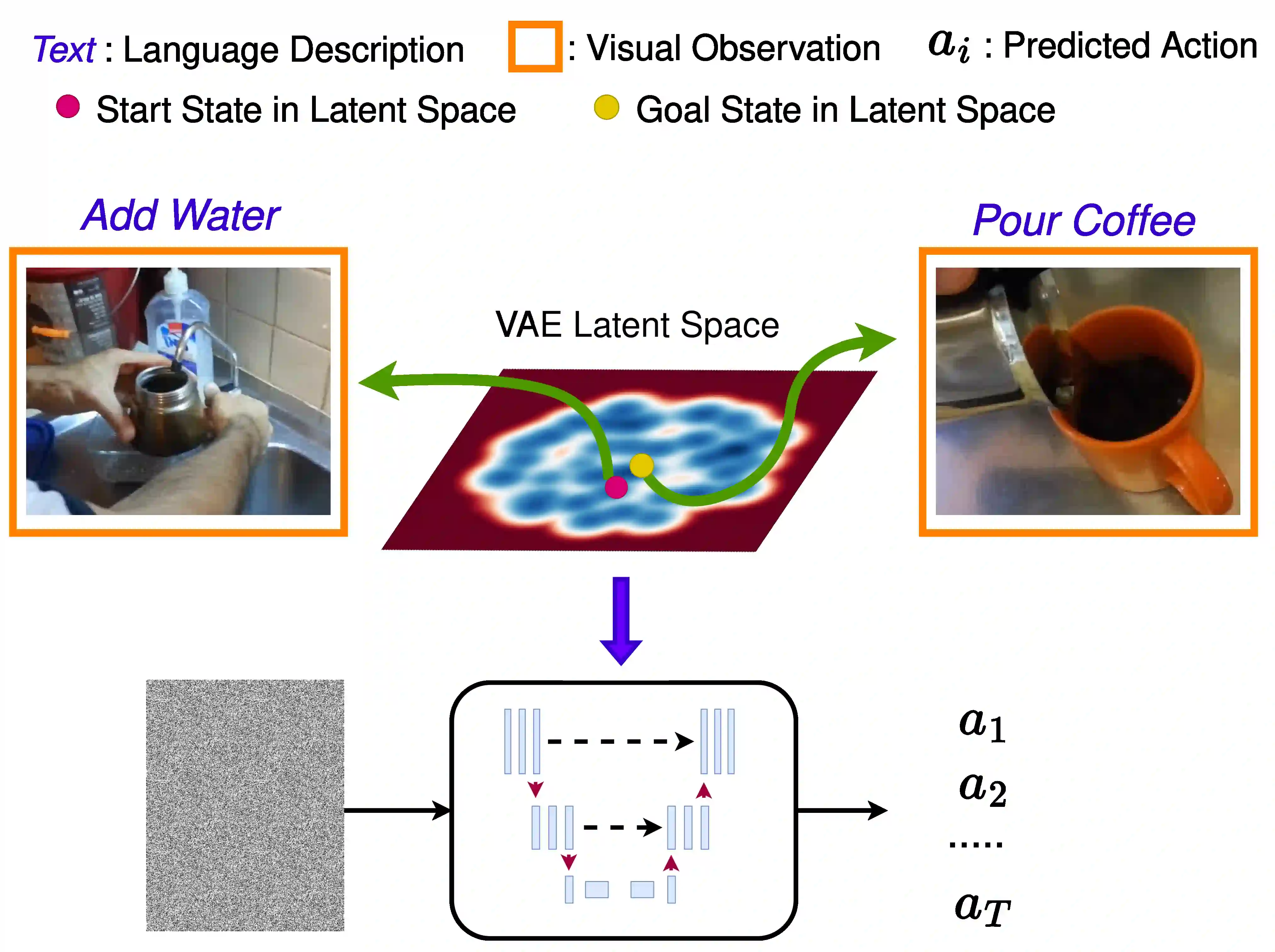
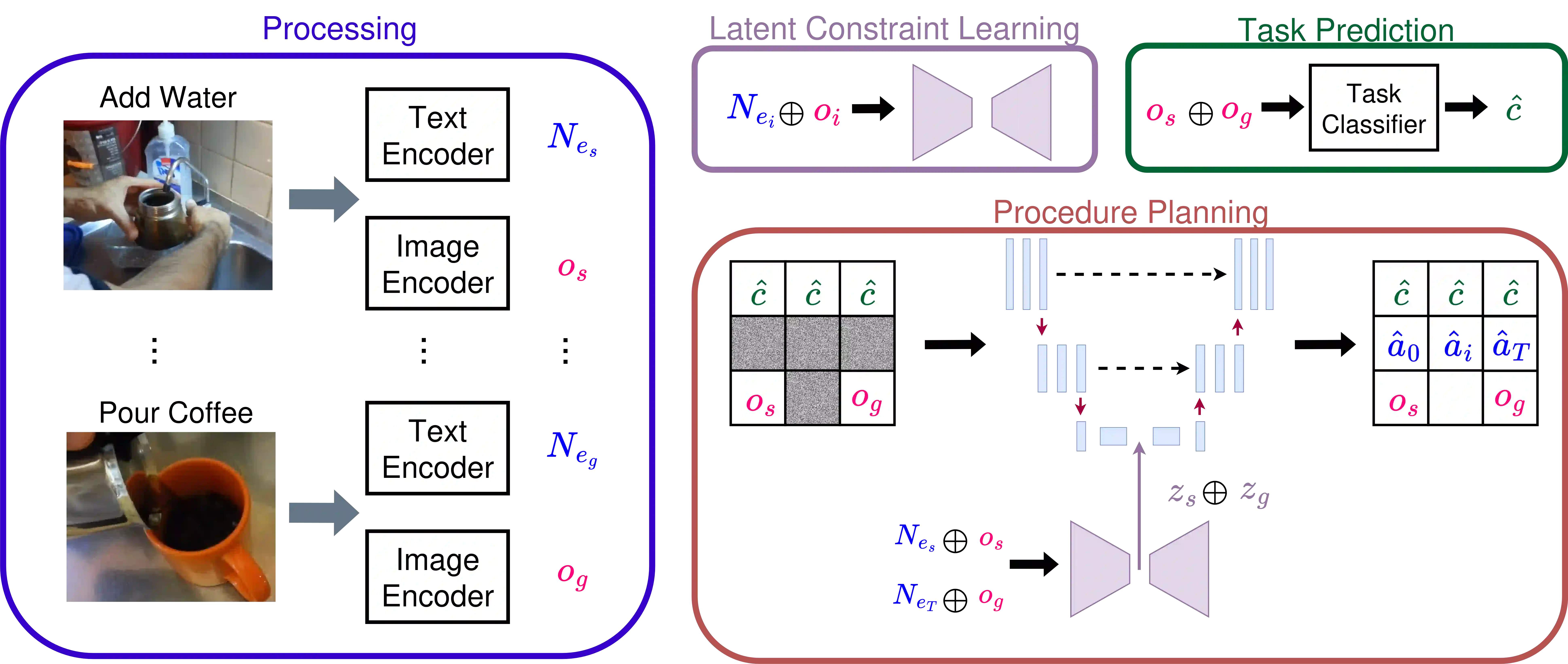
We propose CLAD, a Constrained Latent Action Diffusion model for vision-language procedure planning in instructional videos. Procedure planning is the challenging task of predicting intermediate actions given a visual observation of a start and a goal state. However, future interactive AI systems must also be able to plan procedures using multi-modal input, e.g., where visual observations are augmented with language descriptions. To tackle this vision-language procedure planning task, our method uses a Variational Autoencoder (VAE) to learn the latent representation of actions and observations as constraints and integrate them into the diffusion process. This approach exploits that the latent space of diffusion models already has semantics that can be used. We use the latent constraints to steer the diffusion model to better generate actions. We report extensive experiments on the popular CrossTask, Coin, and NIV datasets and show that our method outperforms state-of-the-art methods by a large margin. By evaluating ablated versions of our method, we further show that the proposed integration of the action and observation representations learnt in the VAE latent space is key to these performance improvements.
翻译:我们提出CLAD,一种用于教学视频中视觉-语言过程规划的约束潜在动作扩散模型。过程规划是根据起始状态与目标状态的视觉观察预测中间动作的挑战性任务。然而,未来的交互式AI系统还必须能够利用多模态输入进行过程规划,例如视觉观察与语言描述相结合的场景。为应对这一视觉-语言过程规划任务,本方法采用变分自编码器(VAE)学习动作与观察的潜在表示作为约束,并将其融入扩散过程。该方法的优势在于利用了扩散模型潜在空间本身具备的可用于约束的语义信息。我们通过潜在约束引导扩散模型更好地生成动作。在主流CrossTask、Coin和NIV数据集上的大量实验表明,本方法显著优于现有最优方法。通过消融实验分析,我们进一步证明在VAE潜在空间中学习的动作与观察表示的整合机制是实现性能提升的关键。