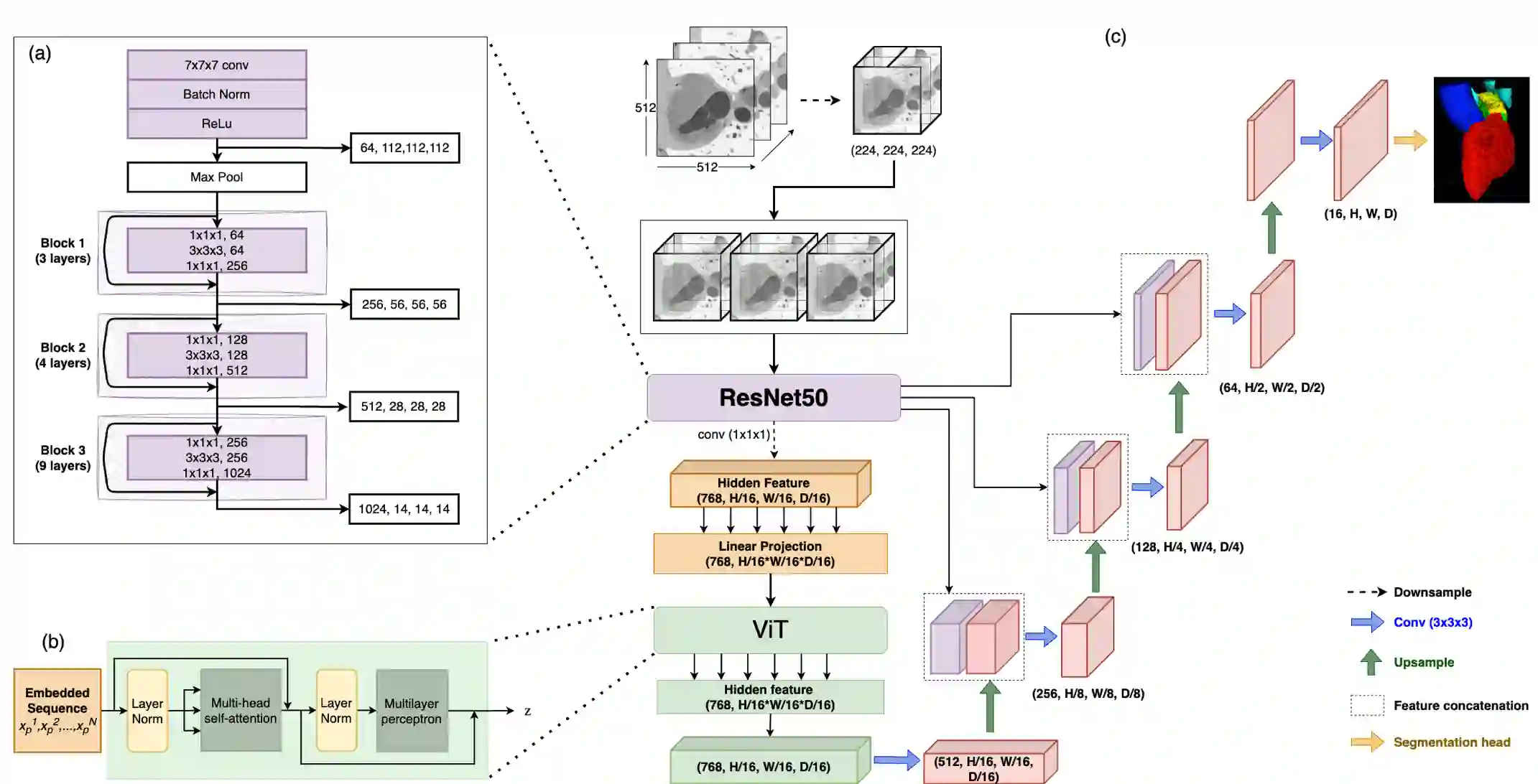
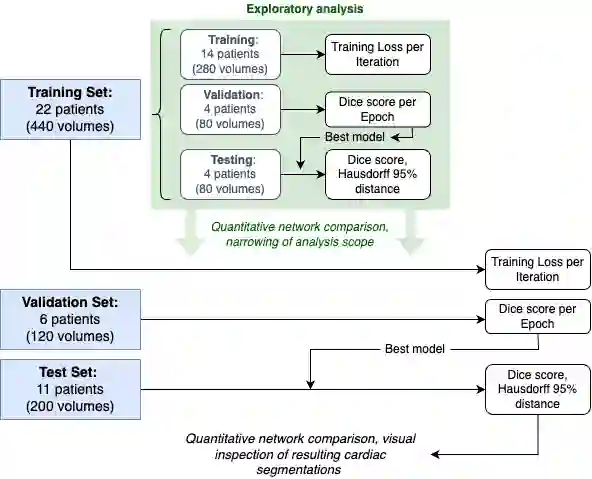
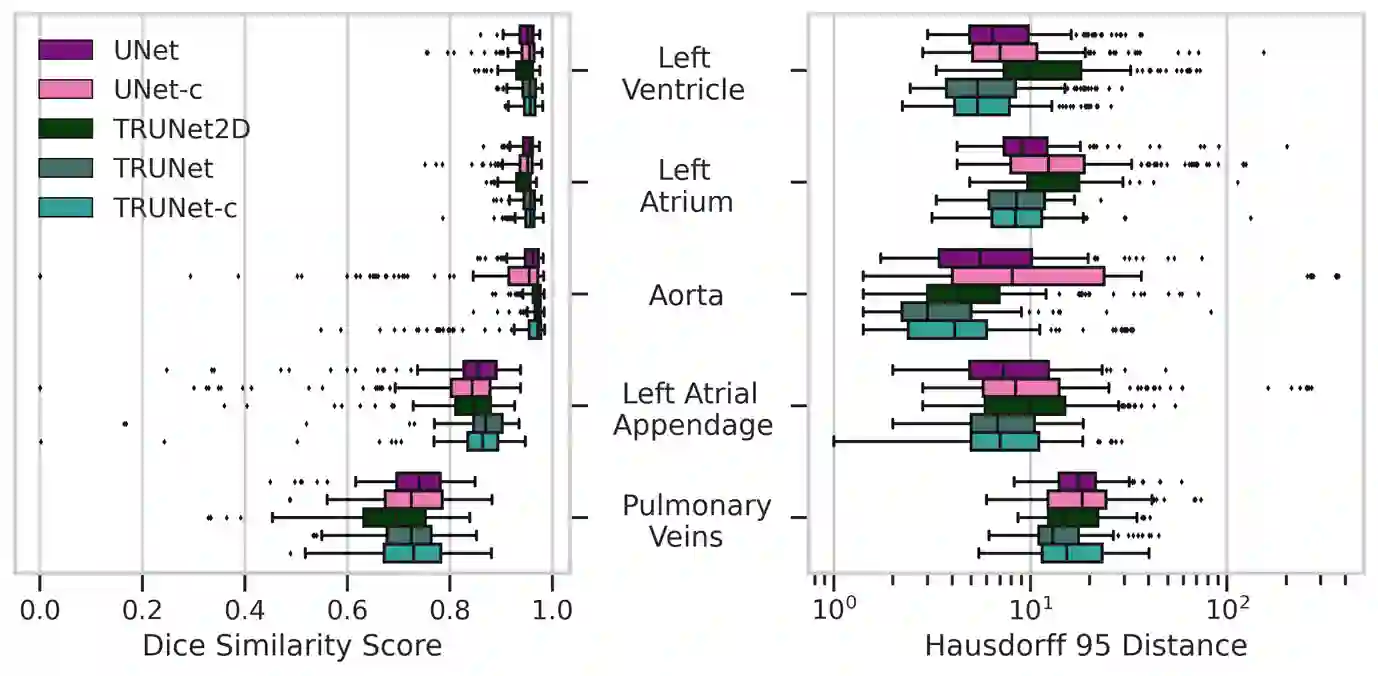
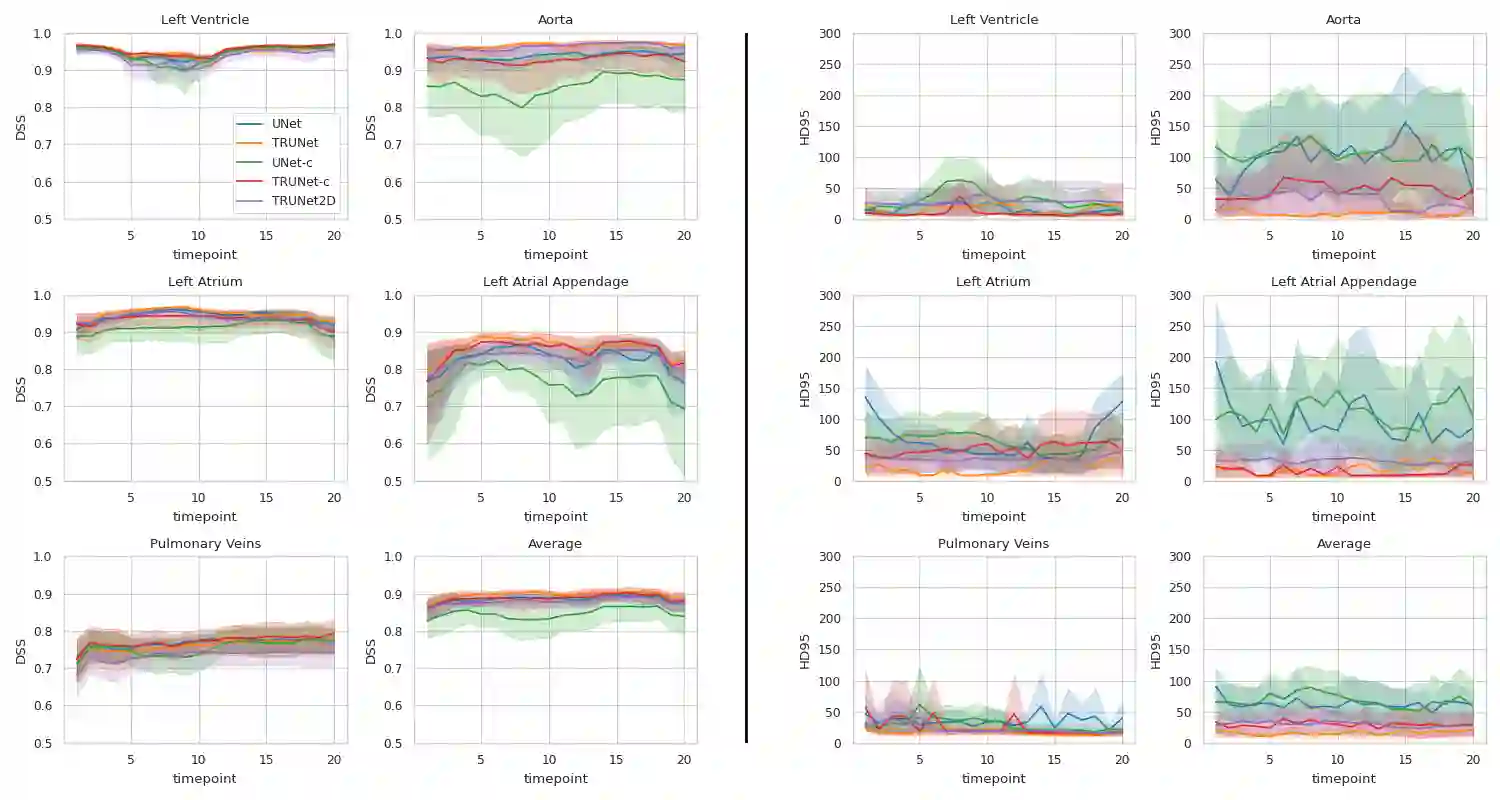
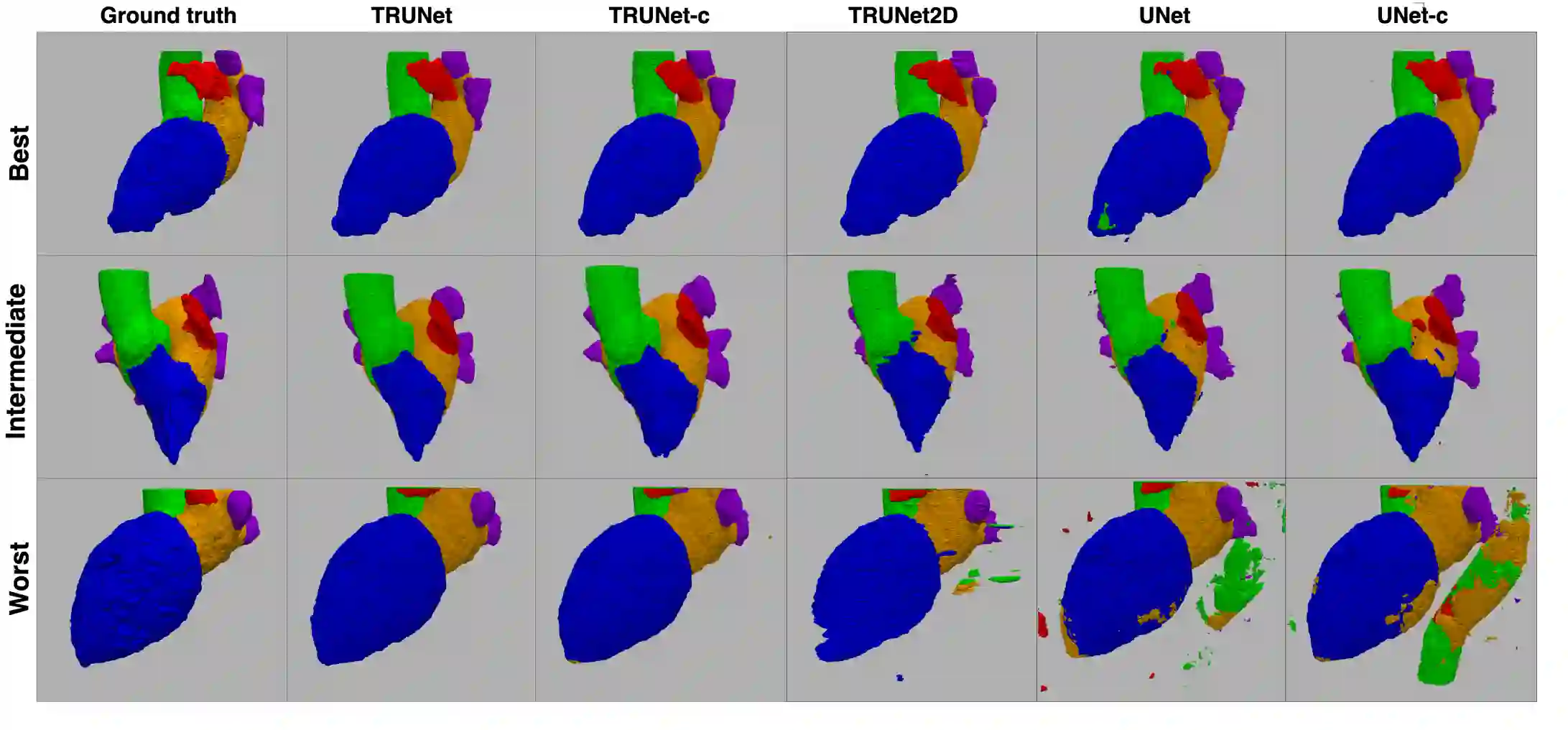
Accurate segmentation of the heart is essential for personalized blood flow simulations and surgical intervention planning. A recent advancement in image recognition is the Vision Transformer (ViT), which expands the field of view to encompass a greater portion of the global image context. We adapted ViT for three-dimensional volume inputs. Cardiac computed tomography (CT) volumes from 39 patients, featuring up to 20 timepoints representing the complete cardiac cycle, were utilized. Our network incorporates a modified ResNet50 block as well as a ViT block and employs cascade upsampling with skip connections. Despite its increased model complexity, our hybrid Transformer-Residual U-Net framework, termed TRUNet, converges in significantly less time than residual U-Net while providing comparable or superior segmentations of the left ventricle, left atrium, left atrial appendage, ascending aorta, and pulmonary veins. TRUNet offers more precise vessel boundary segmentation and better captures the heart's overall anatomical structure compared to residual U-Net, as confirmed by the absence of extraneous clusters of missegmented voxels. In terms of both performance and training speed, TRUNet exceeded U-Net, a commonly used segmentation architecture, making it a promising tool for 3D semantic segmentation tasks in medical imaging. The code for TRUNet is available at github.com/ljollans/TRUNet.
翻译:心脏的精确分割对于个性化血流模拟和手术干预规划至关重要。图像识别领域的最新进展是Vision Transformer(ViT),它扩展了视野范围以包含更多全局图像上下文信息。我们将ViT适配用于三维体积输入。研究使用了来自39名患者的心脏计算机断层扫描(CT)体积数据,每个患者包含多达20个时间点,覆盖完整心动周期。我们的网络融合了改进的ResNet50模块和ViT模块,并采用带有跳跃连接的级联上采样方法。尽管模型复杂度增加,但我们的混合Transformer-残差U-Net框架(命名为TRUNet)在收敛时间上显著优于残差U-Net,同时在左心室、左心房、左心耳、升主动脉和肺静脉的分割中达到相当或更优的效果。与残差U-Net相比,TRUNet能够提供更精确的血管边界分割,并更好地捕捉心脏整体解剖结构——这一结论由误分割体素的外来聚类簇缺失所证实。在性能和训练速度方面,TRUNet均超越了常用分割架构U-Net,成为医学成像三维语义分割任务中的有前景工具。TRUNet的代码已开源至github.com/ljollans/TRUNet。