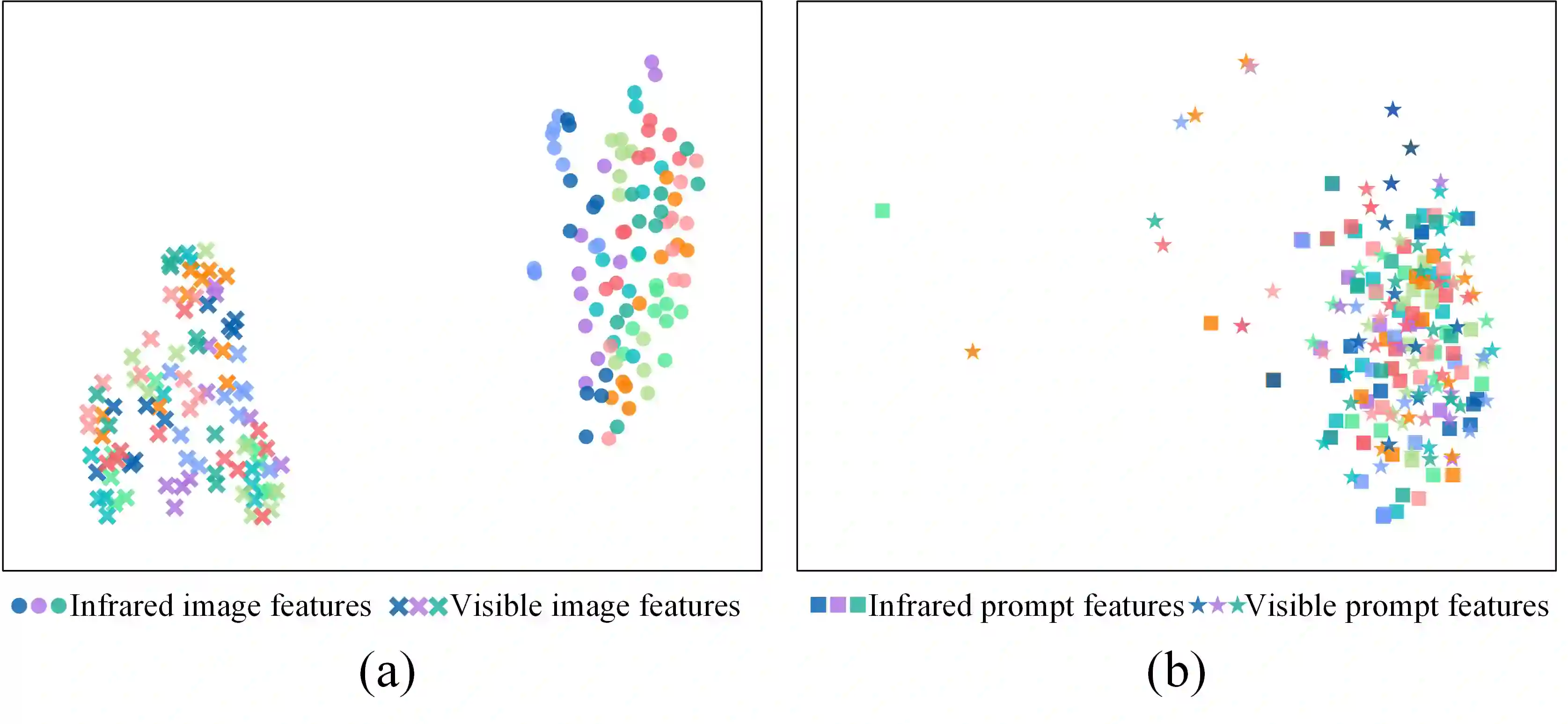
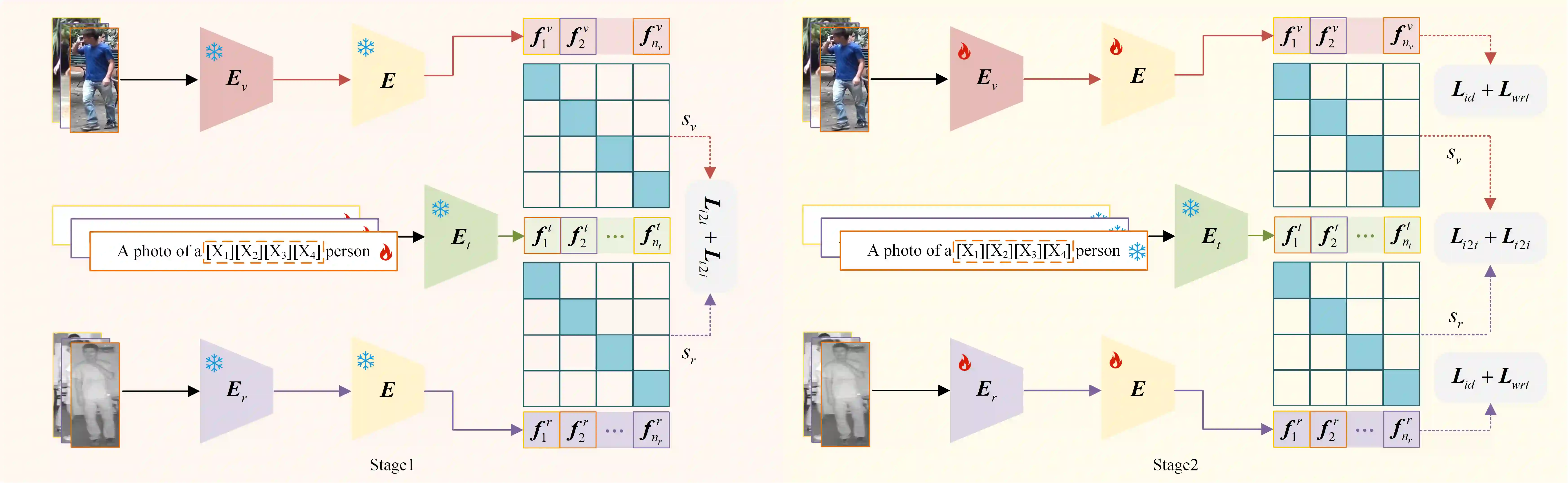
Visible-infrared person re-identification (VIReID) primarily deals with matching identities across person images from different modalities. Due to the modality gap between visible and infrared images, cross-modality identity matching poses significant challenges. Recognizing that high-level semantics of pedestrian appearance, such as gender, shape, and clothing style, remain consistent across modalities, this paper intends to bridge the modality gap by infusing visual features with high-level semantics. Given the capability of CLIP to sense high-level semantic information corresponding to visual representations, we explore the application of CLIP within the domain of VIReID. Consequently, we propose a CLIP-Driven Semantic Discovery Network (CSDN) that consists of Modality-specific Prompt Learner, Semantic Information Integration (SII), and High-level Semantic Embedding (HSE). Specifically, considering the diversity stemming from modality discrepancies in language descriptions, we devise bimodal learnable text tokens to capture modality-private semantic information for visible and infrared images, respectively. Additionally, acknowledging the complementary nature of semantic details across different modalities, we integrate text features from the bimodal language descriptions to achieve comprehensive semantics. Finally, we establish a connection between the integrated text features and the visual features across modalities. This process embed rich high-level semantic information into visual representations, thereby promoting the modality invariance of visual representations. The effectiveness and superiority of our proposed CSDN over existing methods have been substantiated through experimental evaluations on multiple widely used benchmarks. The code will be released at \url{https://github.com/nengdong96/CSDN}.
翻译:可见光-红外行人重识别(VIReID)主要解决跨模态行人图像的身份匹配问题。由于可见光与红外图像之间的模态差异,跨模态身份匹配面临重大挑战。基于行人外观的高级语义(如性别、体型、服装风格)在跨模态下保持一致性,本文旨在通过将视觉特征与高级语义相融合来弥合模态鸿沟。鉴于CLIP具备感知与视觉表征对应的高级语义信息的能力,我们探索了CLIP在VIReID领域的应用。为此,我们提出了一种CLIP驱动的语义发现网络(CSDN),该网络包含模态特定提示学习器、语义信息融合模块(SII)和高级语义嵌入模块(HSE)。具体而言,针对语言描述模态差异带来的多样性,我们设计了双模态可学习文本标记,分别捕获可见光和红外图像的模态私有语义信息。同时,考虑到不同模态间语义细节的互补特性,我们融合了双模态语言描述的文本特征以实现全面语义。最后,我们在融合后的文本特征与跨模态视觉特征之间建立关联,将丰富的高级语义信息嵌入视觉表征,从而增强视觉表征的模态不变性。通过在多个广泛使用的基准数据集上的实验评估,我们提出的CSDN方法相比现有方法展现出了有效性与优越性。代码将在\url{https://github.com/nengdong96/CSDN}开源。