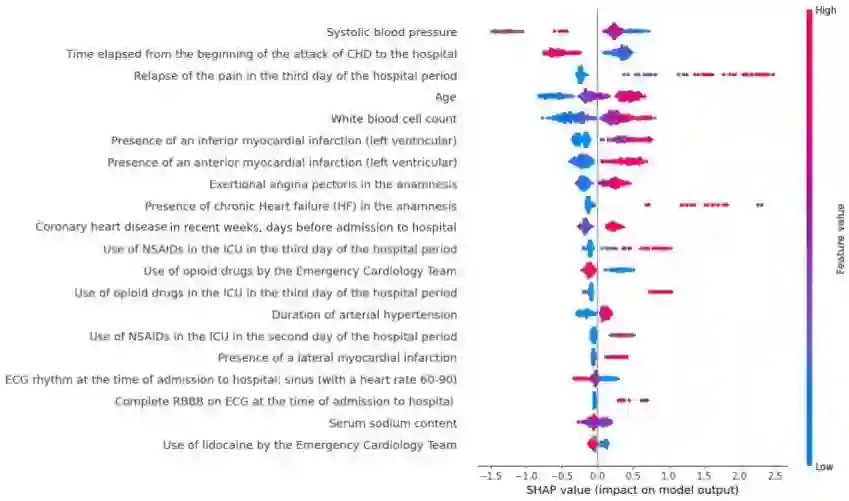
Myocardial Infarction is a main cause of mortality globally, and accurate risk prediction is crucial for improving patient outcomes. Machine Learning techniques have shown promise in identifying high-risk patients and predicting outcomes. However, patient data often contain vast amounts of information and missing values, posing challenges for feature selection and imputation methods. In this article, we investigate the impact of the data preprocessing task and compare three ensembles boosted tree methods to predict the risk of mortality in patients with myocardial infarction. Further, we use the Tree Shapley Additive Explanations method to identify relationships among all the features for the performed predictions, leveraging the entirety of the available data in the analysis. Notably, our approach achieved a superior performance when compared to other existing machine learning approaches, with an F1-score of 91,2% and an accuracy of 91,8% for LightGBM without data preprocessing.
翻译:心肌梗死是全球范围内的主要死亡原因,准确的风险预测对改善患者预后至关重要。机器学习技术在识别高风险患者和预测结局方面已展现出潜力。然而,患者数据通常包含大量信息和缺失值,这给特征选择和缺失值填补方法带来了挑战。本文研究了数据预处理任务的影响,并比较了三种集成提升树方法以预测心肌梗死患者的死亡风险。此外,我们采用树形沙普利加法解释方法,利用分析中所有可用数据,识别预测结果与所有特征间的关系。值得注意的是,与现有其他机器学习方法相比,我们的方法在未进行数据预处理的LightGBM上取得了优异性能,F1分数达91.2%,准确率达91.8%。