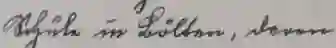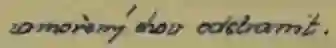Self-supervised learning has emerged as a powerful approach for leveraging large-scale unlabeled data to improve model performance in various domains. In this paper, we explore masked self-supervised pre-training for text recognition transformers. Specifically, we propose two modifications to the pre-training phase: progressively increasing the masking probability, and modifying the loss function to incorporate both masked and non-masked patches. We conduct extensive experiments using a dataset of 50M unlabeled text lines for pre-training and four differently sized annotated datasets for fine-tuning. Furthermore, we compare our pre-trained models against those trained with transfer learning, demonstrating the effectiveness of the self-supervised pre-training. In particular, pre-training consistently improves the character error rate of models, in some cases up to 30 % relatively. It is also on par with transfer learning but without relying on extra annotated text lines.
翻译:自监督学习已成为一种利用大规模无标注数据提升模型性能的强大方法。本文针对文本识别Transformer探索掩码自监督预训练策略。具体而言,我们提出两项预训练阶段的改进:逐步递增掩码概率,以及修改损失函数以同时纳入掩码与非掩码图像块。我们使用包含5000万条无标注文本行的数据集进行预训练,并在四个不同规模的标注数据集上进行微调实验。进一步将我们的预训练模型与迁移学习模型进行对比,验证了自监督预训练的有效性。实验表明,预训练能持续降低模型的字符错误率,部分情况下相对降低幅度达30%。该方法在性能上与迁移学习相当,且无需依赖额外的标注文本行。