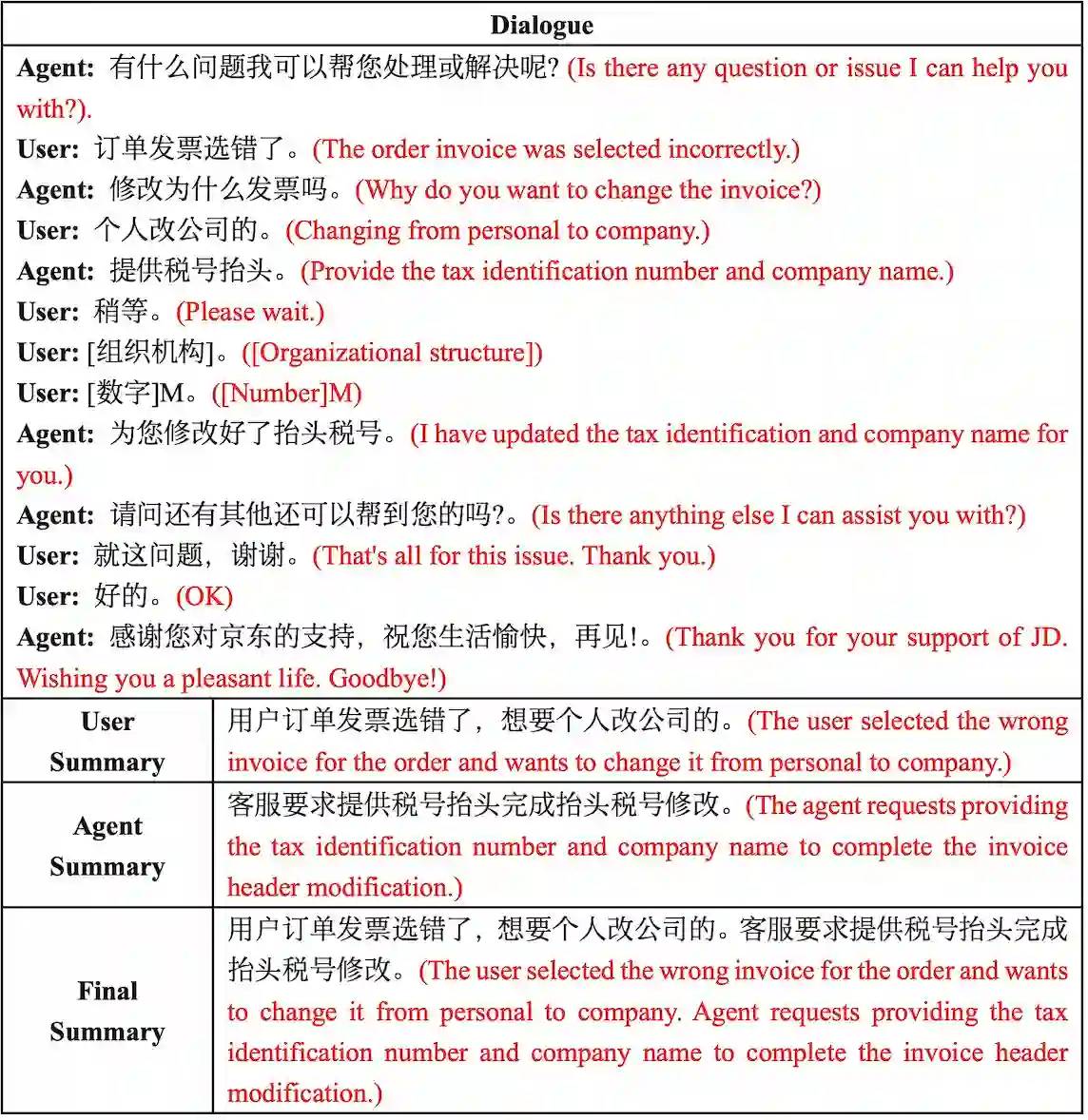
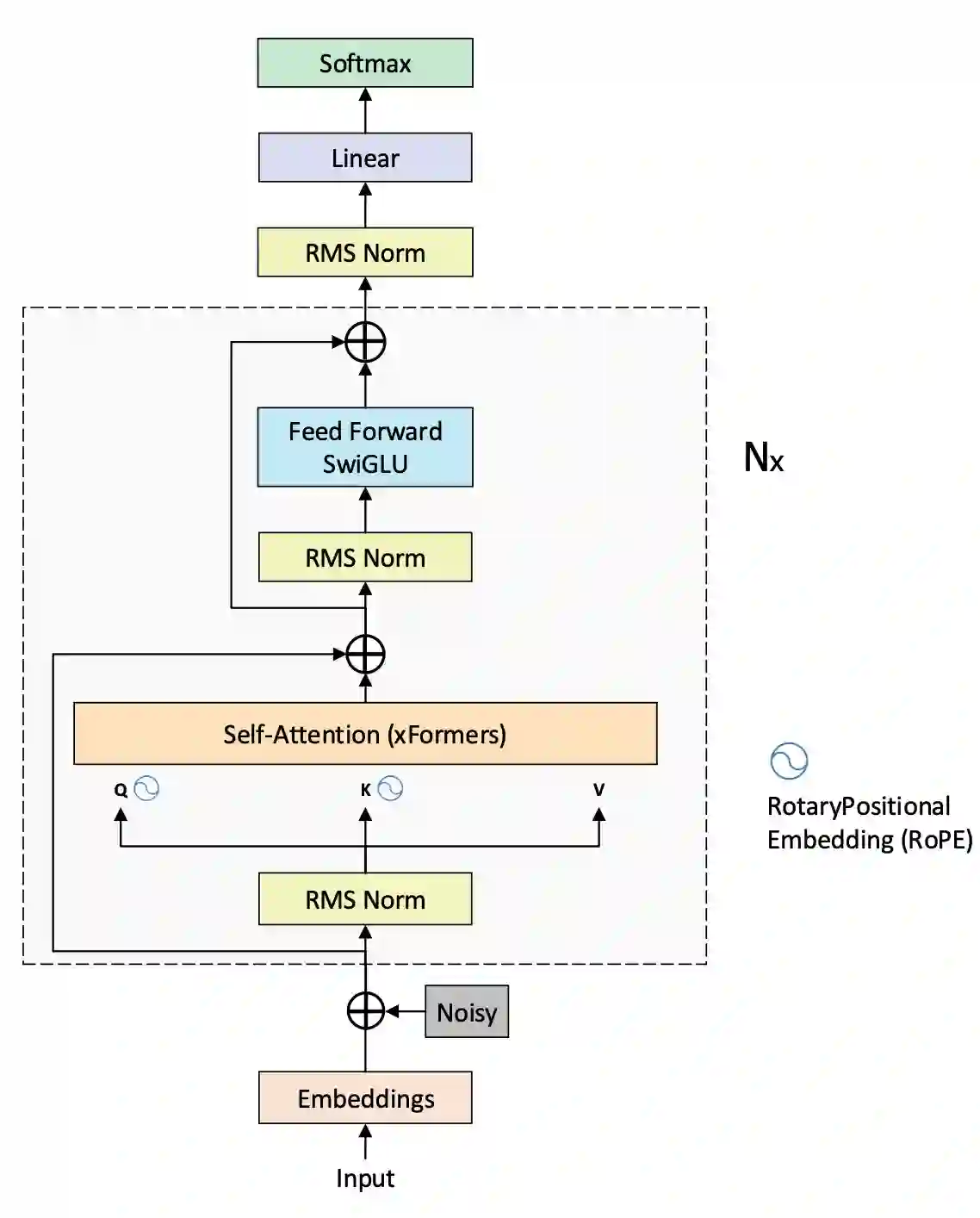
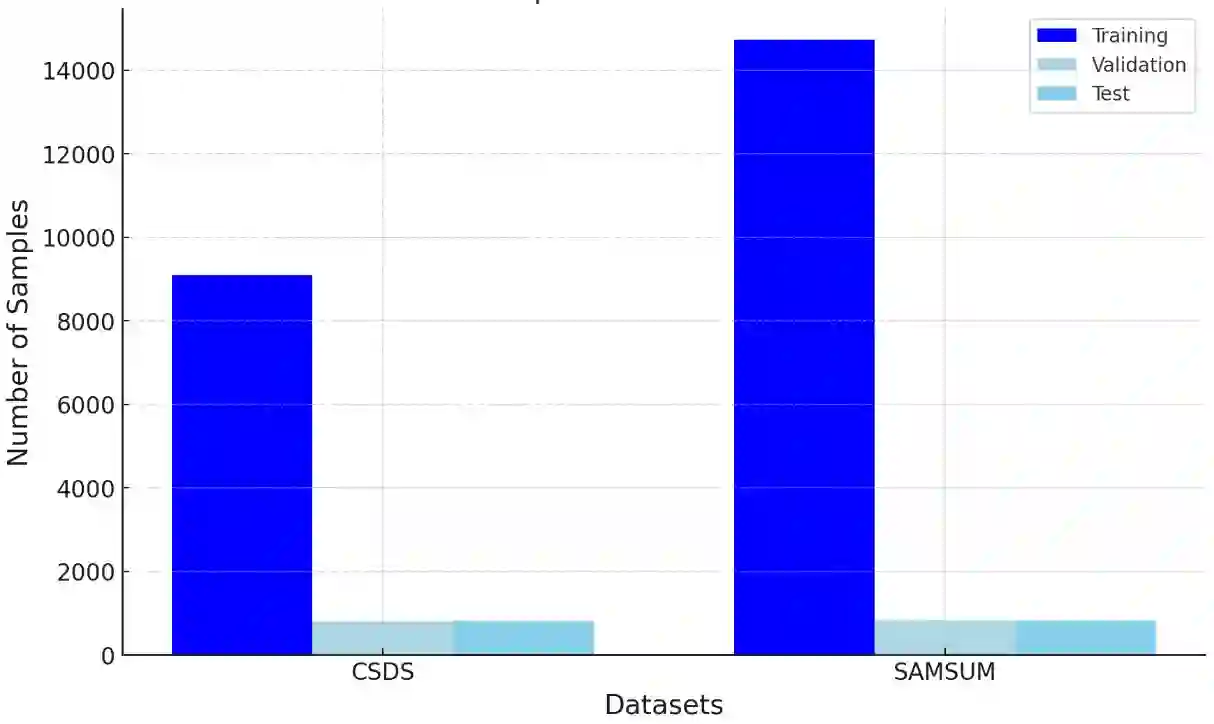
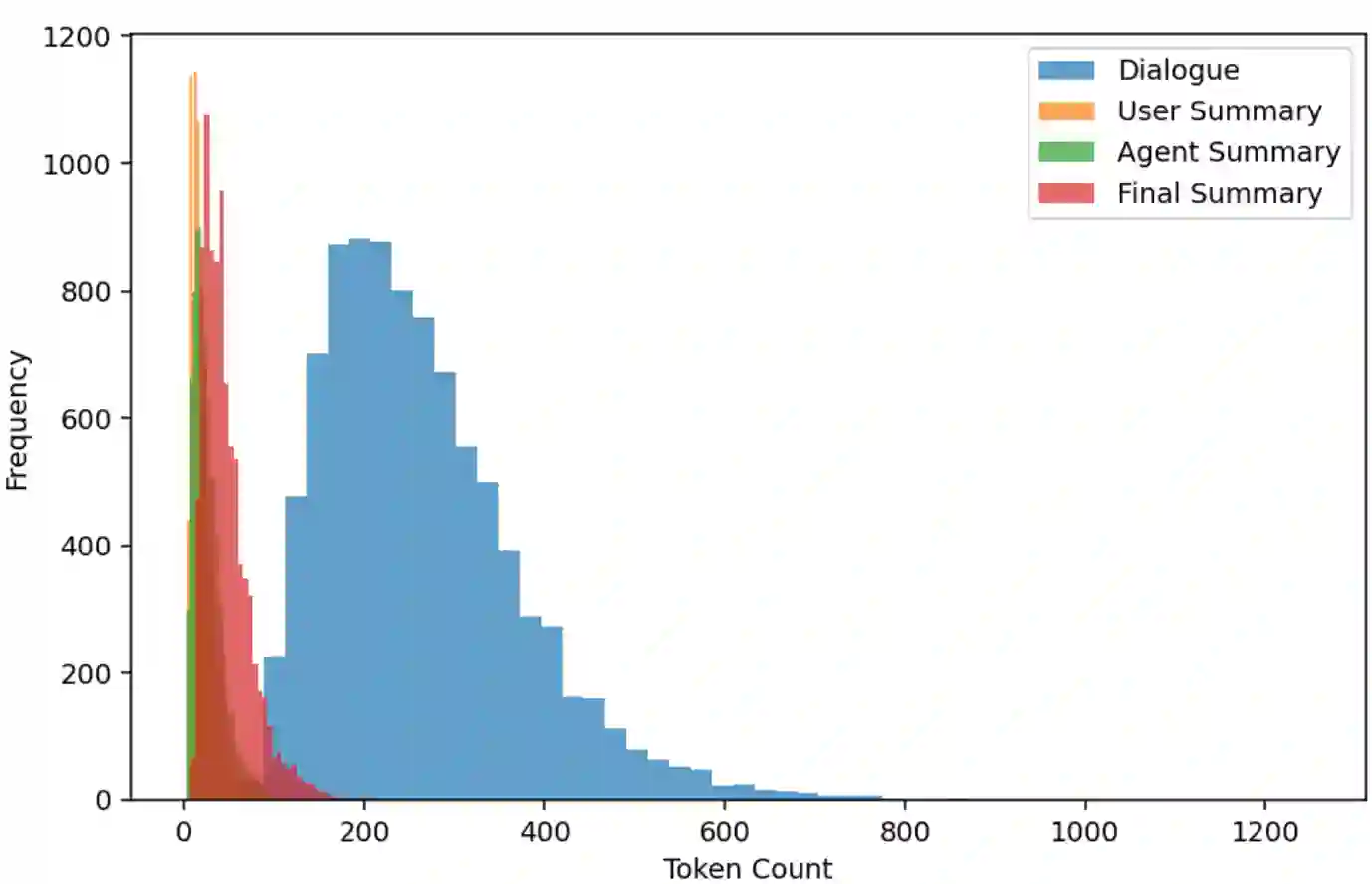
Large language models (LLMs) like Llama, Baichuan and Bloom models show remarkable ability with instruction fine-tuning in many natural language tasks. Nevertheless, for the dialogue summarization task, which aims to generate summaries for different roles in dialogue, most of the state-of-the-art methods conduct on small models (e.g Bart and Bert). Existing methods try to add task specified optimization on small models like adding global-local centrality score to models. In this paper, we propose an instruction fine-tuning model: Baichuan2-Sum, for role-oriented diaglouge summarization. By setting different instructions for different roles, the model can learn from the dialogue interactions and output the expected summaries. Furthermore, we applied NEFTune technique to add suitable noise during training to improve the results. The experiments demonstrate that the proposed model achieves the new state-of-the-art results on two public dialogue summarization datasets: CSDS and SAMSUM. We release our model and related codes to facilitate future studies on dialogue summarization task.
翻译:像Llama、Baichuan和Bloom这样的大语言模型(LLMs)在众多自然语言任务中凭借指令微调展现了卓越的能力。然而,在对话摘要任务(旨在为对话中不同角色生成摘要)中,现有最先进的方法大多基于小模型(如BART和BERT)。现有方法尝试在小模型上添加任务特定优化,例如引入全局-局部中心性分数。本文提出了一种面向角色导向对话摘要的指令微调模型:Baichuan2-Sum。通过为不同角色设置不同指令,该模型能够从对话交互中学习,并输出预期的摘要。此外,我们应用了NEFTune技术,在训练过程中添加合适的噪声以提升结果。实验表明,所提模型在两个公开对话摘要数据集CSDS和SAMSUM上取得了新的最优结果。我们发布了模型及相关代码,以促进未来对对话摘要任务的研究。