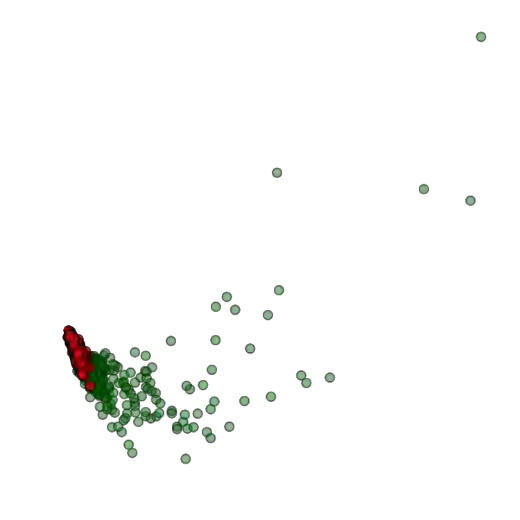
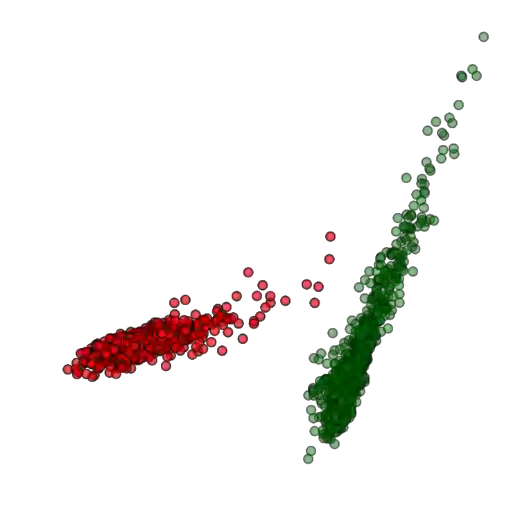
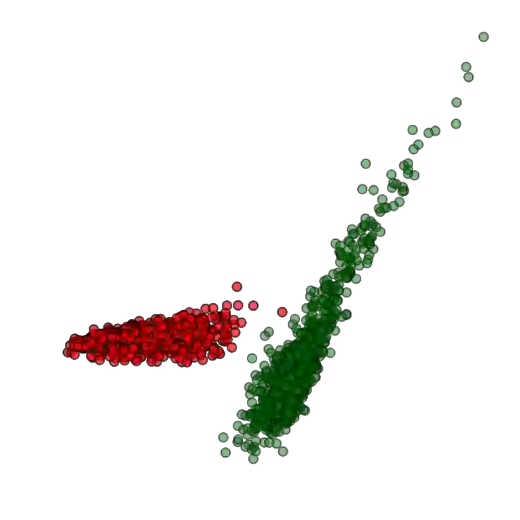
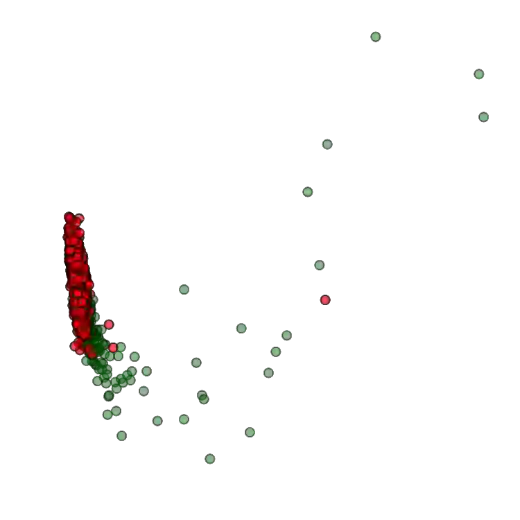
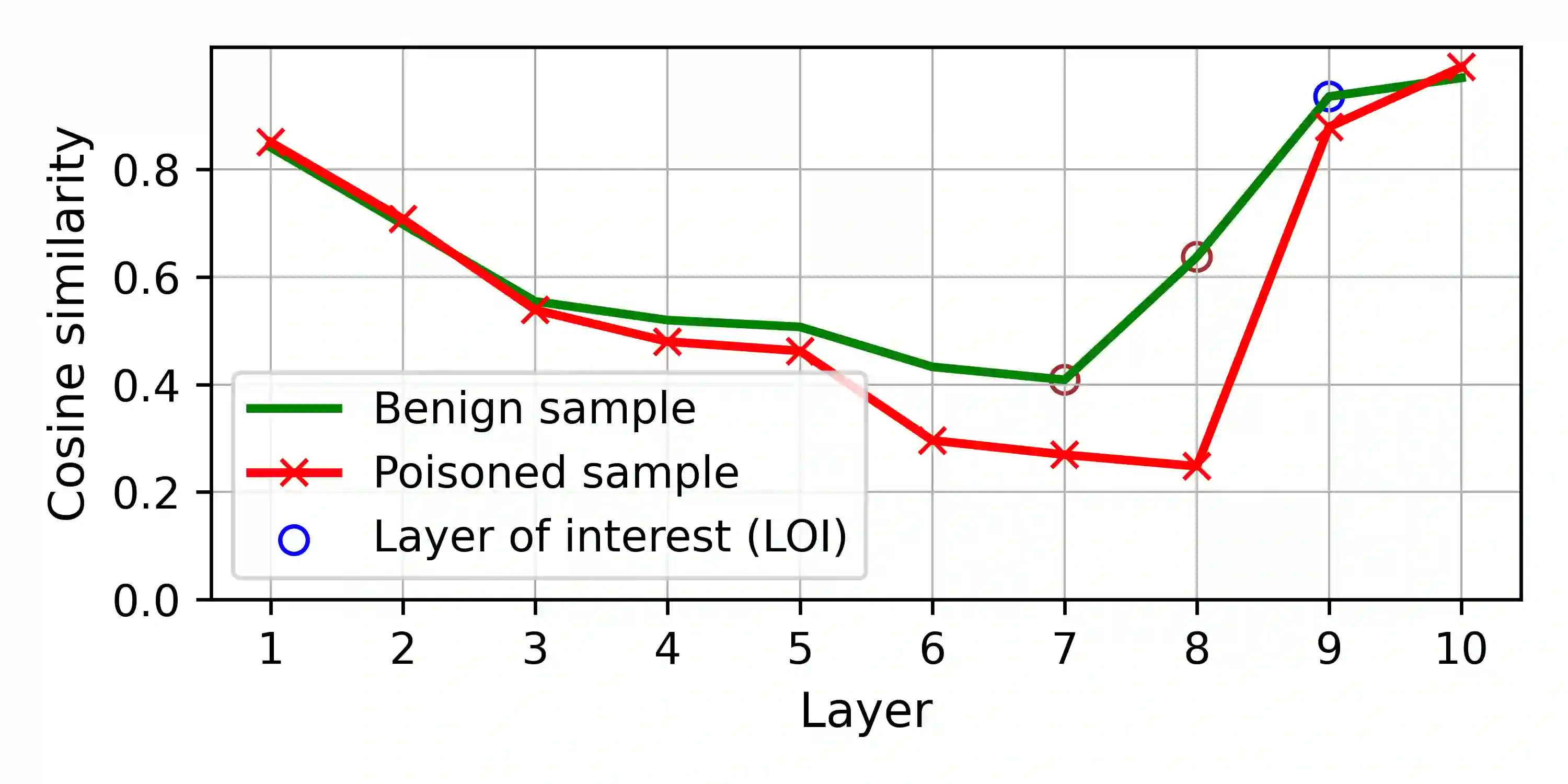
Training deep neural networks (DNNs) usually requires massive training data and computational resources. Users who cannot afford this may prefer to outsource training to a third party or resort to publicly available pre-trained models. Unfortunately, doing so facilitates a new training-time attack (i.e., backdoor attack) against DNNs. This attack aims to induce misclassification of input samples containing adversary-specified trigger patterns. In this paper, we first conduct a layer-wise feature analysis of poisoned and benign samples from the target class. We find out that the feature difference between benign and poisoned samples tends to be maximum at a critical layer, which is not always the one typically used in existing defenses, namely the layer before fully-connected layers. We also demonstrate how to locate this critical layer based on the behaviors of benign samples. We then propose a simple yet effective method to filter poisoned samples by analyzing the feature differences between suspicious and benign samples at the critical layer. We conduct extensive experiments on two benchmark datasets, which confirm the effectiveness of our defense.
翻译:训练深度神经网络(DNN)通常需要大量的训练数据和计算资源。无法承担这一成本的用户可能倾向于将训练外包给第三方,或使用公开可用的预训练模型。然而,这种做法为针对DNN的新型训练时攻击(即后门攻击)提供了便利。此类攻击旨在诱导包含攻击者指定触发模式的输入样本发生误分类。本文首先对目标类别的恶意样本和良性样本进行逐层特征分析。我们发现,良性样本与恶意样本之间的特征差异在某个关键层达到最大值,而该层并非总是现有防御方法中通常使用的层(即全连接层之前的层)。我们还展示了如何基于良性样本的行为来定位此关键层。随后,我们提出一种简单而有效的方法,通过在关键层分析可疑样本与良性样本之间的特征差异来过滤恶意样本。我们在两个基准数据集上进行了大量实验,证实了所提防御方法的有效性。