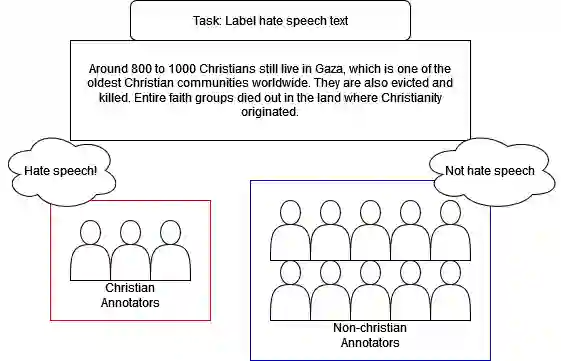
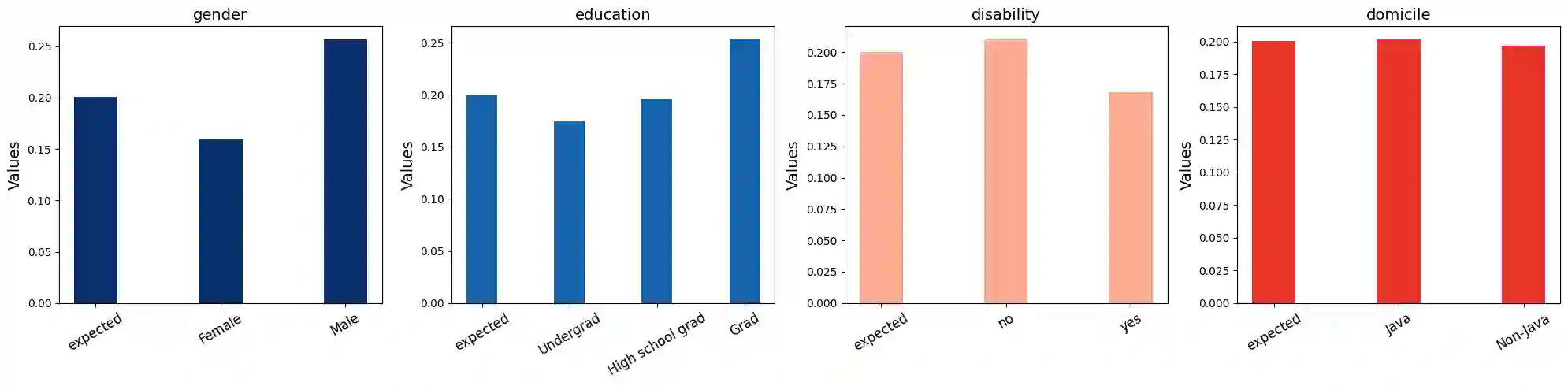
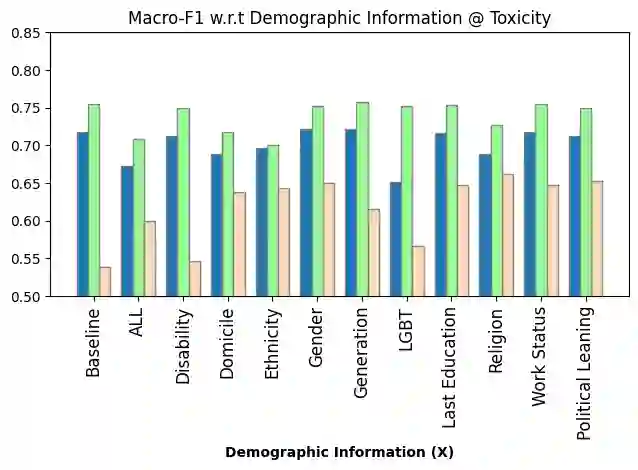
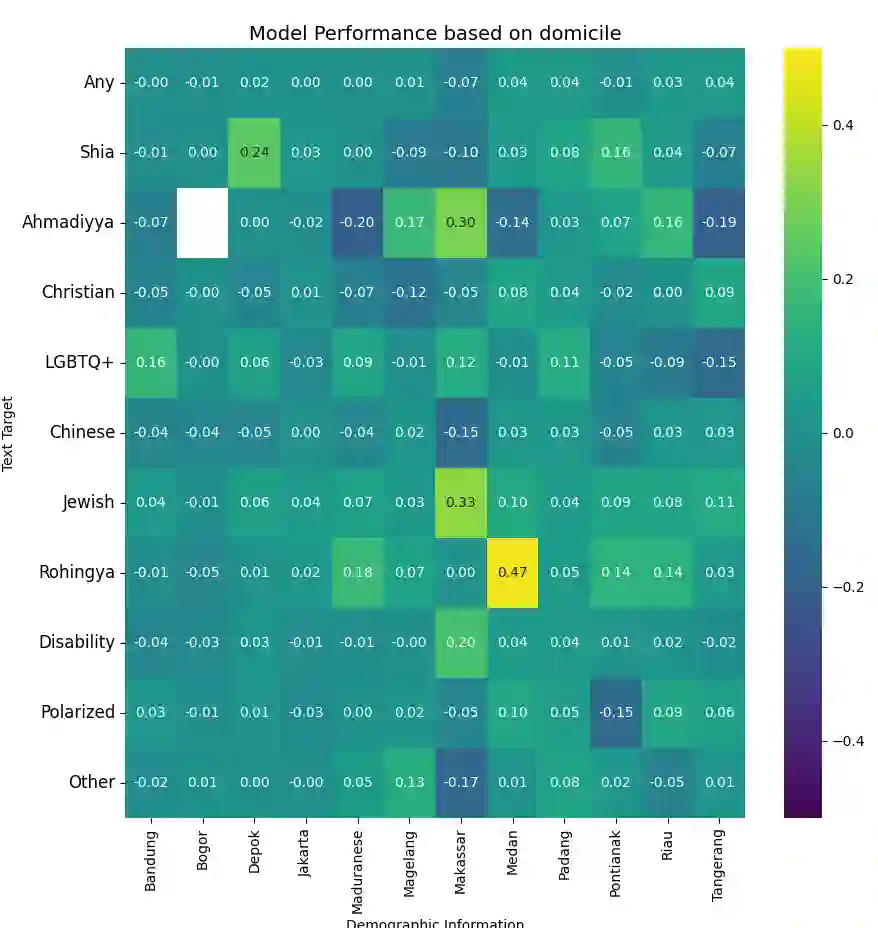
Hate speech poses a significant threat to social harmony. Over the past two years, Indonesia has seen a ten-fold increase in the online hate speech ratio, underscoring the urgent need for effective detection mechanisms. However, progress is hindered by the limited availability of labeled data for Indonesian texts. The condition is even worse for marginalized minorities, such as Shia, LGBTQ, and other ethnic minorities because hate speech is underreported and less understood by detection tools. Furthermore, the lack of accommodation for subjectivity in current datasets compounds this issue. To address this, we introduce IndoToxic2024, a comprehensive Indonesian hate speech and toxicity classification dataset. Comprising 43,692 entries annotated by 19 diverse individuals, the dataset focuses on texts targeting vulnerable groups in Indonesia, specifically during the hottest political event in the country: the presidential election. We establish baselines for seven binary classification tasks, achieving a macro-F1 score of 0.78 with a BERT model (IndoBERTweet) fine-tuned for hate speech classification. Furthermore, we demonstrate how incorporating demographic information can enhance the zero-shot performance of the large language model, gpt-3.5-turbo. However, we also caution that an overemphasis on demographic information can negatively impact the fine-tuned model performance due to data fragmentation.
翻译:仇恨言论对社会和谐构成重大威胁。过去两年间,印尼网络仇恨言论比例激增十倍,凸显了建立有效检测机制的迫切性。然而,印尼语标注数据的匮乏阻碍了相关进展。对于什叶派、LGBTQ群体及其他少数族裔等边缘化群体而言,情况更为严峻,因为针对他们的仇恨言论存在上报不足且检测工具理解有限的问题。此外,现有数据集对主观性的考量不足进一步加剧了这一困境。为此,我们提出了IndoToxic2024——一个全面的印尼语仇恨言论与毒性分类数据集。该数据集包含43,692条文本条目,由19位背景各异的标注者进行标注,重点关注印尼国内最热门的政治事件(总统选举)期间针对该国弱势群体的文本内容。我们为七项二元分类任务建立了基线模型,其中专为仇恨言论分类微调的BERT模型(IndoBERTweet)取得了0.78的宏观F1分数。此外,我们证明了融入人口统计信息能够提升大语言模型gpt-3.5-turbo的零样本性能。但我们也警示,过度强调人口统计信息可能因数据碎片化而对微调模型性能产生负面影响。