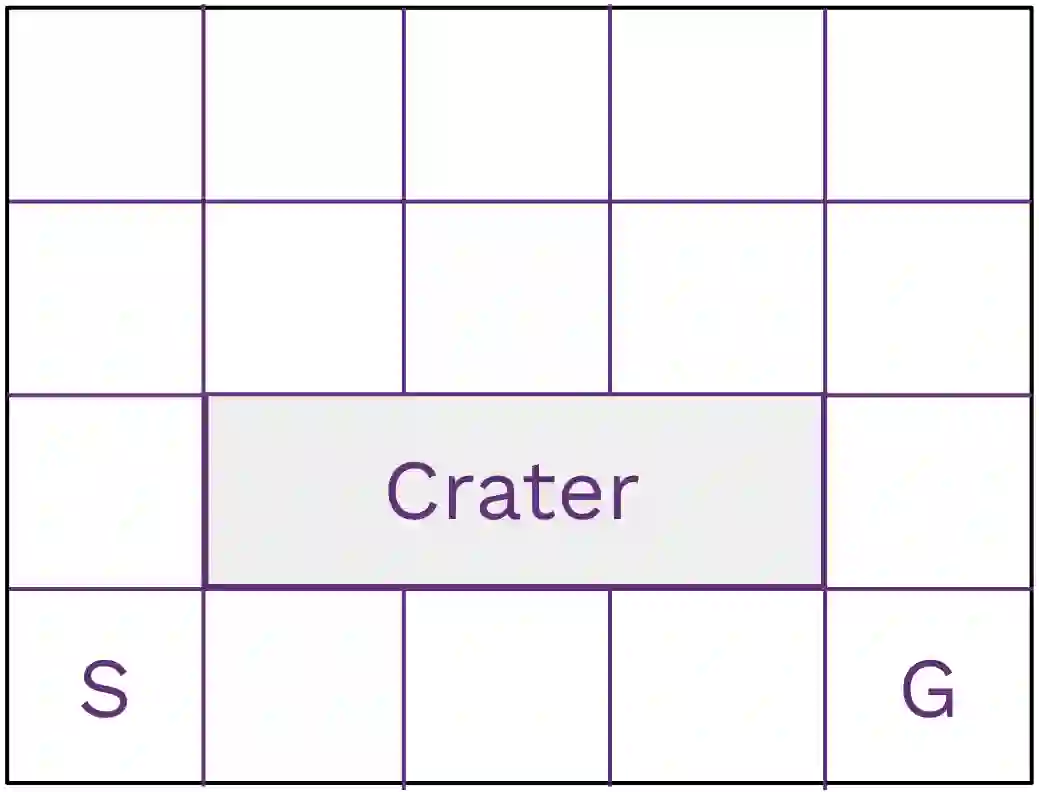
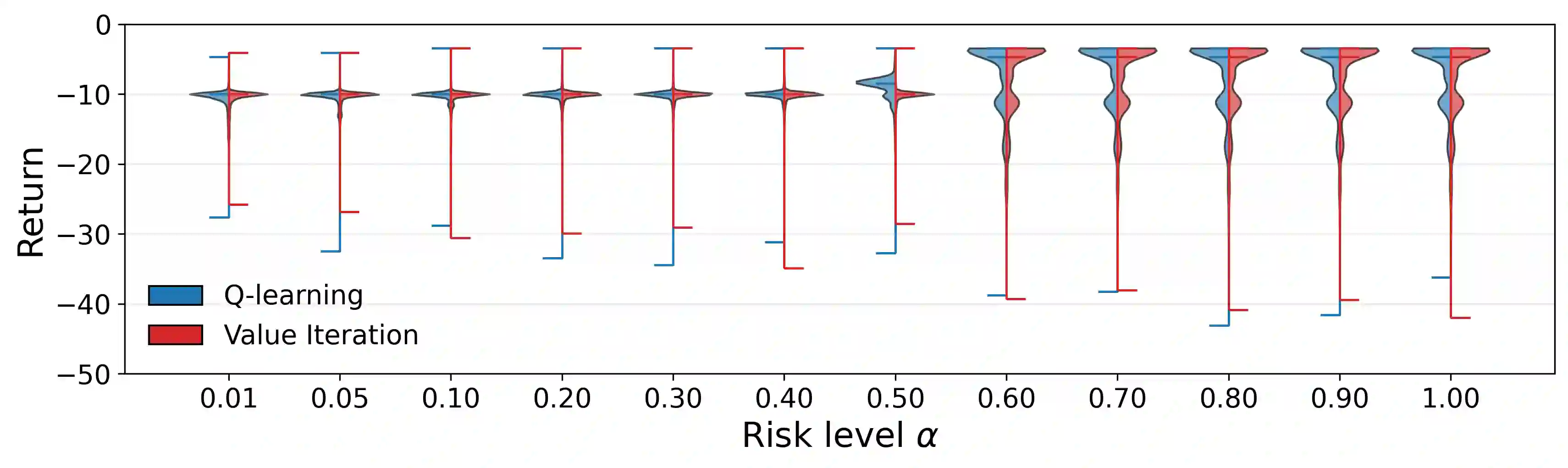
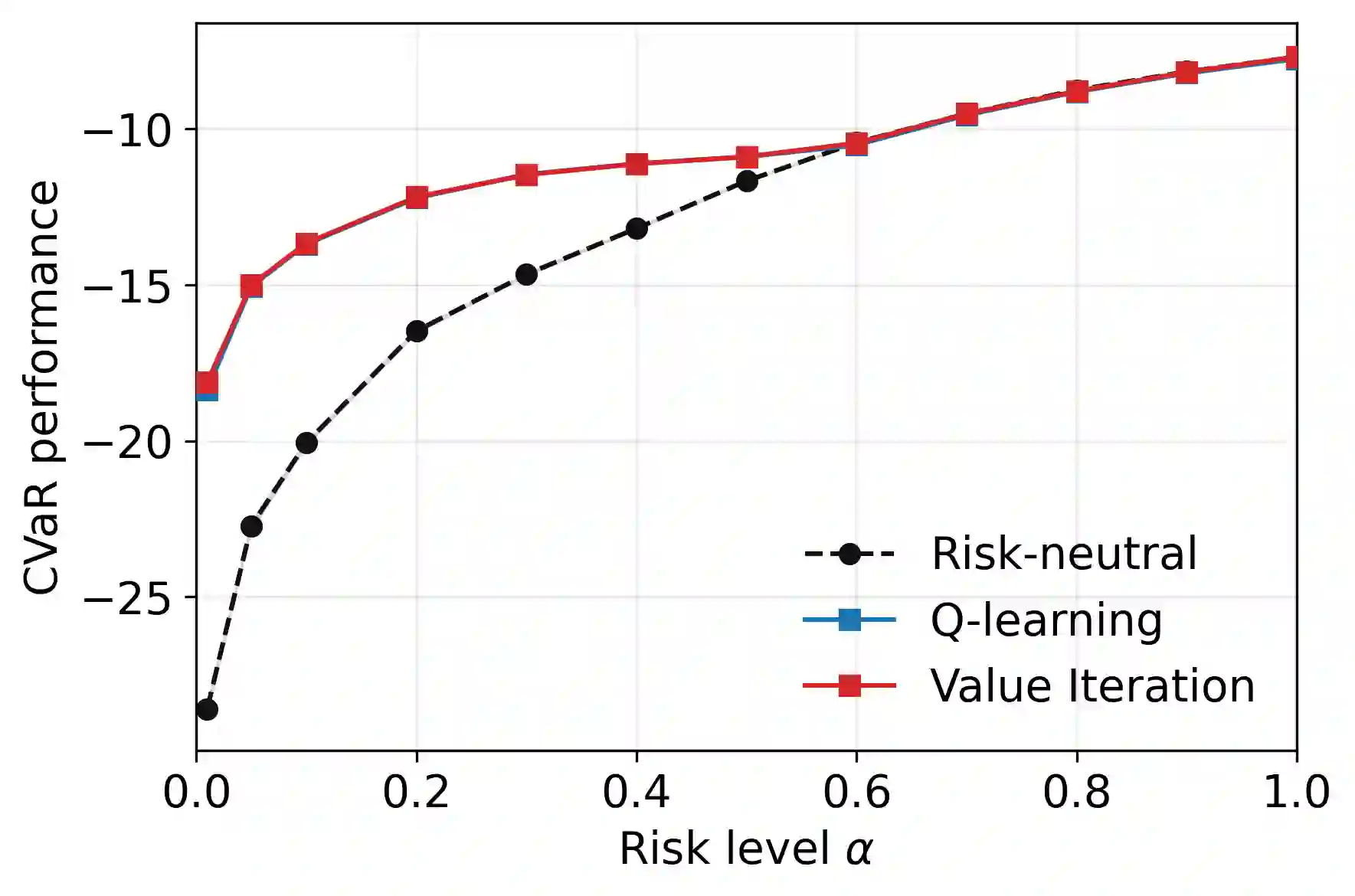
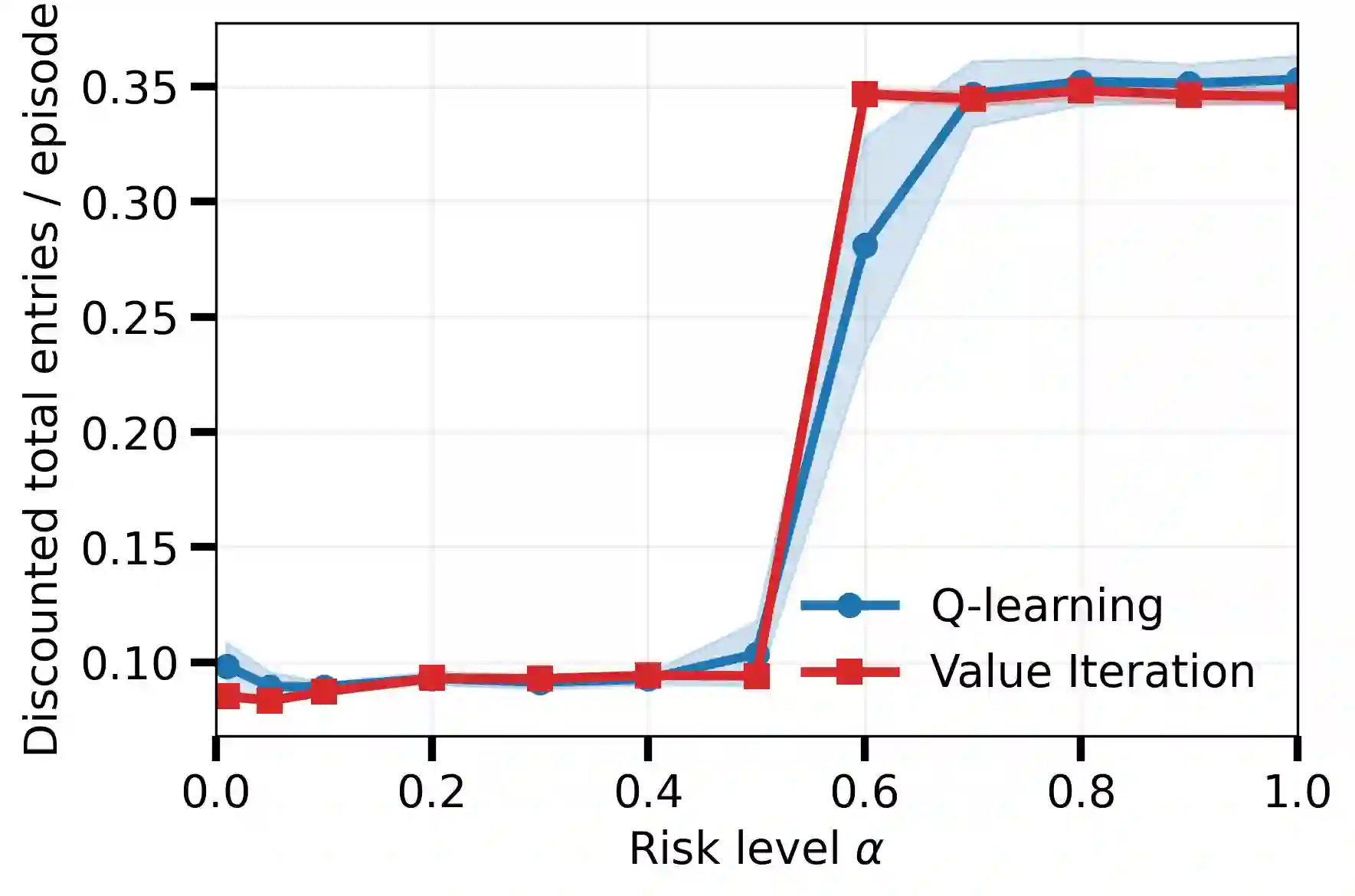
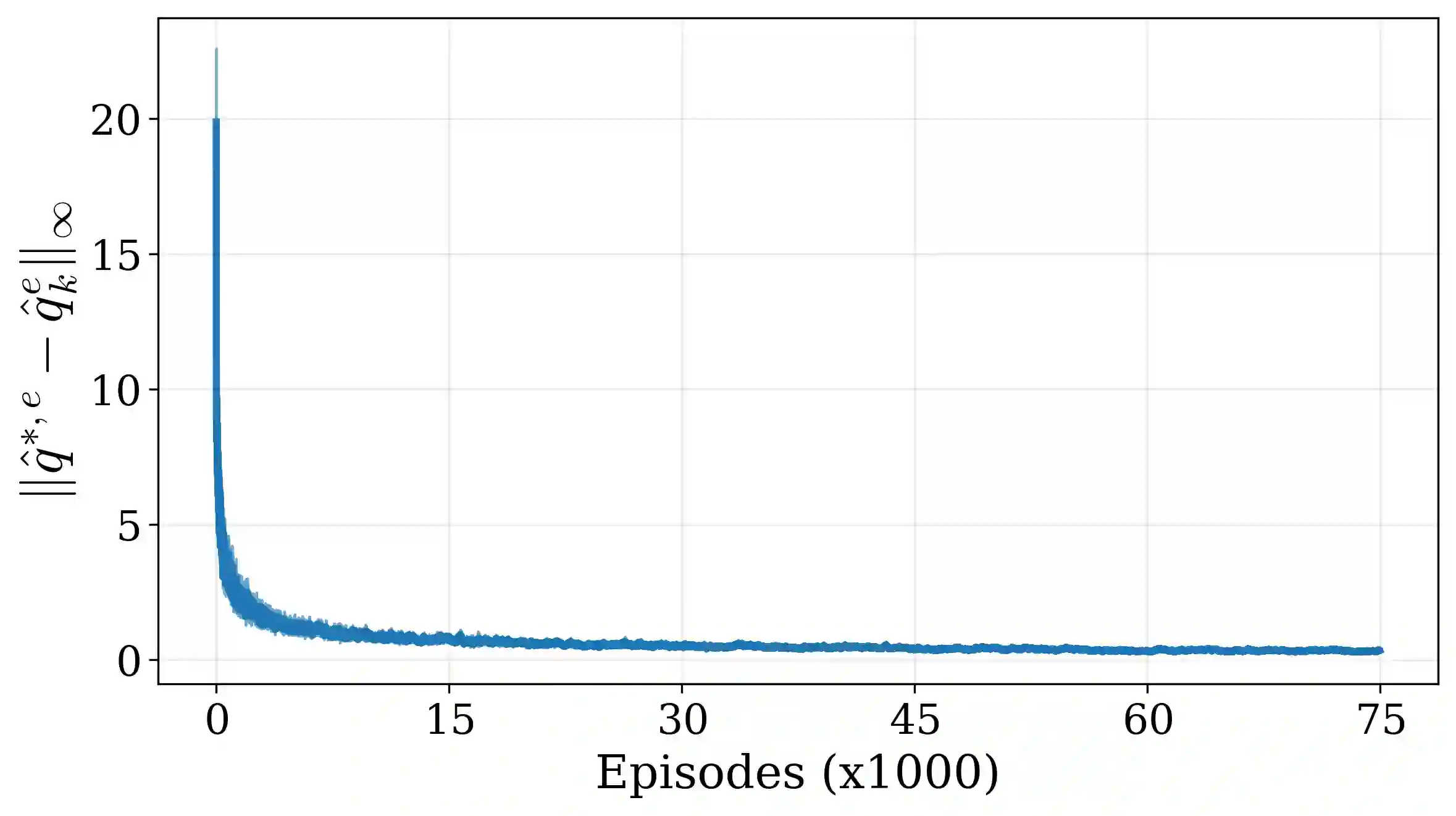
Tail-end risk measures such as static conditional value-at-risk (CVaR) are used in safety-critical applications to prevent rare, yet catastrophic events. Unlike risk-neutral objectives, the static CVaR of the return depends on entire trajectories without admitting a recursive Bellman decomposition in the underlying Markov decision process. A classical resolution relies on state augmentation with a continuous variable. However, unless restricted to a specialized class of admissible value functions, this formulation induces sparse rewards and degenerate fixed points. In this work, we propose a novel formulation of the static CVaR objective based on augmentation. Our alternative approach leads to a Bellman operator with: (1) dense per-step rewards; (2) contracting properties on the full space of bounded value functions. Building on this theoretical foundation, we develop risk-averse value iteration and model-free Q-learning algorithms that rely on discretized augmented states. We further provide convergence guarantees and approximation error bounds due to discretization. Empirical results demonstrate that our algorithms successfully learn CVaR-sensitive policies and achieve effective performance-safety trade-offs.
翻译:在安全关键型应用中,常采用静态条件风险价值(CVaR)等尾部风险度量来预防罕见但灾难性的事件。与风险中性目标不同,回报的静态CVaR依赖于完整轨迹序列,无法在底层马尔可夫决策过程中进行递归式贝尔曼分解。经典解决方案依赖于引入连续变量的状态扩展方法。然而,除非限制在特定类型的可容许值函数范围内,该公式会导致奖励稀疏化和退化不动点问题。本研究提出一种基于状态扩展的静态CVaR目标新公式。我们的替代方法导出的贝尔曼算子具有:(1)密集的逐步奖励;(2)在全有界值函数空间上的压缩特性。基于此理论框架,我们开发了风险规避值迭代算法和无模型Q学习算法,这两种算法均依赖于离散化扩展状态。我们进一步提供了收敛性保证和由离散化引起的近似误差界。实证结果表明,我们的算法能成功学习对CVaR敏感的策略,并实现有效的性能-安全权衡。