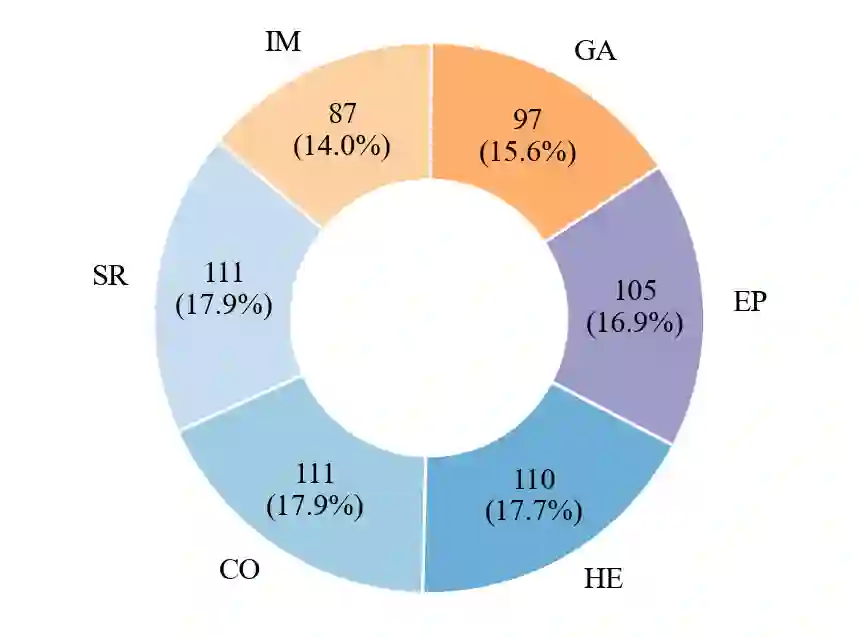
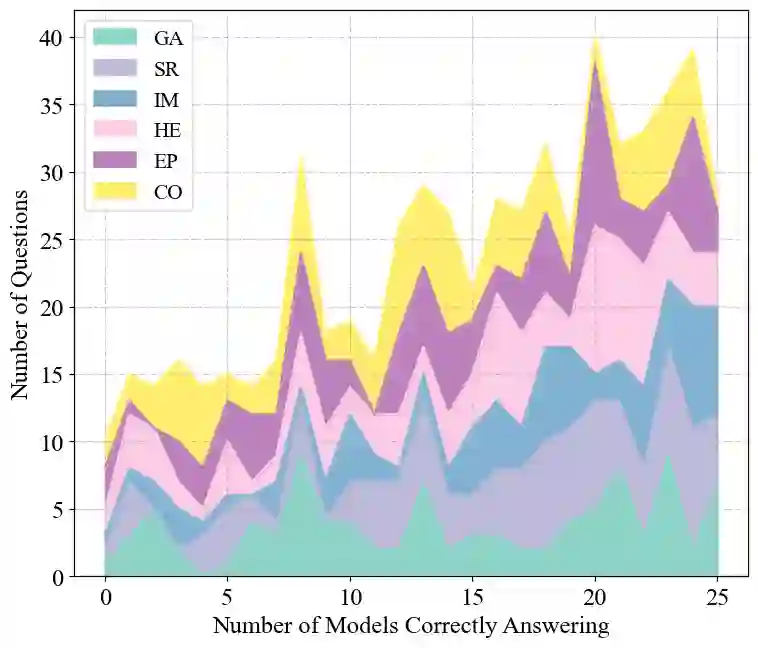
Astronomical image interpretation presents a significant challenge for applying multimodal large language models (MLLMs) to specialized scientific tasks. Existing benchmarks focus on general multimodal capabilities but fail to capture the complexity of astronomical data. To bridge this gap, we introduce AstroMMBench, the first comprehensive benchmark designed to evaluate MLLMs in astronomical image understanding. AstroMMBench comprises 621 multiple-choice questions across six astrophysical subfields, curated and reviewed by 15 domain experts for quality and relevance. We conducted an extensive evaluation of 25 diverse MLLMs, including 22 open-source and 3 closed-source models, using AstroMMBench. The results show that Ovis2-34B achieved the highest overall accuracy (70.5%), demonstrating leading capabilities even compared to strong closed-source models. Performance showed variations across the six astrophysical subfields, proving particularly challenging in domains like cosmology and high-energy astrophysics, while models performed relatively better in others, such as instrumentation and solar astrophysics. These findings underscore the vital role of domain-specific benchmarks like AstroMMBench in critically evaluating MLLM performance and guiding their targeted development for scientific applications. AstroMMBench provides a foundational resource and a dynamic tool to catalyze advancements at the intersection of AI and astronomy.
翻译:天文图像解读是将多模态大语言模型应用于专业科学任务时面临的一项重大挑战。现有基准主要关注通用多模态能力,但未能捕捉天文数据的复杂性。为弥补这一差距,我们推出了AstroMMBench,这是首个旨在评估MLLMs在天文图像理解方面能力的综合性基准。AstroMMBench包含跨越六个天体物理子领域的621道选择题,由15位领域专家精心策划和评审,以确保其质量和相关性。我们使用AstroMMBench对25个不同的MLLMs进行了广泛评估,包括22个开源模型和3个闭源模型。结果显示,Ovis2-34B取得了最高的总体准确率(70.5%),其表现甚至优于强大的闭源模型,展示了领先的能力。模型在六个天体物理子领域的表现存在差异,在宇宙学和高能天体物理等领域尤其具有挑战性,而在仪器学和太阳天体物理等其他领域表现相对较好。这些发现强调了像AstroMMBench这样的领域特定基准在严格评估MLLM性能以及指导其针对科学应用进行针对性开发方面的重要作用。AstroMMBench为促进人工智能与天文学交叉领域的进步提供了一个基础性资源和动态工具。