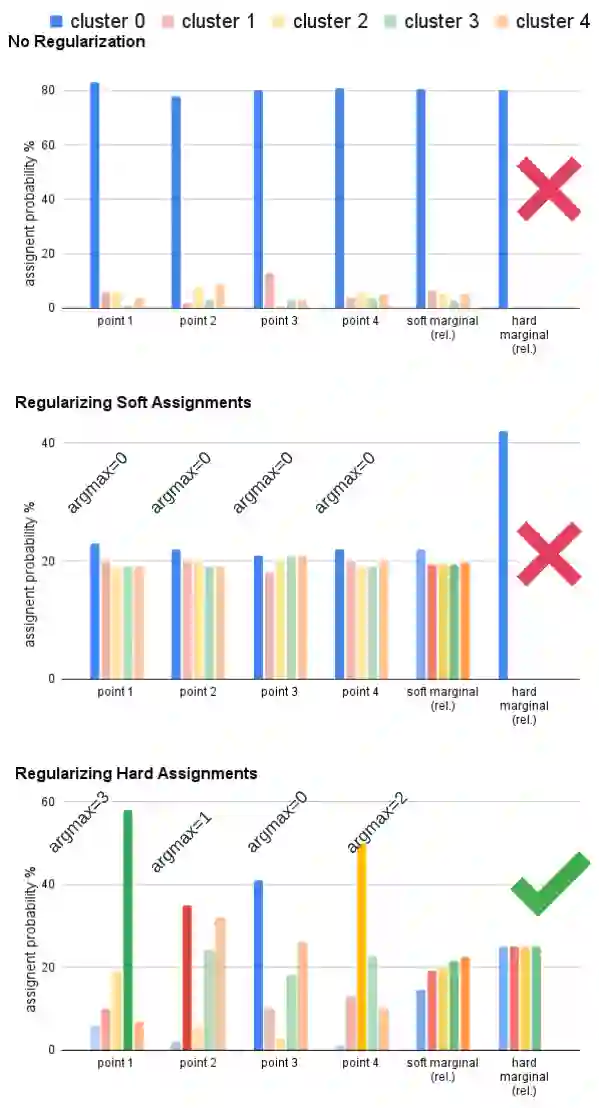
Online deep clustering refers to the joint use of a feature extraction network and a clustering model to assign cluster labels to each new data point or batch as it is processed. While faster and more versatile than offline methods, online clustering can easily reach the collapsed solution where the encoder maps all inputs to the same point and all are put into a single cluster. Successful existing models have employed various techniques to avoid this problem, most of which require data augmentation or which aim to make the average soft assignment across the dataset the same for each cluster. We propose a method that does not require data augmentation, and that, differently from existing methods, regularizes the hard assignments. Using a Bayesian framework, we derive an intuitive optimization objective that can be straightforwardly included in the training of the encoder network. Tested on four image datasets and one human-activity recognition dataset, it consistently avoids collapse more robustly than other methods and leads to more accurate clustering. We also conduct further experiments and analyses justifying our choice to regularize the hard cluster assignments. Code is available at https://github.com/Lou1sM/online_hard_clustering.
翻译:在线深度聚类是指在处理每个新数据点或批数据时,联合使用特征提取网络和聚类模型来分配聚类标签。虽然其速度比离线方法更快且适用范围更广,但在线聚类极易陷入坍塌解——即编码器将所有输入映射至同一点,使所有样本归入单一聚类。现有成功模型采用多种技术避免该问题,多数需要数据增强,或旨在使数据集的平均软分配在各类间保持均匀。我们提出一种无需数据增强的方法,与现有方法不同,该方法对硬分配进行正则化。基于贝叶斯框架,我们推导出一个直观的优化目标,可简洁地整合至编码器网络训练中。在四个图像数据集和一个人类活动识别数据集上的测试表明,该方法能比其他方法更稳健地避免坍塌,并实现更精确的聚类。我们通过进一步实验与分析,验证了对硬聚类分配进行正则化的合理性。代码见 https://github.com/Lou1sM/online_hard_clustering。