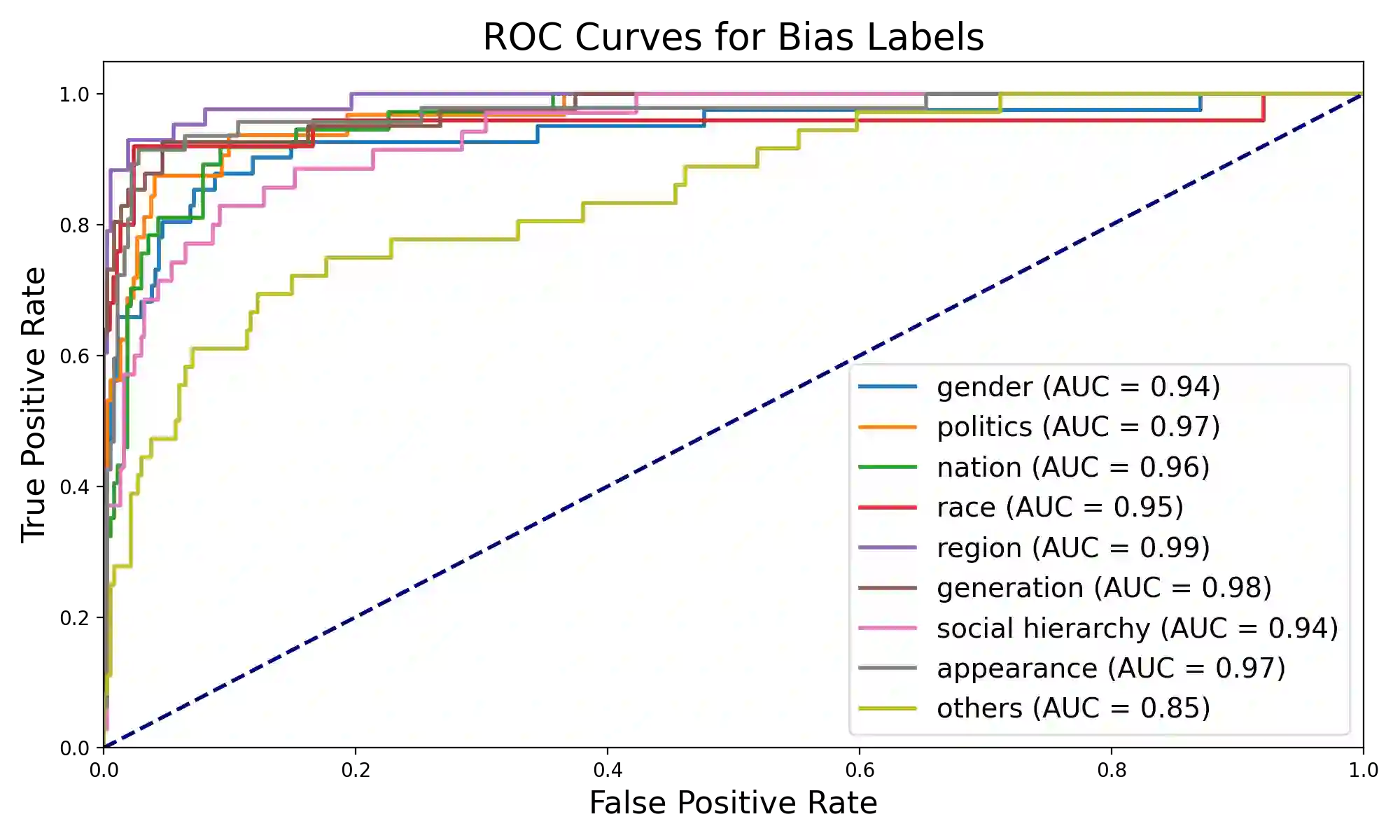
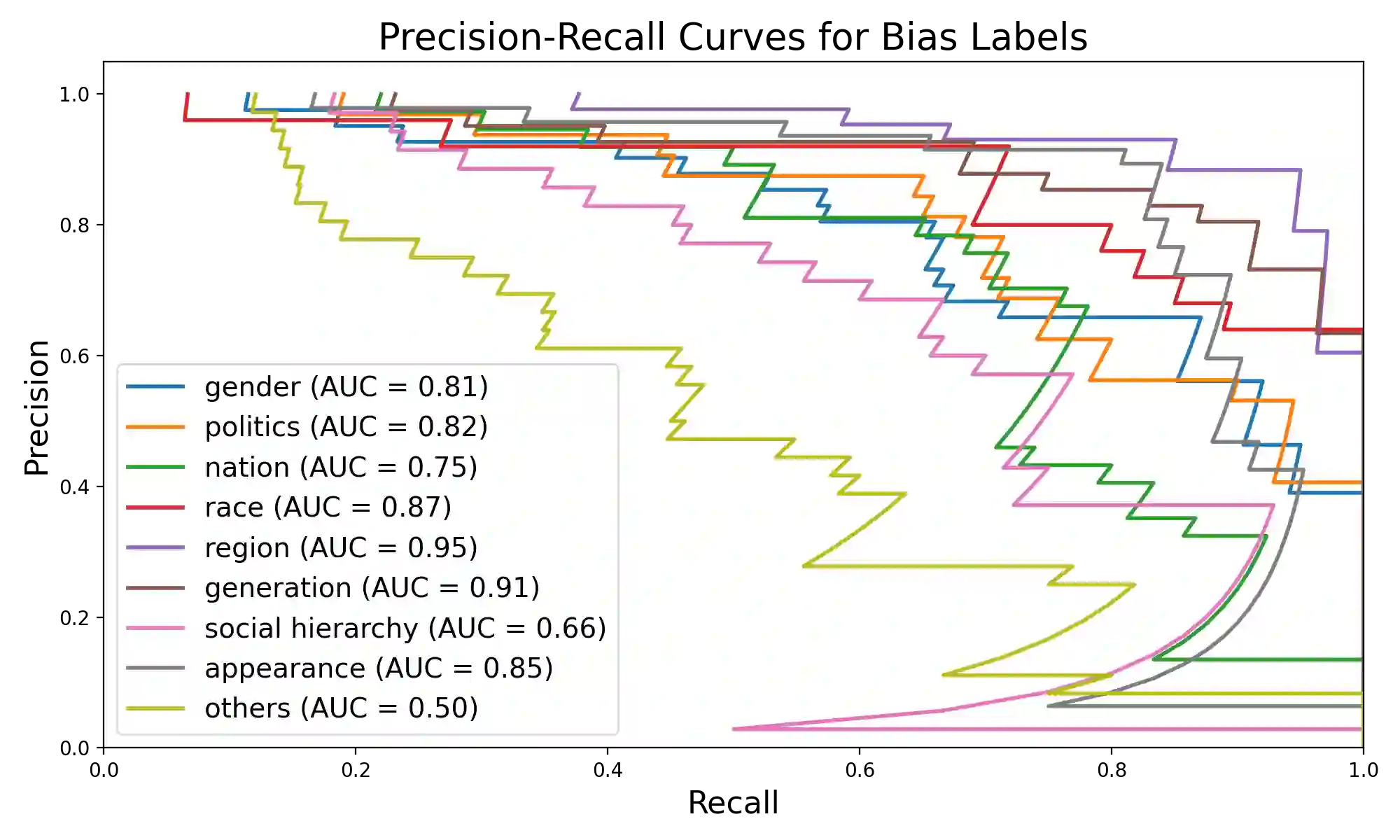
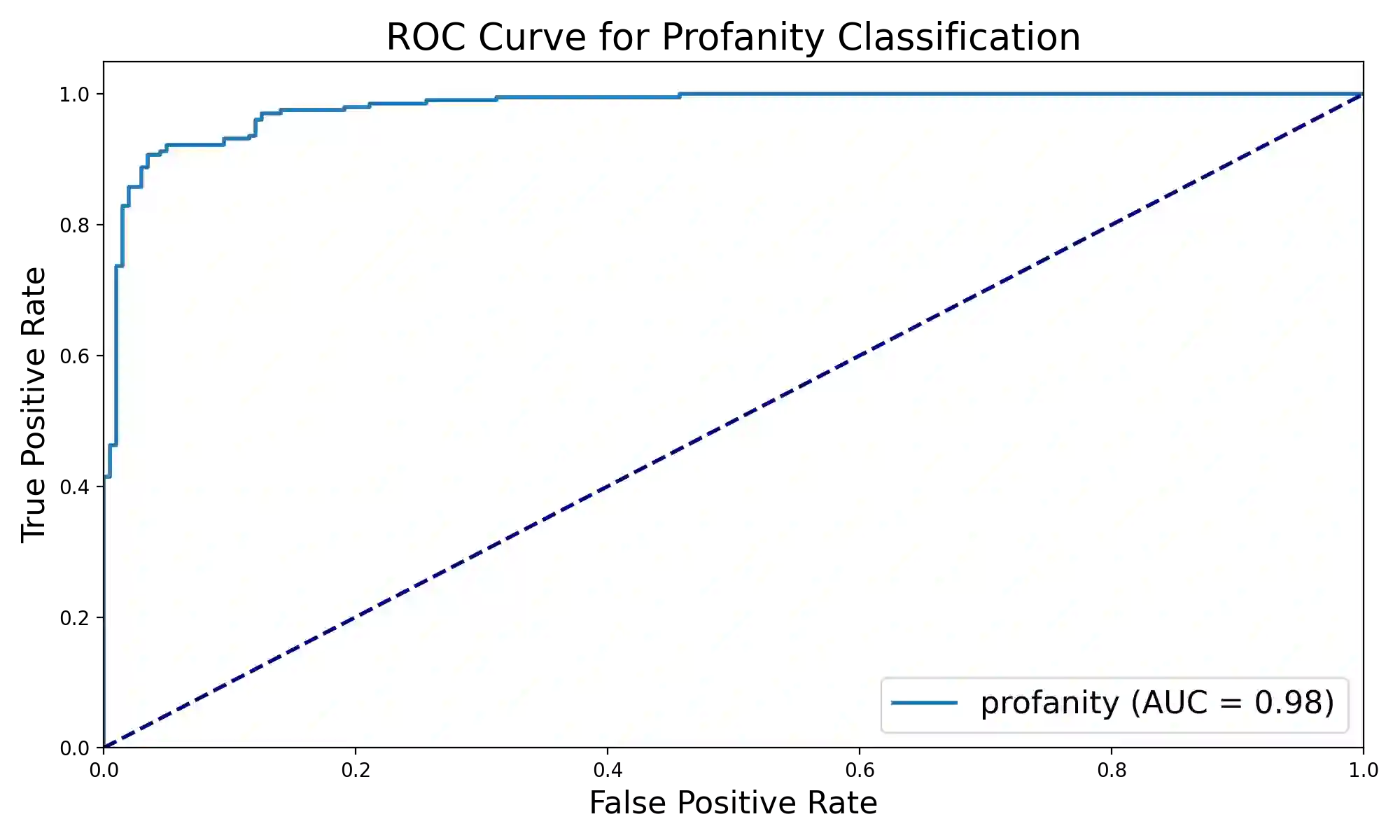
With the growth of online services, the need for advanced text classification algorithms, such as sentiment analysis and biased text detection, has become increasingly evident. The anonymous nature of online services often leads to the presence of biased and harmful language, posing challenges to maintaining the health of online communities. This phenomenon is especially relevant in South Korea, where large-scale hate speech detection algorithms have not yet been broadly explored. In this paper, we introduce a new comprehensive, large-scale dataset collected from a well-known South Korean SNS platform. Our proposed dataset provides annotations including (1) Preferences, (2) Profanities, and (3) Nine types of Bias for the text samples, enabling multi-task learning for simultaneous classification of user-generated texts. Leveraging state-of-the-art BERT-based language models, our approach surpasses human-level accuracy across diverse classification tasks, as measured by various metrics. Beyond academic contributions, our work can provide practical solutions for real-world hate speech and bias mitigation, contributing directly to the improvement of online community health. Our work provides a robust foundation for future research aiming to improve the quality of online discourse and foster societal well-being. All source codes and datasets are publicly accessible at https://github.com/Dasol-Choi/KoMultiText.
翻译:随着在线服务的增长,对情感分析和偏见文本检测等高级文本分类算法的需求日益凸显。在线服务的匿名性常导致偏见性及有害语言的出现,给维护在线社区健康带来挑战。这一现象在韩国尤为突出,而大规模仇恨言论检测算法尚未得到广泛探索。本文介绍了一个从韩国知名社交网络服务平台收集的全新、大规模综合数据集。我们提出的数据集为文本样本提供了包括(1)偏好、(2)辱骂及(3)九种偏见类型在内的标注,支持多任务学习以同时分类用户生成文本。利用基于BERT的最新语言模型,我们的方法在多种分类任务中超越了人类级别的准确率——多项指标均可佐证此结论。除学术贡献外,我们的工作可为真实场景中的仇恨言论与偏见缓解提供实用解决方案,直接助力在线社区健康水平的提升。本研究为未来旨在改善在线话语质量、促进社会福祉的探索奠定了坚实基础。所有源代码和数据集均可通过https://github.com/Dasol-Choi/KoMultiText 公开获取。