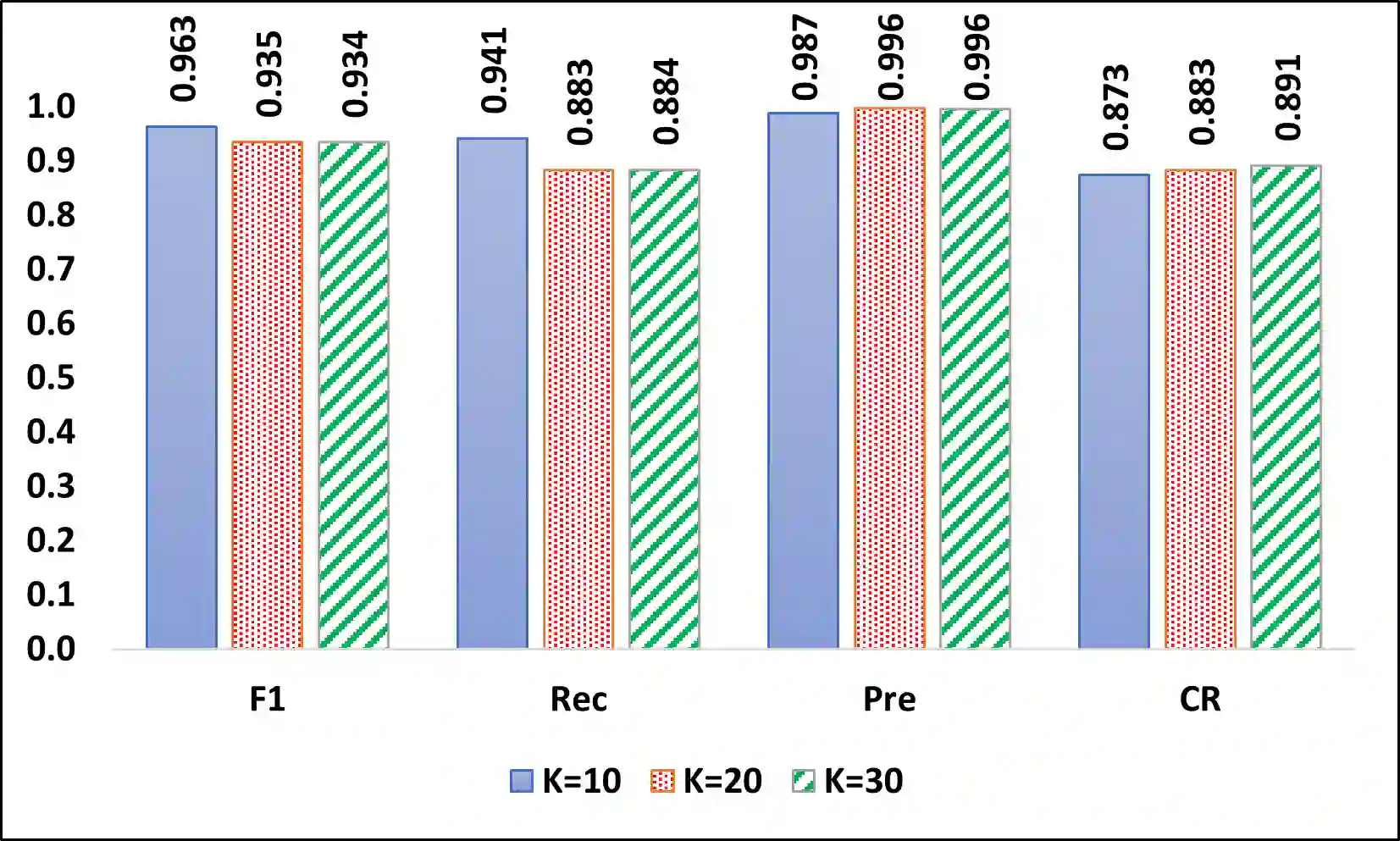
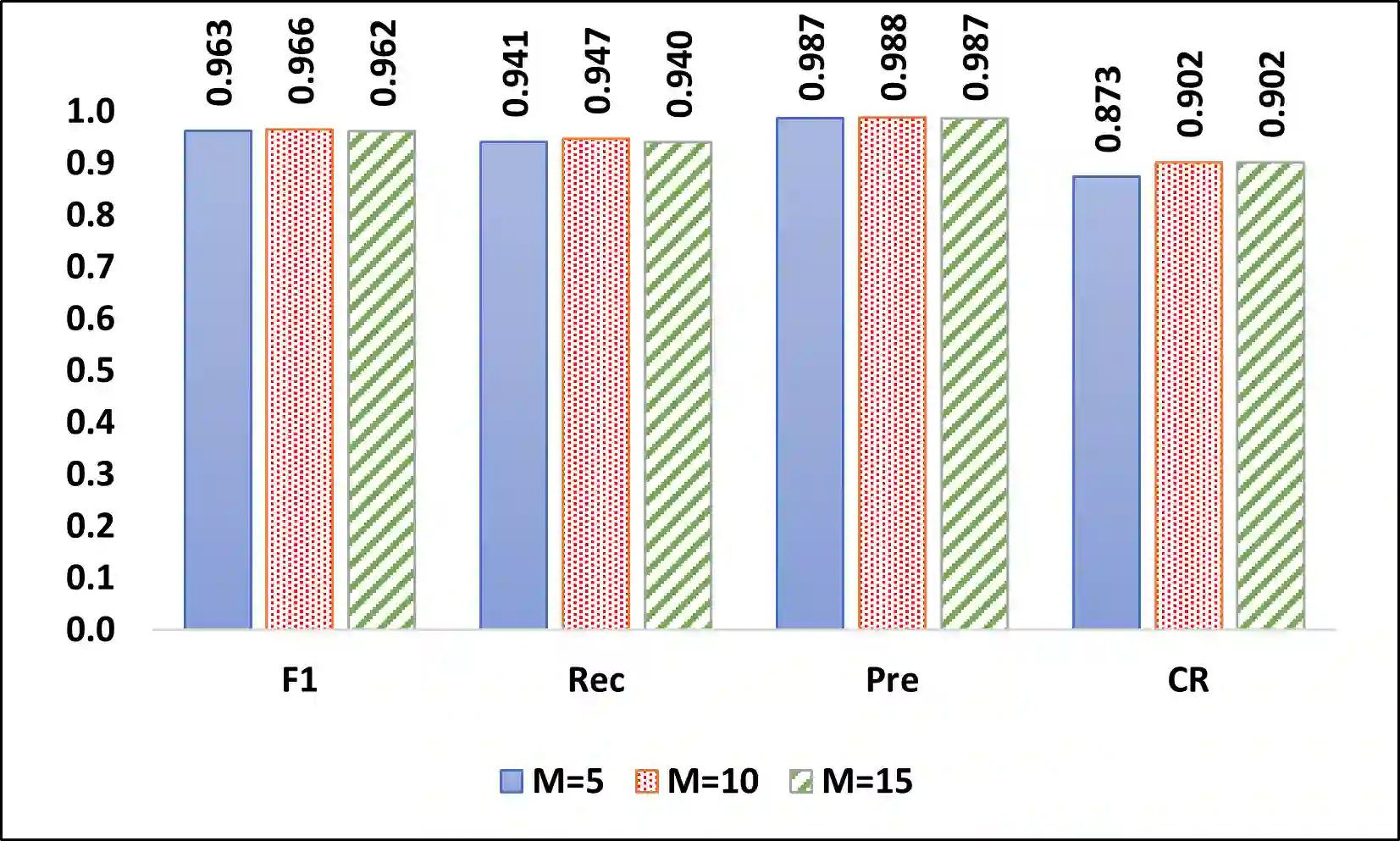
Technical question and answering (Q&A) sites such as Stack Overflow have become an important source for software developers to seek knowledge. However, code snippets on Q&A sites are usually uncompilable and semantically incomplete for compilation due to unresolved types and missing dependent libraries, which raises the obstacle for users to reuse or analyze Q&A code snippets. Prior approaches either are not designed for synthesizing compilable code or suffer from a low compilation success rate. To address this problem, we propose ZS4C, a lightweight approach to perform zero-shot synthesis of compilable code from incomplete code snippets using Large Language Model (LLM). ZS4C operates in two stages. In the first stage, ZS4C utilizes an LLM, i.e., ChatGPT, to identify missing import statements for a given code snippet, leveraging our designed task-specific prompt template. In the second stage, ZS4C fixes compilation errors caused by incorrect import statements and syntax errors through collaborative work between ChatGPT and a compiler. We thoroughly evaluated ZS4C on a widely used benchmark called StatType-SO against the SOTA approach SnR. Compared with SnR, ZS4C improves the compilation rate from 63% to 87.6%, with a 39.3% improvement. On average, ZS4C can infer more accurate import statements than SnR, with an improvement of 6.6% in the F1.
翻译:技术问答网站(如Stack Overflow)已成为软件开发人员获取知识的重要来源。然而,由于未解析的类型和缺失的依赖库,问答网站上的代码片段通常无法编译且语义不完整,这为用户重用或分析问答代码片段设置了障碍。现有方法要么不是为合成可编译代码而设计的,要么编译成功率较低。为解决这一问题,我们提出ZS4C,一种通过大型语言模型从零样本合成不完整代码片段的可编译代码的轻量级方法。ZS4C分两阶段运行:第一阶段利用大型语言模型(如ChatGPT),结合我们设计的任务特定提示模板,识别给定代码片段中缺失的导入语句;第二阶段通过ChatGPT与编译器协作,修复由错误导入语句和语法错误导致的编译错误。我们在广泛使用的基准测试StatType-SO上对ZS4C进行了全面评估,并与最新方法SnR进行了对比。与SnR相比,ZS4C将编译成功率从63%提升至87.6%,提升幅度达39.3%。在平均准确率上,ZS4C推断的导入语句比SnR更精确,F1值提升6.6%。