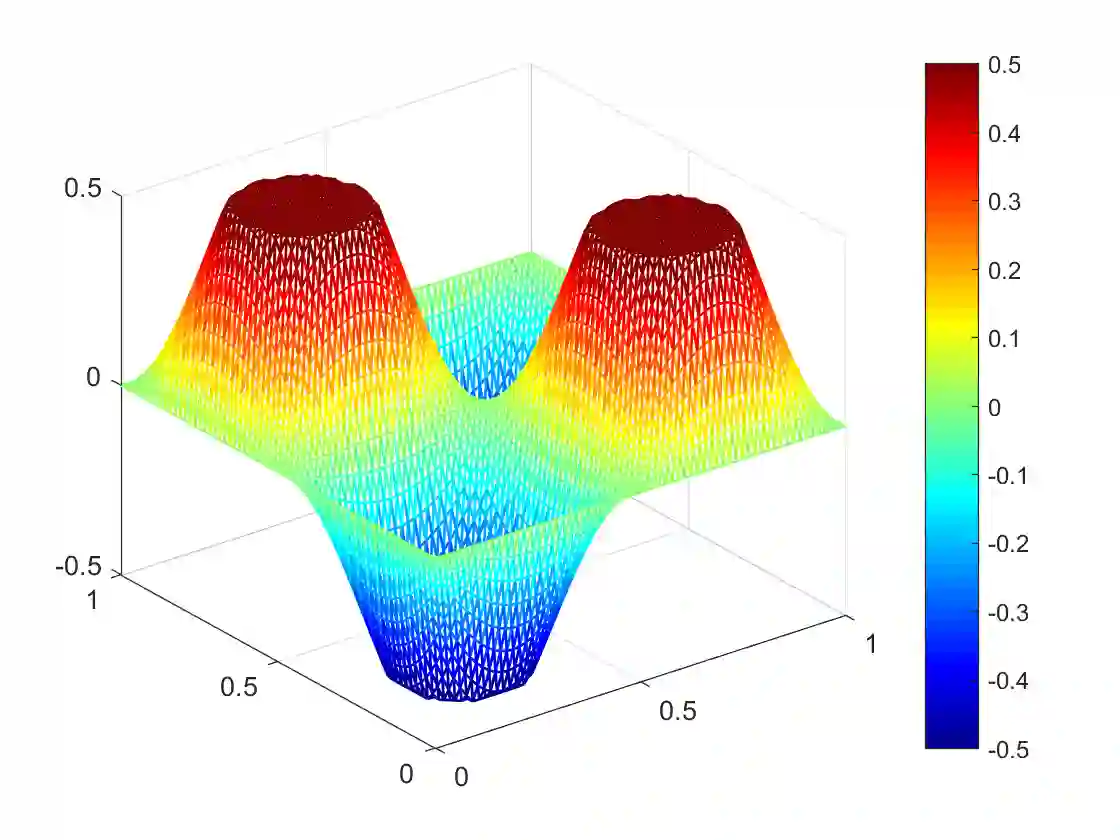
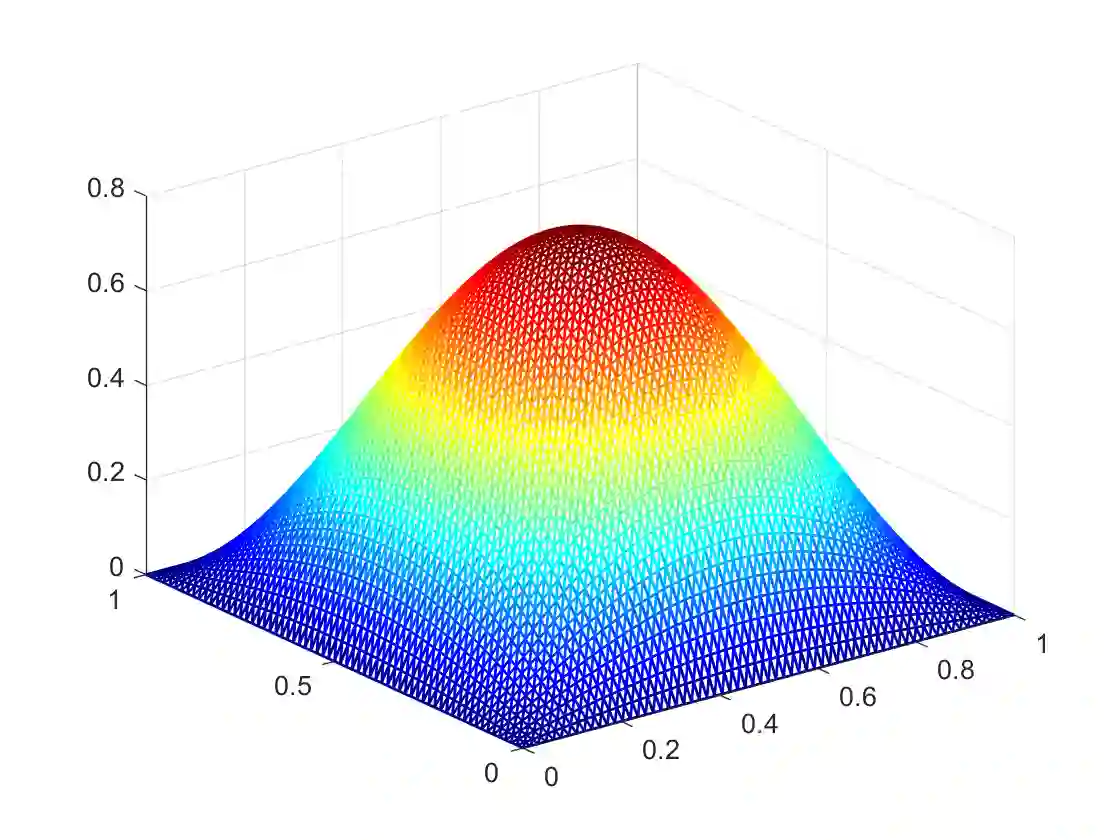
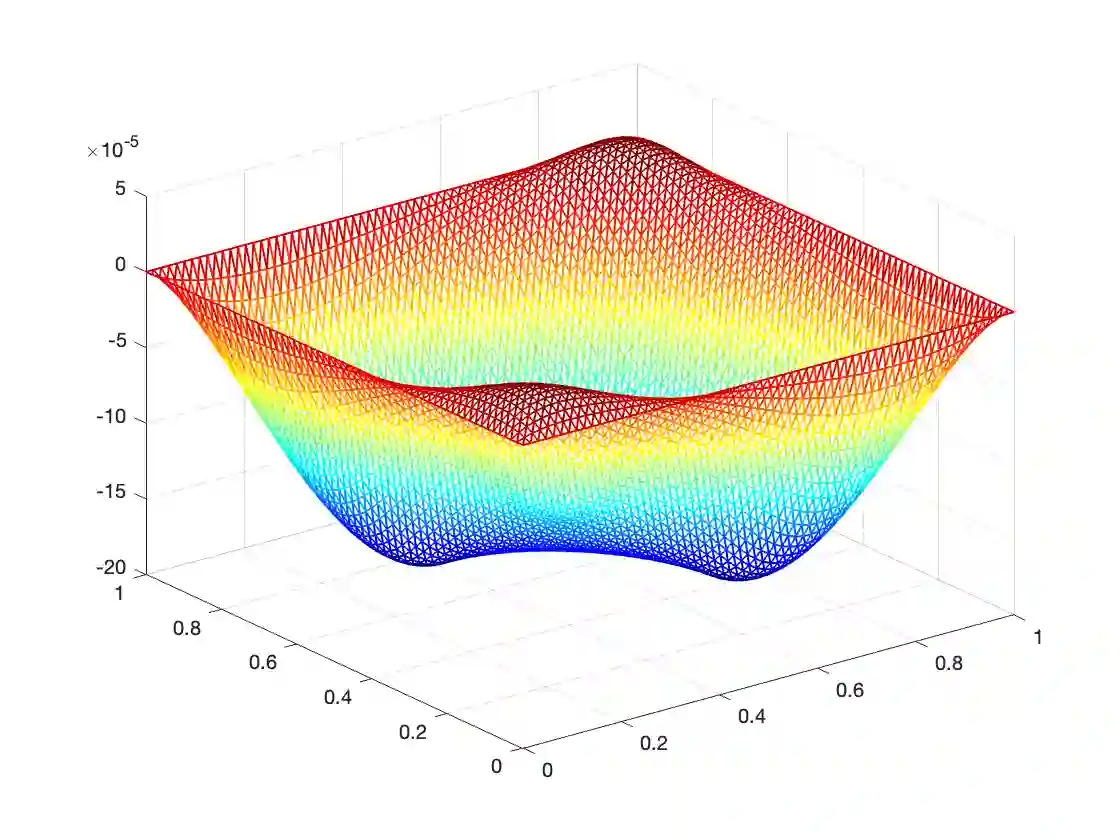
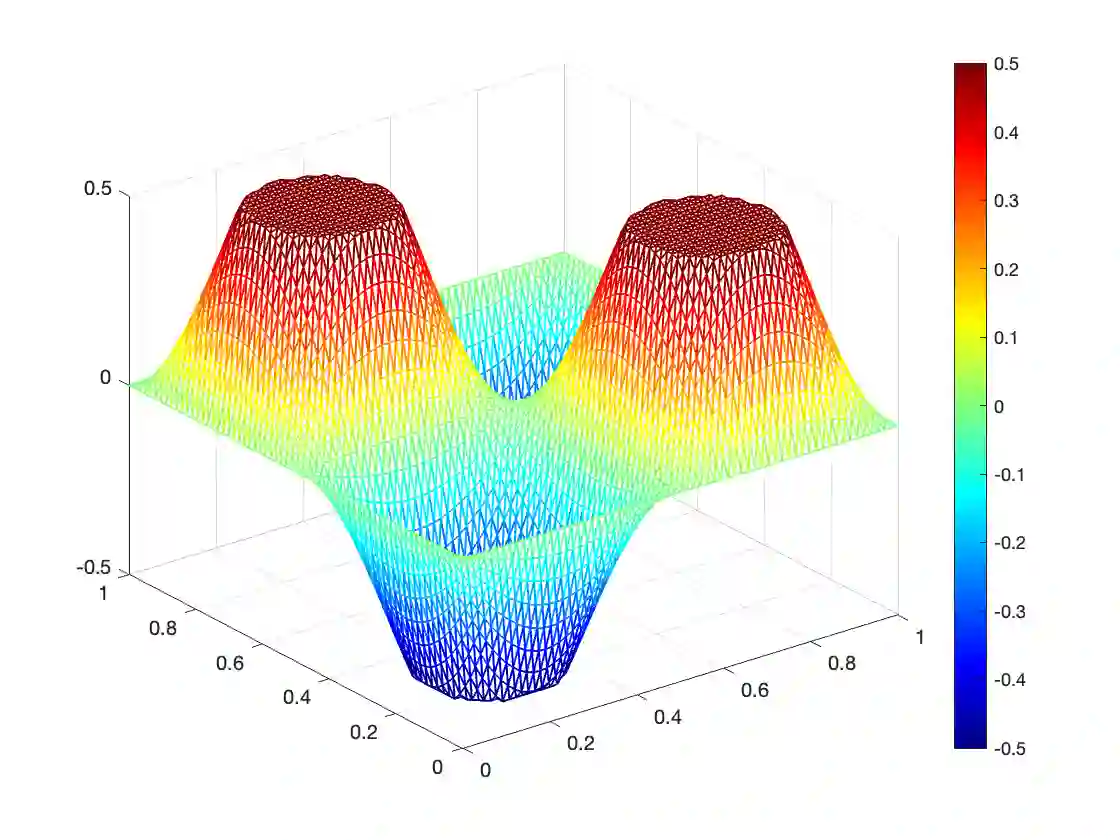
We consider a general class of nonsmooth optimal control problems with partial differential equation (PDE) constraints, which are very challenging due to its nonsmooth objective functionals and the resulting high-dimensional and ill-conditioned systems after discretization. We focus on the application of a primal-dual method, with which different types of variables can be treated individually and thus its main computation at each iteration only requires solving two PDEs. Our target is to accelerate the primal-dual method with either larger step sizes or operator learning techniques. For the accelerated primal-dual method with larger step sizes, its convergence can be still proved rigorously while it numerically accelerates the original primal-dual method in a simple and universal way. For the operator learning acceleration, we construct deep neural network surrogate models for the involved PDEs. Once a neural operator is learned, solving a PDE requires only a forward pass of the neural network, and the computational cost is thus substantially reduced. The accelerated primal-dual method with operator learning is mesh-free, numerically efficient, and scalable to different types of PDEs. The acceleration effectiveness of these two techniques is promisingly validated by some preliminary numerical results.
翻译:本文考虑一类带偏微分方程约束的非光滑最优控制问题。这类问题因其目标泛函的非光滑性以及离散化后产生的高维病态系统而极具挑战性。我们聚焦于原始-对偶方法的应用,该方法可对不同类型变量进行独立处理,因此每次迭代的主要计算仅需求解两个偏微分方程。我们的目标是通过放大步长或算子学习技术来加速原始-对偶方法。对于放大步长的加速原始-对偶方法,其收敛性仍可得到严格证明,且该方法能以简单通用的方式在数值上加速原始-对偶方法。对于算子学习加速,我们构建了用于相关偏微分方程的深度神经网络代理模型。一旦神经算子学习完成,求解偏微分方程仅需神经网络的前向传播,从而大幅降低计算成本。基于算子学习的加速原始-对偶方法具有无网格、数值高效且可扩展至不同类型偏微分方程的特点。初步数值结果验证了这两种加速技术的有效性。