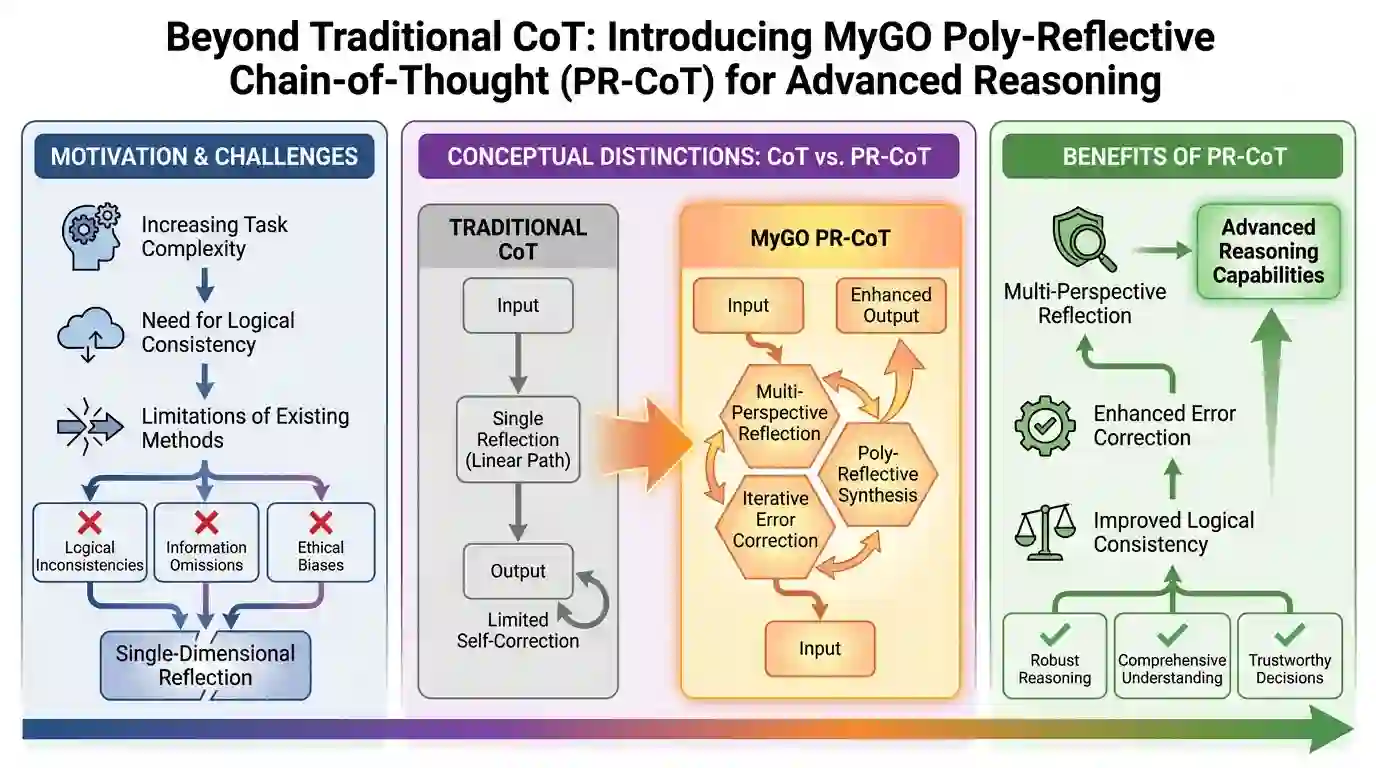
While Chain-of-Thought (CoT) prompting advances LLM reasoning, challenges persist in consistency, accuracy, and self-correction, especially for complex or ethically sensitive tasks. Existing single-dimensional reflection methods offer insufficient improvements. We propose MyGO Poly-Reflective Chain-of-Thought (PR-CoT), a novel methodology employing structured multi-perspective reflection. After initial CoT, PR-CoT guides the LLM to self-assess its reasoning across multiple predefined angles: logical consistency, information completeness, biases/ethics, and alternative solutions. Implemented purely via prompt engineering, this process refines the initial CoT into a more robust and accurate final answer without model retraining. Experiments across arithmetic, commonsense, ethical decision-making, and logical puzzles, using GPT-three point five and GPT-four models, demonstrate PR-CoT's superior performance. It significantly outperforms traditional CoT and existing reflection methods in logical consistency and error correction, with notable gains in nuanced domains like ethical decision-making. Ablation studies, human evaluations, and qualitative analyses further validate the contribution of each reflection perspective and the overall efficacy of our poly-reflective paradigm in fostering more reliable LLM reasoning.
翻译:尽管思维链(CoT)提示技术推动了大型语言模型(LLM)的推理能力,但在处理复杂或涉及伦理敏感性的任务时,其一致性、准确性和自校正方面仍存在挑战。现有的单维度反思方法改进效果有限。本文提出MyGO多视角反思思维链(PR-CoT),这是一种采用结构化多视角反思的新方法。在初始CoT推理后,PR-CoT引导LLM从多个预定义维度对自身推理进行自我评估:逻辑一致性、信息完整性、偏见/伦理考量以及替代解决方案。该方法完全通过提示工程实现,无需重新训练模型即可将初始CoT优化为更稳健、更准确的最终答案。在算术、常识推理、伦理决策和逻辑谜题等任务上,使用GPT-3.5和GPT-4模型的实验表明,PR-CoT具有卓越性能。其在逻辑一致性和错误校正方面显著优于传统CoT及现有反思方法,在伦理决策等复杂领域提升尤为显著。消融实验、人工评估和定性分析进一步验证了各反思维度的贡献,以及我们提出的多视角反思范式在提升LLM推理可靠性方面的整体有效性。