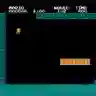
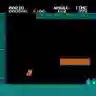
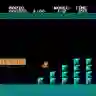
This research paper presents an experimental approach to using the Reptile algorithm for reinforcement learning to train a neural network to play Super Mario Bros. We implement the Reptile algorithm using the Super Mario Bros Gym library and TensorFlow in Python, creating a neural network model with a single convolutional layer, a flatten layer, and a dense layer. We define the optimizer and use the Reptile class to create an instance of the Reptile meta-learning algorithm. We train the model using multiple tasks and episodes, choosing actions using the current weights of the neural network model, taking those actions in the environment, and updating the model weights using the Reptile algorithm. We evaluate the performance of the algorithm by printing the total reward for each episode. In addition, we compare the performance of the Reptile algorithm approach to two other popular reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Deep Q-Network (DQN), applied to the same Super Mario Bros task. Our results demonstrate that the Reptile algorithm provides a promising approach to few-shot learning in video game AI, with comparable or even better performance than the other two algorithms, particularly in terms of moves vs distance that agent performs for 1M episodes of training. The results shows that best total distance for world 1-2 in the game environment were ~1732 (PPO), ~1840 (DQN) and ~2300 (RAMario). Full code is available at https://github.com/s4nyam/RAMario.
翻译:[translated abstract in Chinese]
本研究论文提出了一种实验性方法,利用爬行动物(Reptile)算法进行强化学习,训练神经网络以玩《超级马里奥兄弟》。我们使用Super Mario Bros Gym库和Python中的TensorFlow实现Reptile算法,构建了一个包含单个卷积层、扁平层和密集层的神经网络模型。我们定义了优化器,并使用Reptile类创建了Reptile元学习算法的实例。我们通过多个任务和回合训练模型,利用神经网络模型的当前权重选择动作,在环境中执行这些动作,并使用Reptile算法更新模型权重。通过打印每回合的总奖励来评估算法性能。此外,我们将Reptile算法方法与应用于同一《超级马里奥兄弟》任务的另外两种流行强化学习算法——近端策略优化(PPO)和深度Q网络(DQN)——进行了性能比较。我们的结果表明,Reptile算法为视频游戏AI中的少样本学习提供了一种有前景的方法,在性能上与其他两种算法相当甚至更优,特别是在代理在100万回合训练中的移动距离方面。结果显示,在游戏世界的1-2关卡中,最佳总距离约为~1732(PPO)、~1840(DQN)和~2300(RAMario)。完整代码可在https://github.com/s4nyam/RAMario获取。