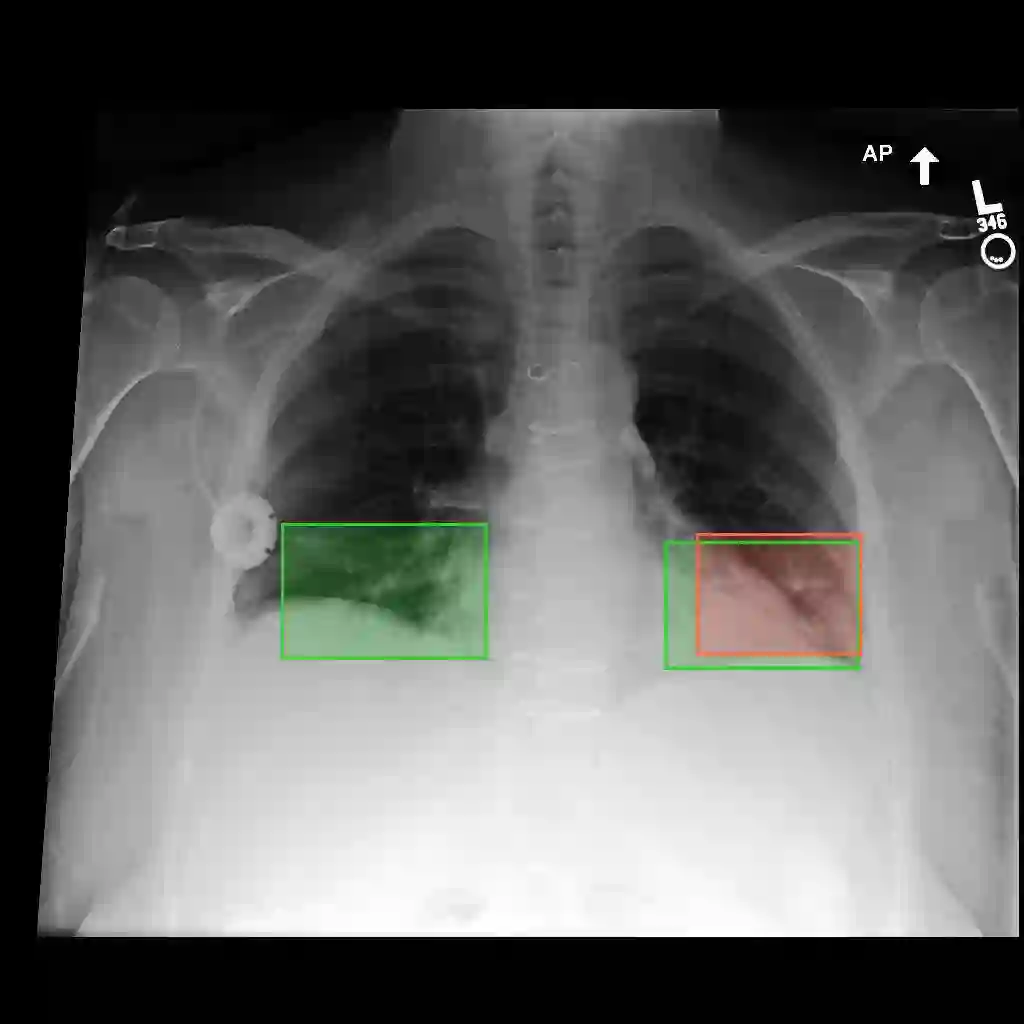
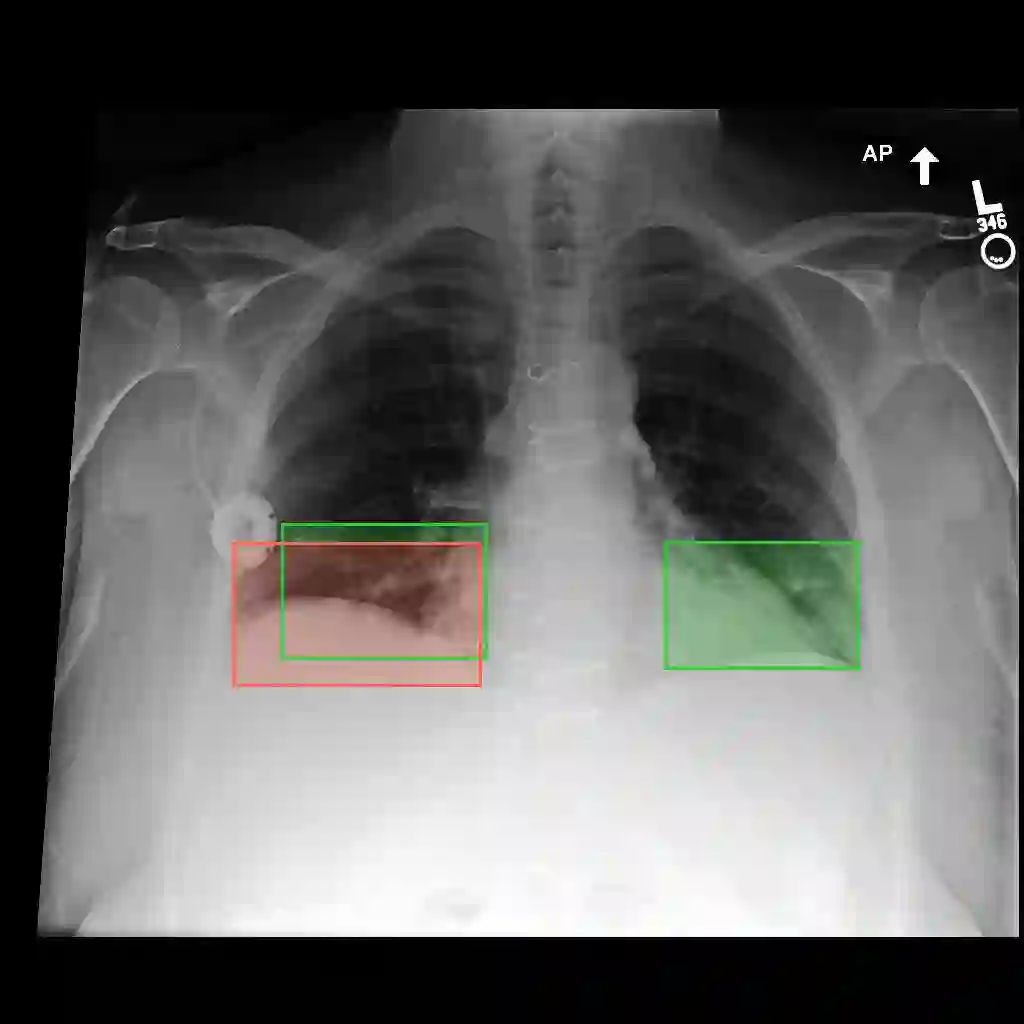
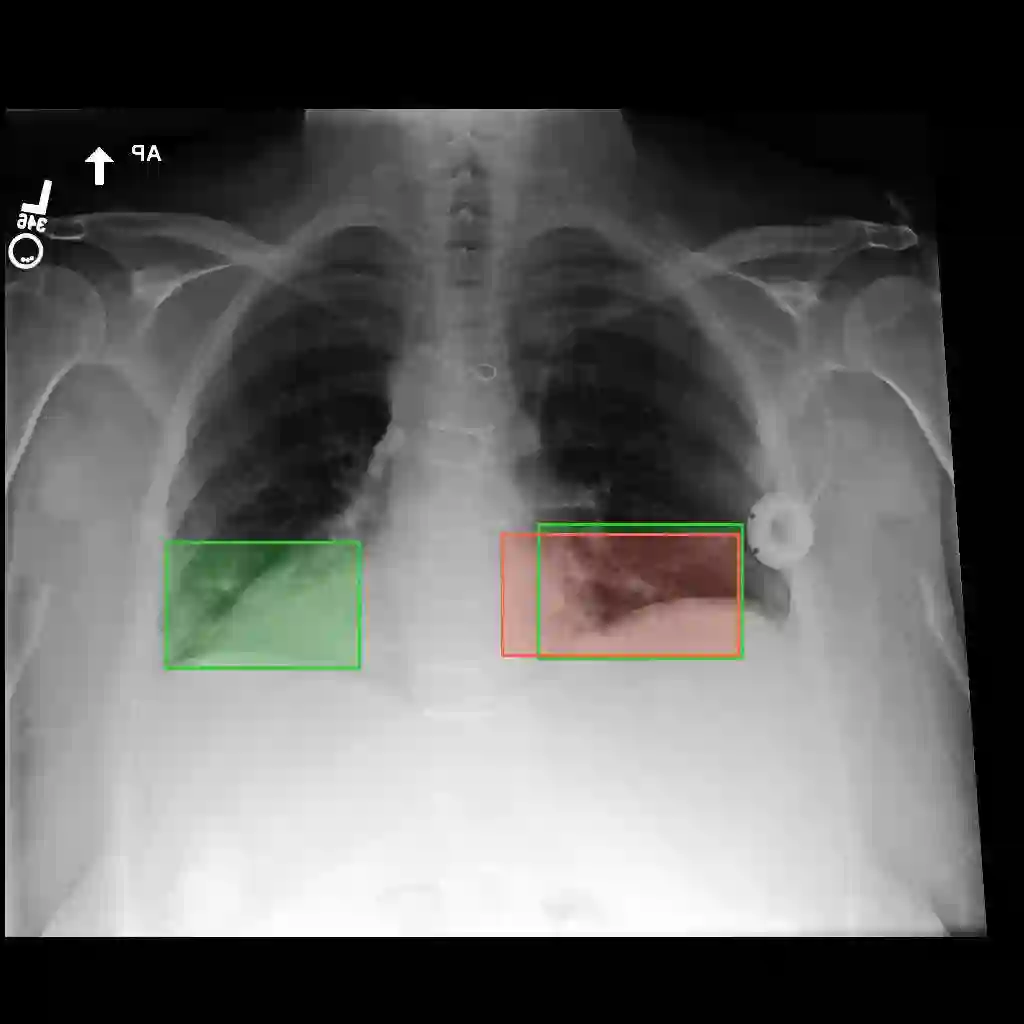
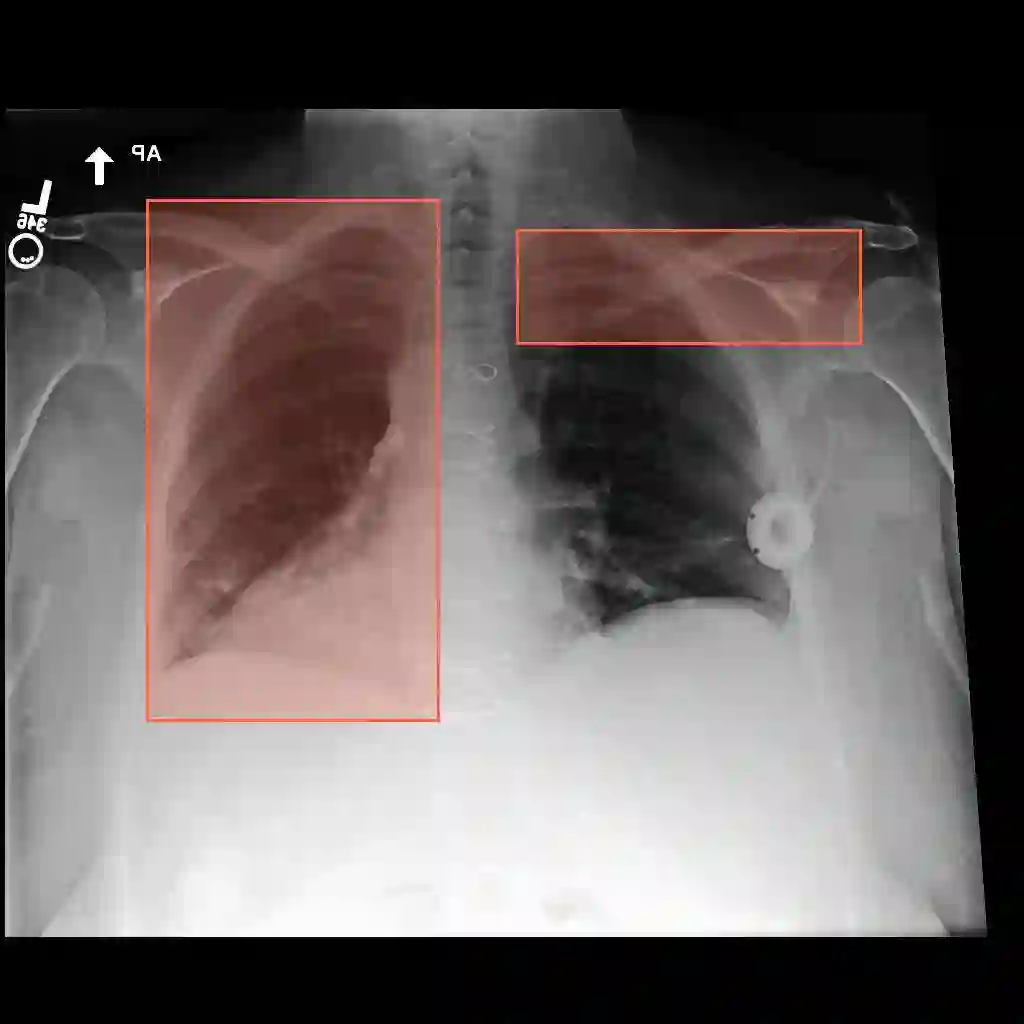
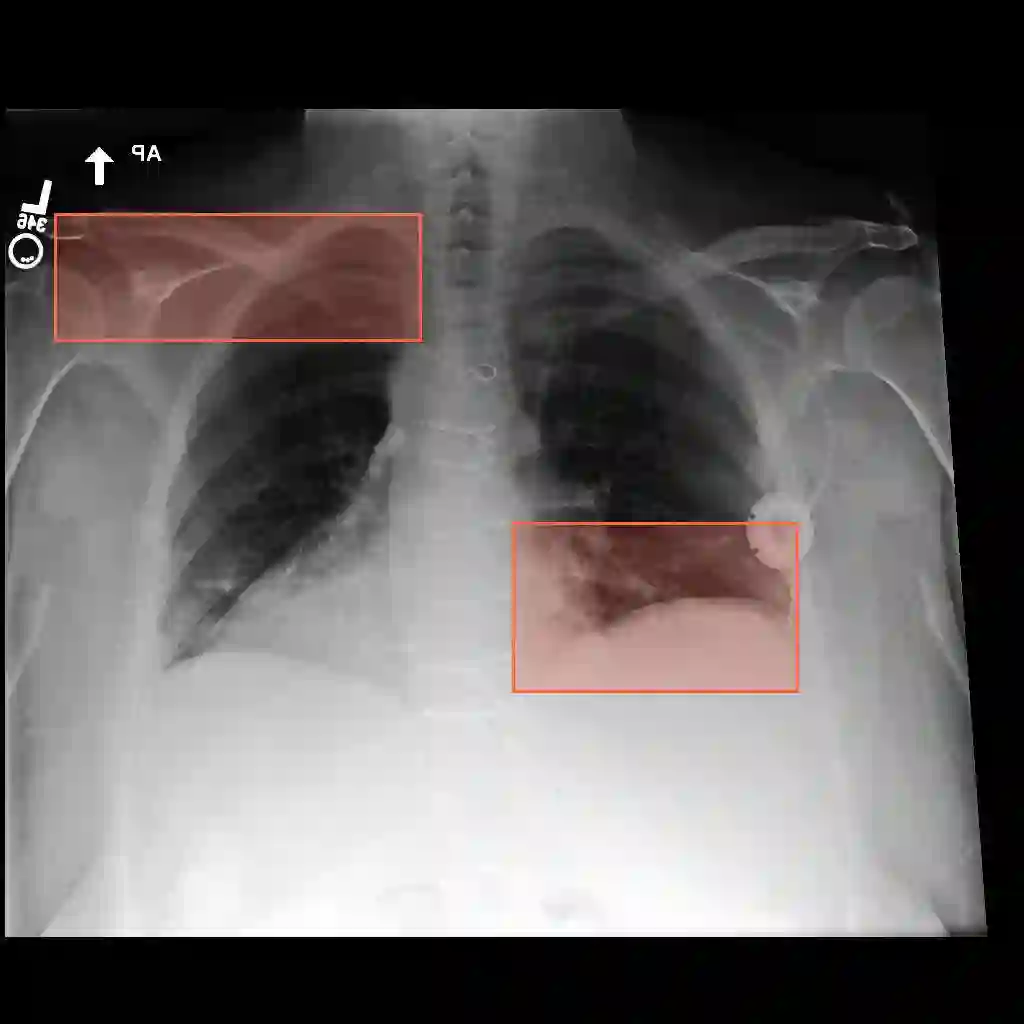
Multimodal medical large language models have shown impressive progress in chest X-ray interpretation but continue to face challenges in spatial reasoning and anatomical understanding. Although existing grounding techniques improve overall performance, they often fail to establish a true anatomical correspondence, resulting in incorrect anatomical understanding in the medical domain. To address this gap, we introduce AnatomiX, a multitask multimodal large language model explicitly designed for anatomically grounded chest X-ray interpretation. Inspired by the radiological workflow, AnatomiX adopts a two stage approach: first, it identifies anatomical structures and extracts their features, and then leverages a large language model to perform diverse downstream tasks such as phrase grounding, report generation, visual question answering, and image understanding. Extensive experiments across multiple benchmarks demonstrate that AnatomiX achieves superior anatomical reasoning and delivers over 25% improvement in performance on anatomy grounding, phrase grounding, grounded diagnosis and grounded captioning tasks compared to existing approaches. Code and pretrained model are available at https://github.com/aneesurhashmi/anatomix
翻译:多模态医学大语言模型在胸部X光片解读方面已展现出显著进展,但在空间推理与解剖学理解方面仍面临挑战。尽管现有定位技术提升了整体性能,但其往往未能建立真正的解剖学对应关系,导致在医学领域产生错误的解剖学理解。为弥补这一不足,我们提出了AnatomiX——一个专为基于解剖学定位的胸部X光片解读而设计的显式多任务多模态大语言模型。受放射科工作流程启发,AnatomiX采用两阶段方法:首先识别解剖结构并提取其特征,随后利用大语言模型执行多样化的下游任务,如短语定位、报告生成、视觉问答及图像理解。在多个基准测试上的大量实验表明,相较于现有方法,AnatomiX实现了卓越的解剖学推理能力,并在解剖定位、短语定位、基于定位的诊断及基于定位的描述任务上取得了超过25%的性能提升。代码与预训练模型发布于https://github.com/aneesurhashmi/anatomix