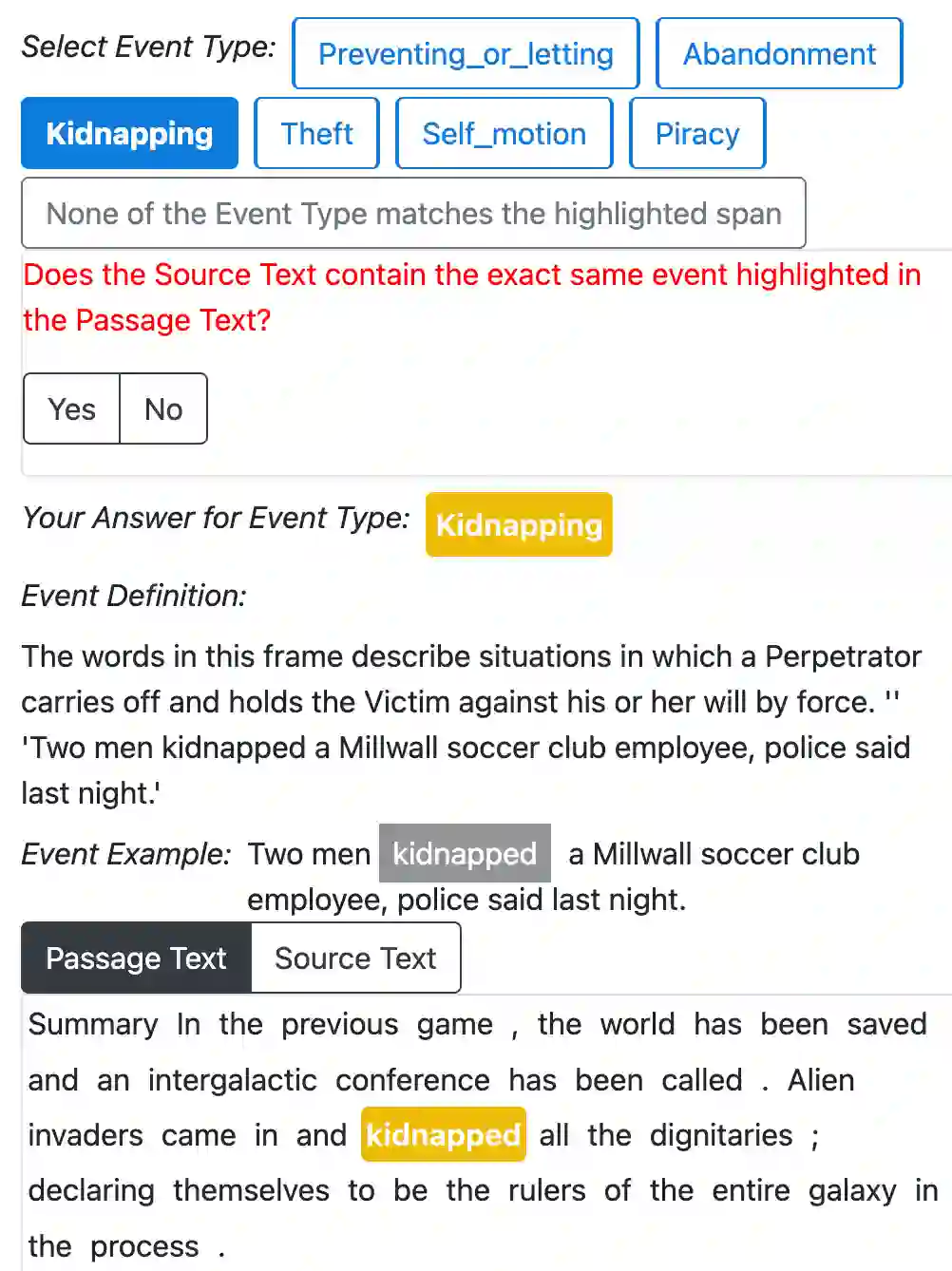
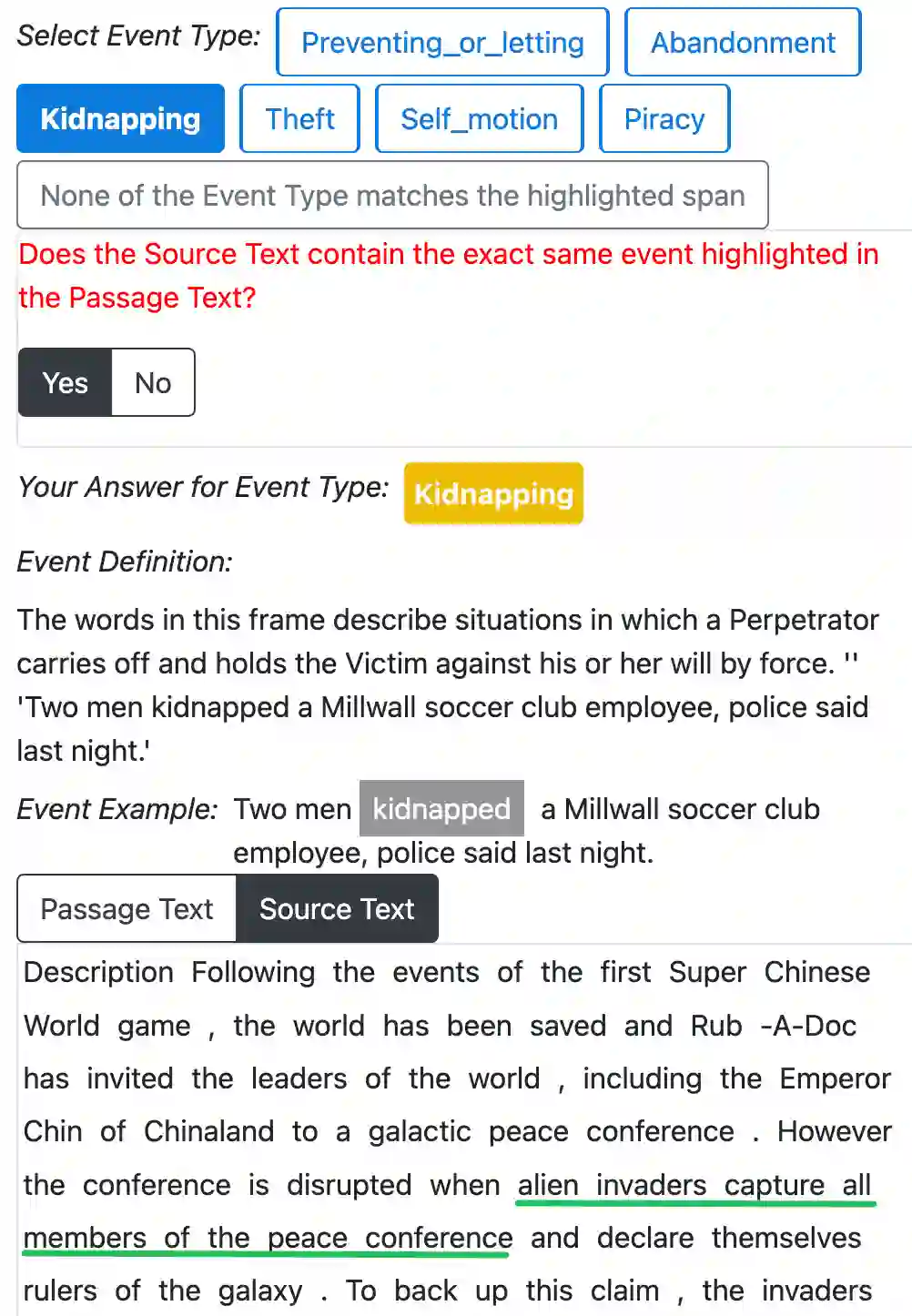
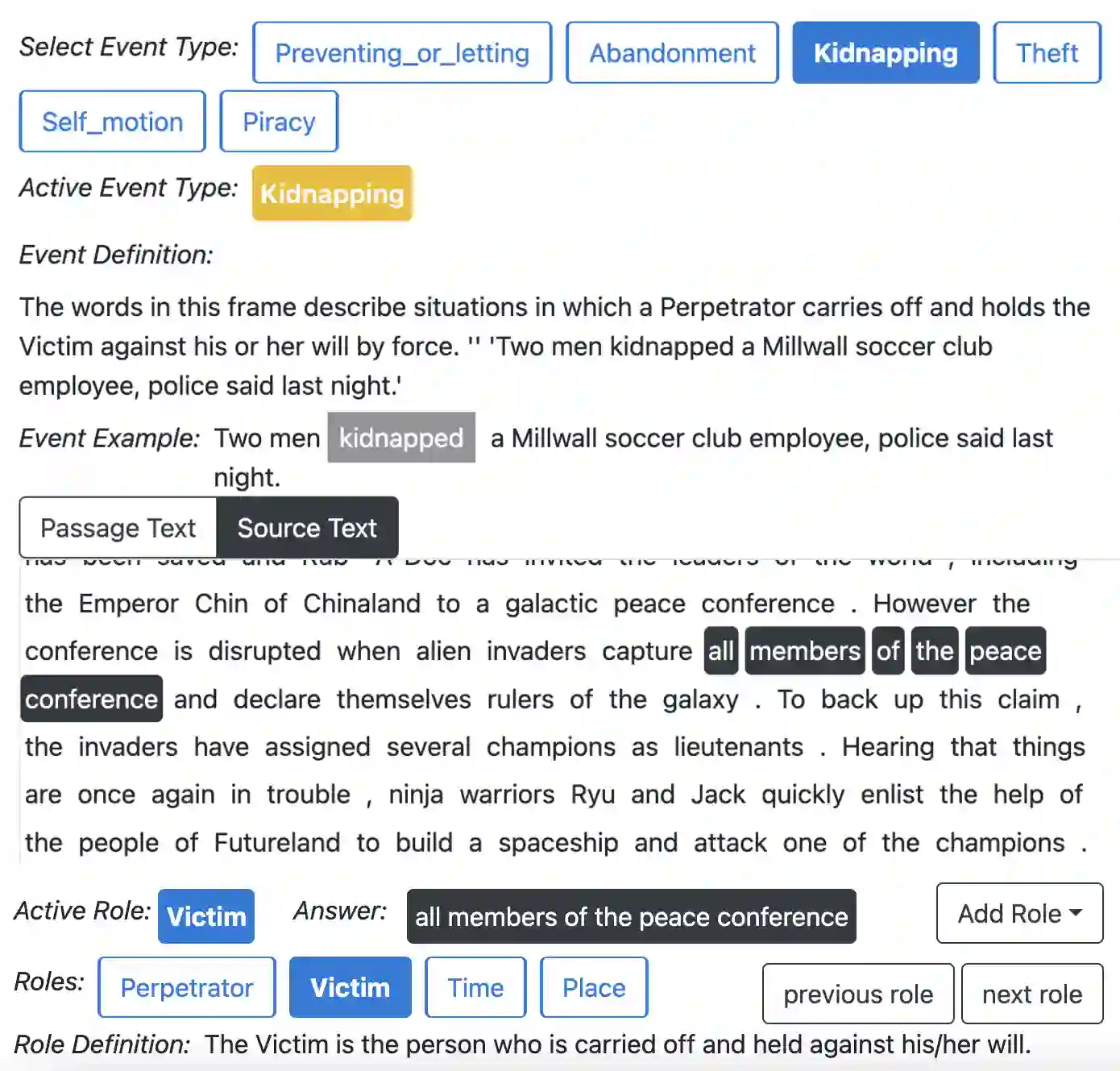
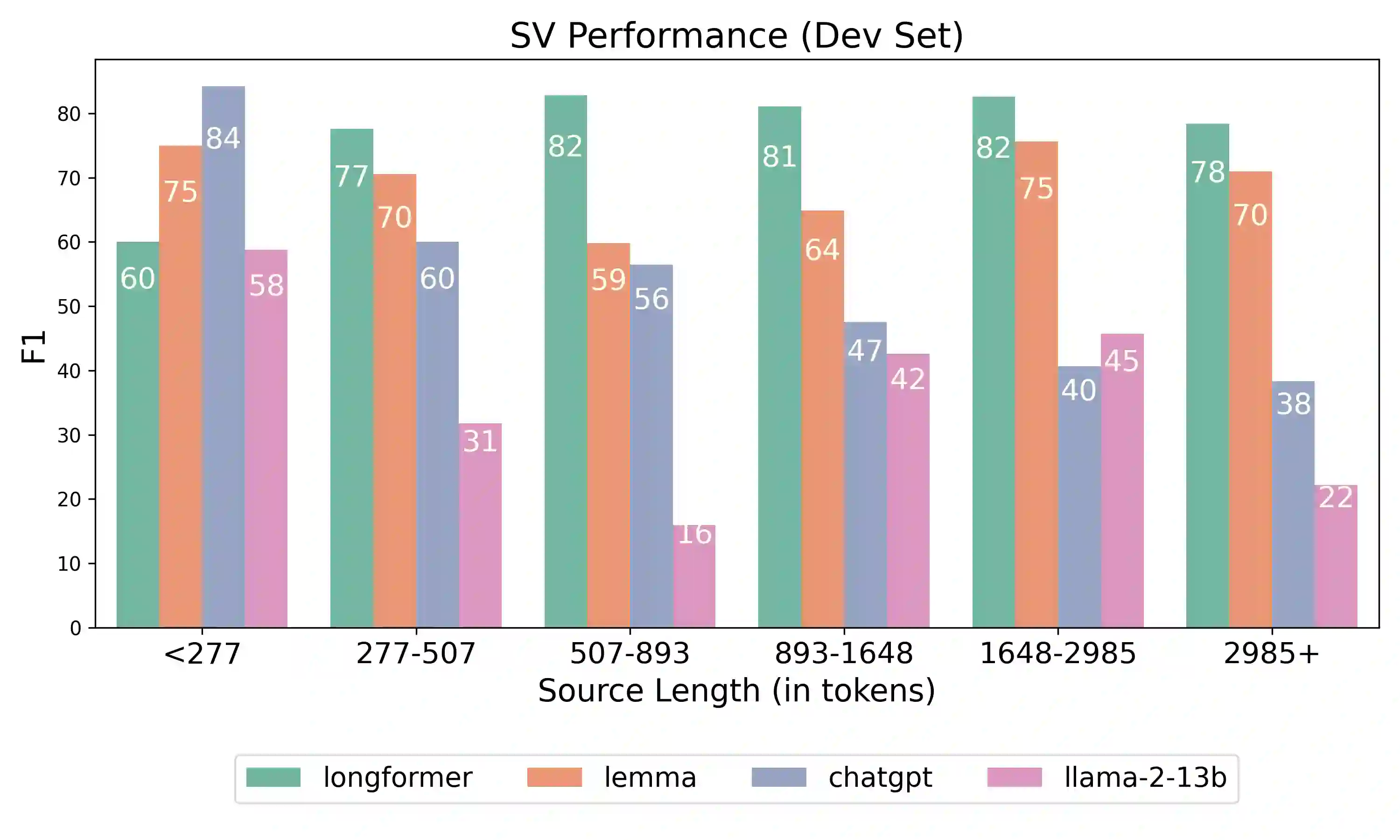
Understanding event descriptions is a central aspect of language processing, but current approaches focus overwhelmingly on single sentences or documents. Aggregating information about an event \emph{across documents} can offer a much richer understanding. To this end, we present FAMuS, a new corpus of Wikipedia passages that \emph{report} on some event, paired with underlying, genre-diverse (non-Wikipedia) \emph{source} articles for the same event. Events and (cross-sentence) arguments in both report and source are annotated against FrameNet, providing broad coverage of different event types. We present results on two key event understanding tasks enabled by FAMuS: \emph{source validation} -- determining whether a document is a valid source for a target report event -- and \emph{cross-document argument extraction} -- full-document argument extraction for a target event from both its report and the correct source article. We release both FAMuS and our models to support further research.
翻译:理解事件描述是语言处理的核心问题,但当前方法主要聚焦于单句或单文档层面。跨文档聚合事件信息能够提供更丰富的理解视角。为此,我们提出FAMuS——一个新的维基百科段落语料库,这些段落报道特定事件,并与同一事件的底层、多体裁(非维基百科)源文章配对。报道与源文章中的事件及跨句论元均基于FrameNet框架进行标注,涵盖多种事件类型。我们展示了由FAMuS支持的两项关键事件理解任务结果:源验证(判定文档是否为目标报道事件的有效来源)与跨文档论元抽取(从报道及其对应源文章中抽取目标事件的全文论元)。我们公开FAMuS语料库及对应模型以促进后续研究。