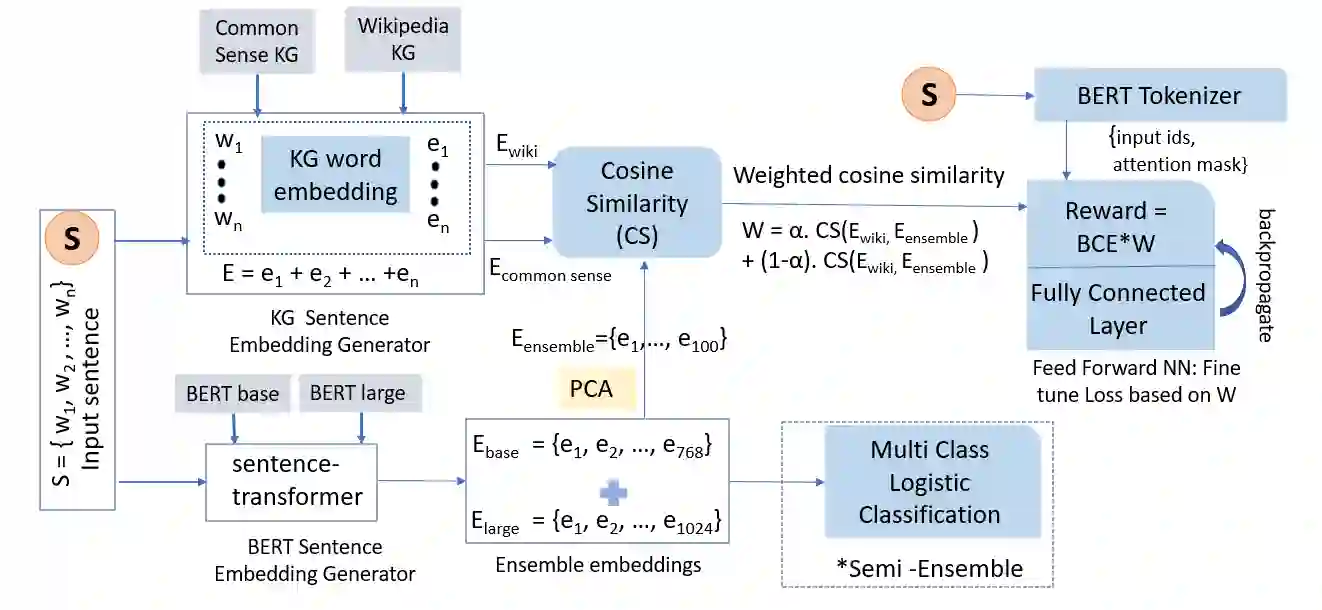
Foundational Language Models (FLMs) have advanced natural language processing (NLP) research. Current researchers are developing larger FLMs (e.g., XLNet, T5) to enable contextualized language representation, classification, and generation. While developing larger FLMs has been of significant advantage, it is also a liability concerning hallucination and predictive uncertainty. Fundamentally, larger FLMs are built on the same foundations as smaller FLMs (e.g., BERT); hence, one must recognize the potential of smaller FLMs which can be realized through an ensemble. In the current research, we perform a reality check on FLMs and their ensemble on benchmark and real-world datasets. We hypothesize that the ensembling of FLMs can influence the individualistic attention of FLMs and unravel the strength of coordination and cooperation of different FLMs. We utilize BERT and define three other ensemble techniques: {Shallow, Semi, and Deep}, wherein the Deep-Ensemble introduces a knowledge-guided reinforcement learning approach. We discovered that the suggested Deep-Ensemble BERT outperforms its large variation i.e. BERTlarge, by a factor of many times using datasets that show the usefulness of NLP in sensitive fields, such as mental health.
翻译:基础语言模型(FLMs)推动了自然语言处理(NLP)研究的发展。当前研究人员正在开发更大规模的FLMs(如XLNet、T5),以实现上下文相关的语言表示、分类与生成。尽管开发更大规模的FLMs具有显著优势,但它在幻觉现象和预测不确定性方面也存在缺陷。从根本上说,较大规模的FLMs是建立在与较小规模FLMs(如BERT)相同的基础之上的;因此,必须认识到通过集成方法可以发挥较小规模FLMs的潜力。在本研究中,我们对FLMs及其集成在基准数据集和真实世界数据集上进行了现实性检验。我们假设FLMs的集成能够影响FLMs的个体化注意力机制,并揭示不同FLMs之间协调与协作的效能。我们使用BERT并定义了另外三种集成技术:{浅层、半深层和深层},其中深层集成引入了一种知识引导的强化学习方法。我们发现,所提出的深层集成BERT在多个数据集上的性能远超其大版本(即BERTlarge),这些数据集展示了NLP在心理健康等敏感领域中的实用性。