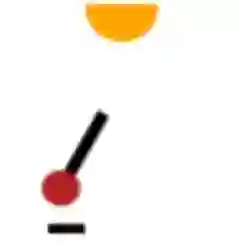
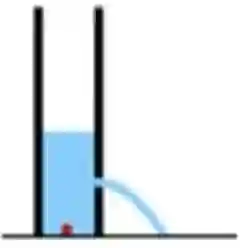
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
翻译:发现语义因素之间的因果关联是表示学习中的一个新兴课题。大多数因果表示学习(CRL)方法采用全监督学习,但由于数据标注成本高昂而难以实际应用。为解决这一限制,弱监督CRL方法被提出。现有四个数据集(Pendulum、Flow、CelebA(BEARD)和CelebA(SMILE))被用于评估CRL性能。然而,现有CRL数据集局限于生成因素较少的简单因果图。为此,我们提出两个包含更多样化生成因素和更复杂因果图的新数据集。此外,当前真实数据集CelebA(BEARD)和CelebA(SMILE)中,最初提出的因果图与数据集分布并不一致,因此我们对其进行了修正。