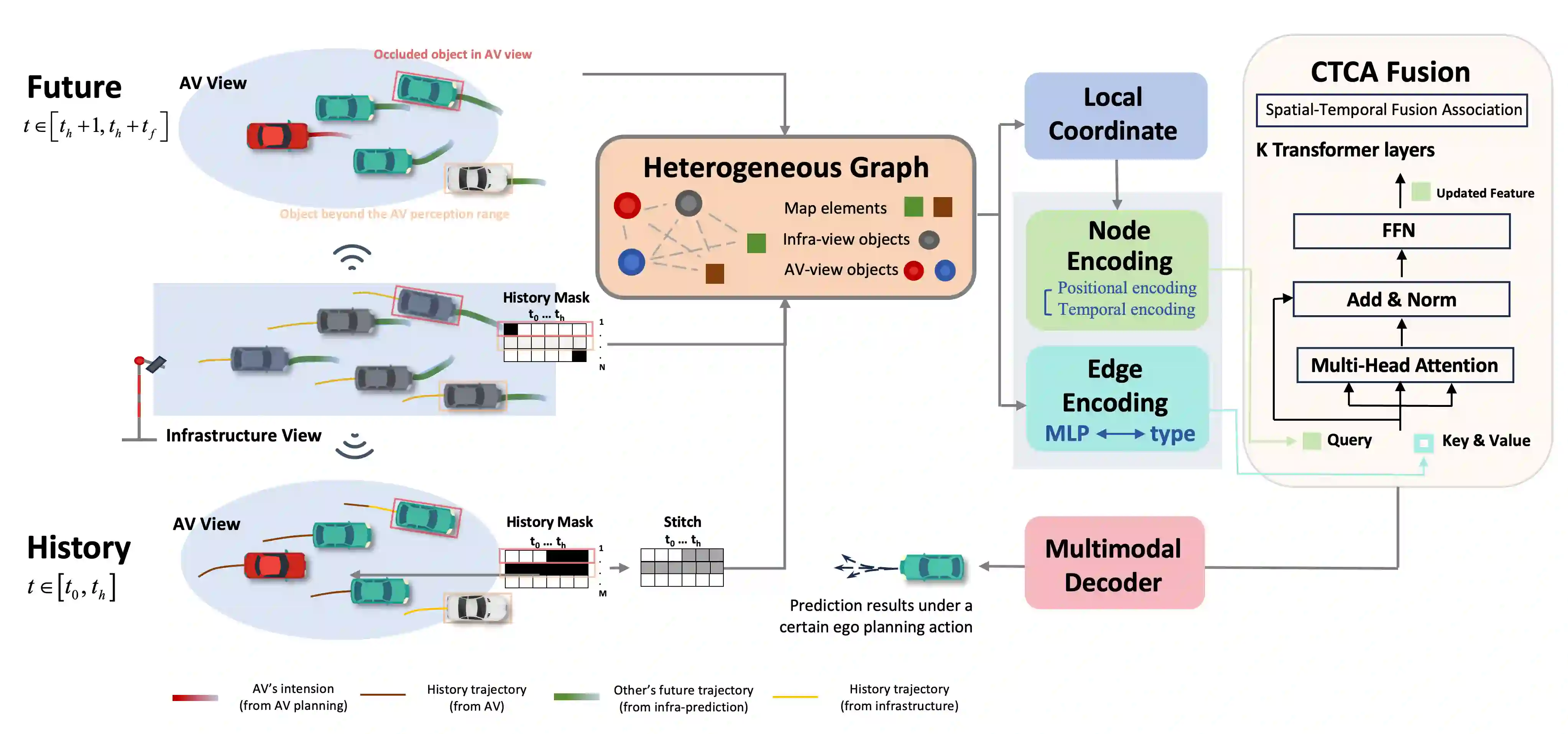
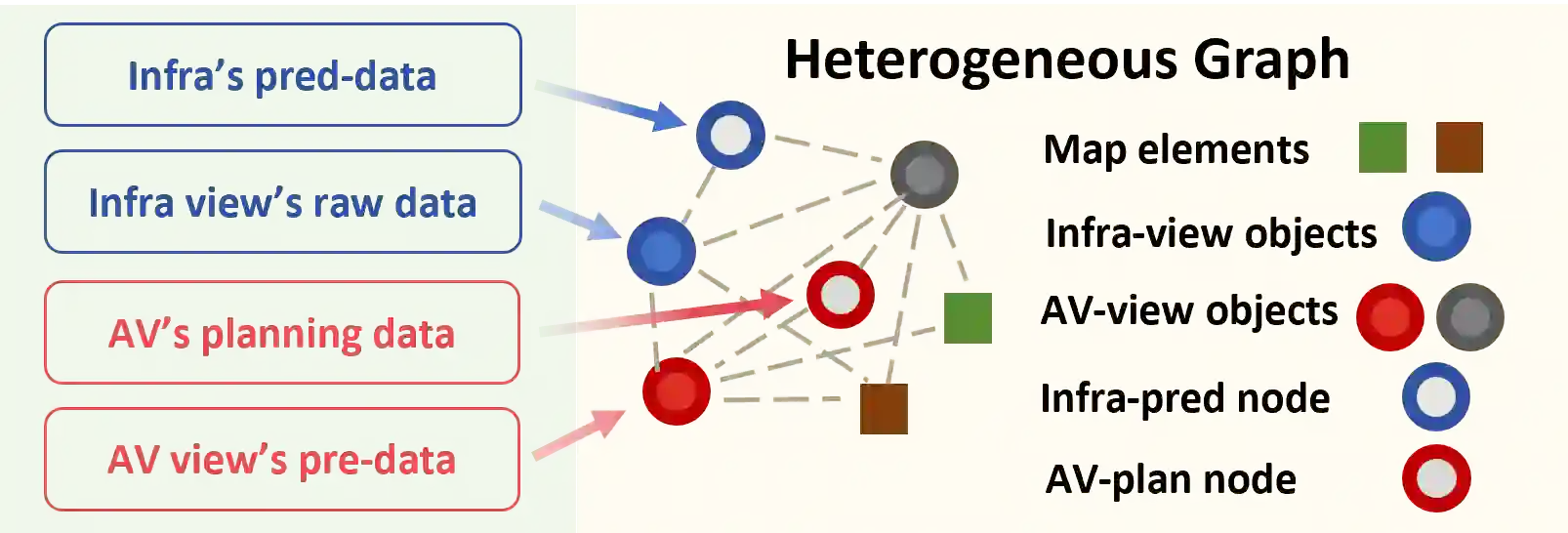
Vehicle-to-everything technologies (V2X) have become an ideal paradigm to extend the perception range and see through the occlusion. Exiting efforts focus on single-frame cooperative perception, however, how to capture the temporal cue between frames with V2X to facilitate the prediction task even the planning task is still underexplored. In this paper, we introduce the Co-MTP, a general cooperative trajectory prediction framework with multi-temporal fusion for autonomous driving, which leverages the V2X system to fully capture the interaction among agents in both history and future domains to benefit the planning. In the history domain, V2X can complement the incomplete history trajectory in single-vehicle perception, and we design a heterogeneous graph transformer to learn the fusion of the history feature from multiple agents and capture the history interaction. Moreover, the goal of prediction is to support future planning. Thus, in the future domain, V2X can provide the prediction results of surrounding objects, and we further extend the graph transformer to capture the future interaction among the ego planning and the other vehicles' intentions and obtain the final future scenario state under a certain planning action. We evaluate the Co-MTP framework on the real-world dataset V2X-Seq, and the results show that Co-MTP achieves state-of-the-art performance and that both history and future fusion can greatly benefit prediction.
翻译:车联万物(V2X)技术已成为扩展感知范围与穿透遮挡的理想范式。现有研究主要集中于单帧协同感知,然而如何利用V2X捕获帧间时序线索以提升预测任务乃至规划任务的性能,仍待深入探索。本文提出Co-MTP——一种通用的多时序融合协同轨迹预测框架,该框架利用V2X系统充分捕获历史与未来双域中智能体间的交互作用,以优化规划性能。在历史域中,V2X可补全单车感知中不完整的历史轨迹,我们设计了一种异构图Transformer来学习多智能体历史特征的融合,并捕获历史交互关系。此外,预测的最终目标在于支撑未来规划。因此在未来域中,V2X可提供周围物体的预测结果,我们进一步扩展图Transformer以捕获自车规划与其他车辆意图间的未来交互,并在给定规划动作下推演出最终的未来场景状态。我们在真实世界数据集V2X-Seq上评估Co-MTP框架,实验结果表明该框架取得了最先进的性能,且历史与未来双域融合均能显著提升预测效果。