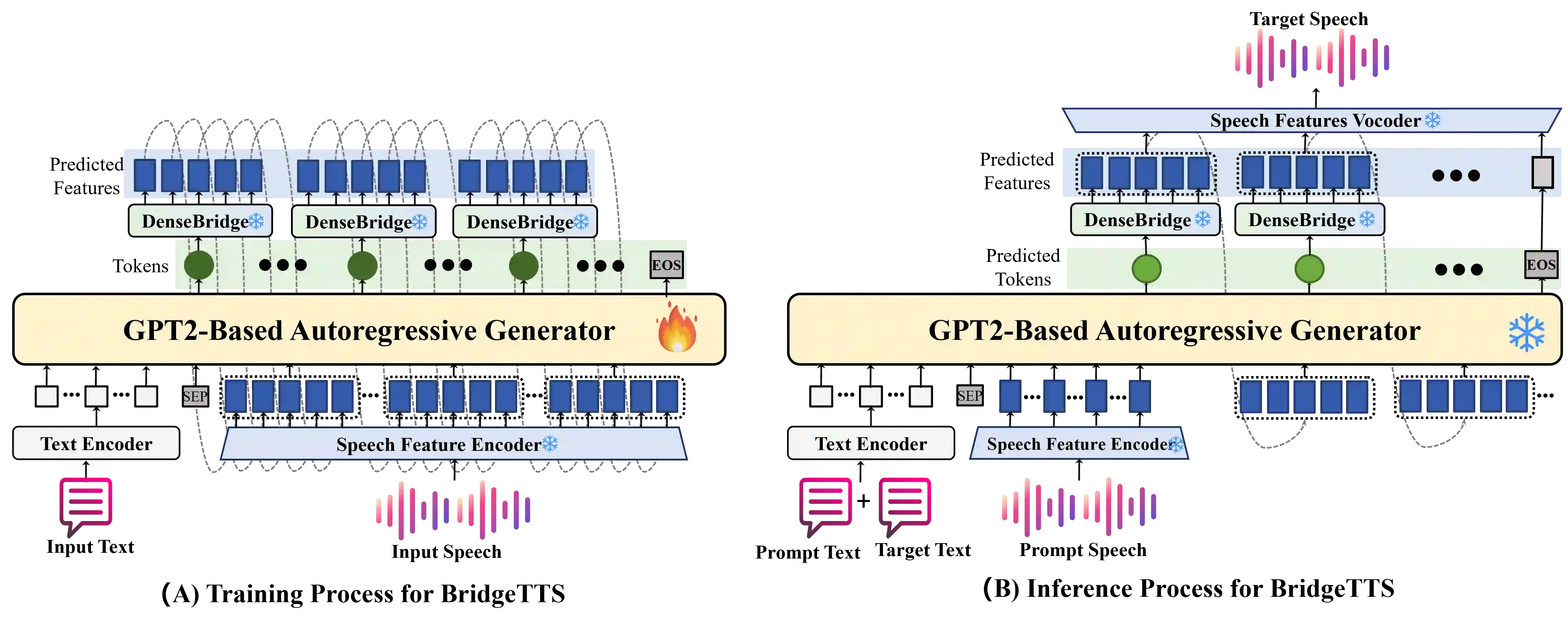
Autoregressive (AR) frameworks have recently achieved remarkable progress in zero-shot text-to-speech (TTS) by leveraging discrete speech tokens and large language model techniques. Despite their success, existing AR-based zero-shot TTS systems face two critical limitations: (i) an inherent speed-quality trade-off, as sequential token generation either reduces frame rates at the cost of expressiveness or enriches tokens at the cost of efficiency, and (ii) a text-oriented supervision mismatch, as cross-entropy loss penalizes token errors uniformly without considering the fine-grained acoustic similarity among adjacent tokens. To address these challenges, we propose BridgeTTS, a novel AR-TTS framework built upon the dual speech representation paradigm BridgeCode. BridgeTTS reduces AR iterations by predicting sparse tokens while reconstructing rich continuous features for high-quality synthesis. Joint optimization of token-level and feature-level objectives further enhances naturalness and intelligibility. Experiments demonstrate that BridgeTTS achieves competitive quality and speaker similarity while significantly accelerating synthesis. Speech demos are available at https://test1562.github.io/demo/.
翻译:自回归(AR)框架最近通过利用离散语音标记和大语言模型技术,在零样本文本到语音(TTS)领域取得了显著进展。尽管取得了成功,但现有的基于自回归的零样本TTS系统面临两个关键局限:(i)固有的速度-质量权衡,因为序列标记生成要么以牺牲表现力为代价降低帧率,要么以牺牲效率为代价丰富标记;(ii)面向文本的监督不匹配,因为交叉熵损失均匀地惩罚标记错误,而未考虑相邻标记之间细粒度的声学相似性。为应对这些挑战,我们提出了BridgeTTS,一种基于双语音表征范式BridgeCode的新型AR-TTS框架。BridgeTTS通过预测稀疏标记同时重建丰富的连续特征以实现高质量合成,从而减少了自回归迭代次数。标记级和特征级目标的联合优化进一步提升了自然度和清晰度。实验表明,BridgeTTS在显著加速合成的同时,实现了具有竞争力的音质和说话人相似性。语音样本可在 https://test1562.github.io/demo/ 获取。