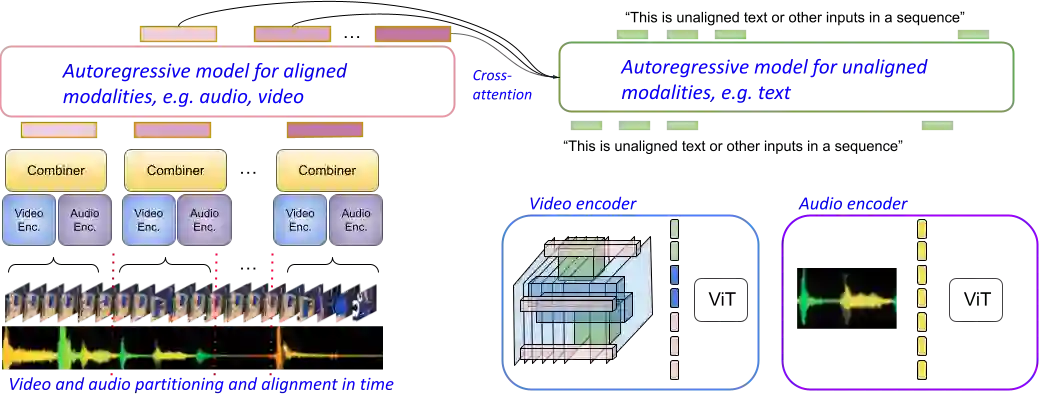
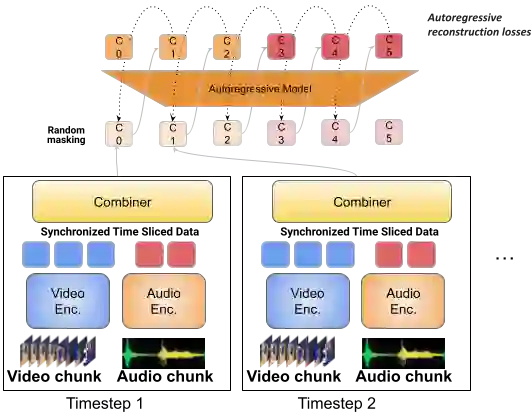
One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
翻译:多模态学习的主要挑战之一在于需要整合异质模态(如视频、音频、文本)。例如,视频和音频的获取频率远高于文本,且大致在时间上对齐。但它们通常与作为全局上下文(如标题或描述)的文本不同步。此外,视频和音频输入的数据量更大,且随视频时长增加而增长,这自然需要为这些模态分配更多计算资源,并使得长程依赖建模更加困难。我们在此解耦多模态建模,将其分解为多个独立的、专注的自回归模型,并根据模态特性处理输入。我们提出一种名为Mirasol3B的多模态模型,它包含一个用于时间同步模态(音频和视频)的自回归组件,以及一个用于上下文模态(不一定在时间上对齐但仍为序列形式)的自回归组件。为处理视频-音频输入的长序列问题,我们进一步将视频和音频序列划分为连续片段,并对其表征进行自回归处理。为此,我们提出一种组合器机制,可在时间帧内联合建模音频-视频信息。该组合器从原始时空信号中学习提取音频和视频特征,进而学习融合这些特征,为每个片段生成紧凑且富有表现力的表征。我们的方法在多个成熟的多模态基准测试中达到最先进水平,超越了规模更大的模型。它通过学习紧凑表征、控制音频-视频特征表征的序列长度以及建模其时序依赖关系,有效应对了媒体输入的高计算需求。