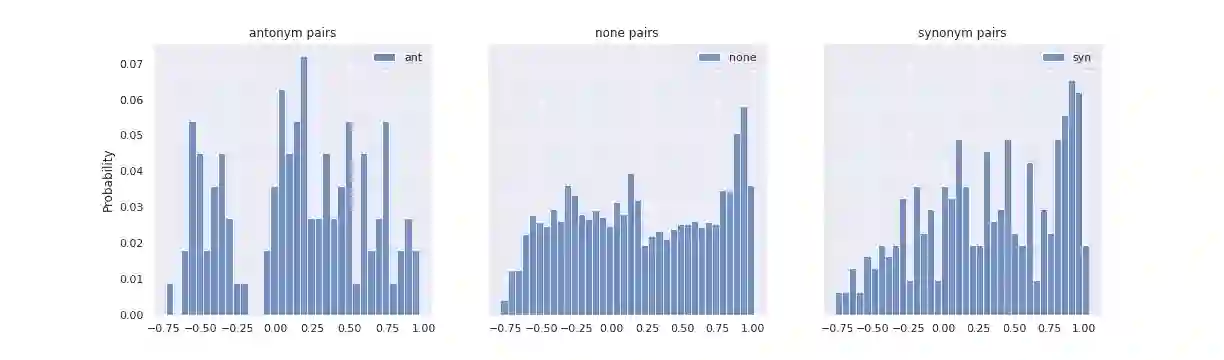
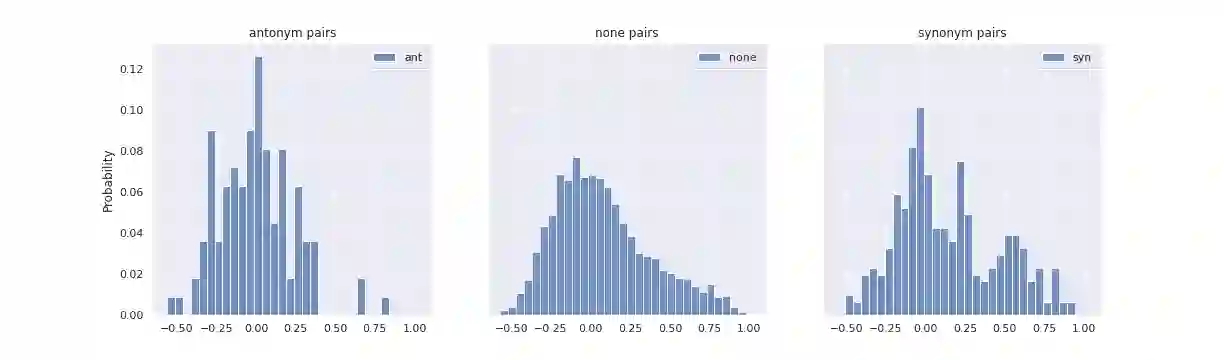
The Linguistic Matrix Theory programme introduced by Kartsaklis, Ramgoolam and Sadrzadeh is an approach to the statistics of matrices that are generated in type-driven distributional semantics, based on permutation invariant polynomial functions which are regarded as the key observables encoding the significant statistics. In this paper we generalize the previous results on the approximate Gaussianity of matrix distributions arising from compositional distributional semantics. We also introduce a geometry of observable vectors for words, defined by exploiting the graph-theoretic basis for the permutation invariants and the statistical characteristics of the ensemble of matrices associated with the words. We describe successful applications of this unified framework to a number of tasks in computational linguistics, associated with the distinctions between synonyms, antonyms, hypernyms and hyponyms.
翻译:由Kartsaklis、Ramgoolam和Sadrzadeh提出的语言矩阵理论纲领,是一种基于置换不变多项式函数的矩阵统计方法,这些多项式函数被视为编码重要统计量的关键可观测量,应用于类型驱动分布语义学中生成的矩阵统计研究。本文推广了先前关于组合分布语义学中矩阵分布近似高斯性的结论,并利用置换不变量的图论基础以及与词汇关联的矩阵系综统计特征,引入了词汇可观测量向量几何。我们描述了该统一框架在计算语言学多项任务中的成功应用,包括同义词、反义词、上义词和下义词的区分。