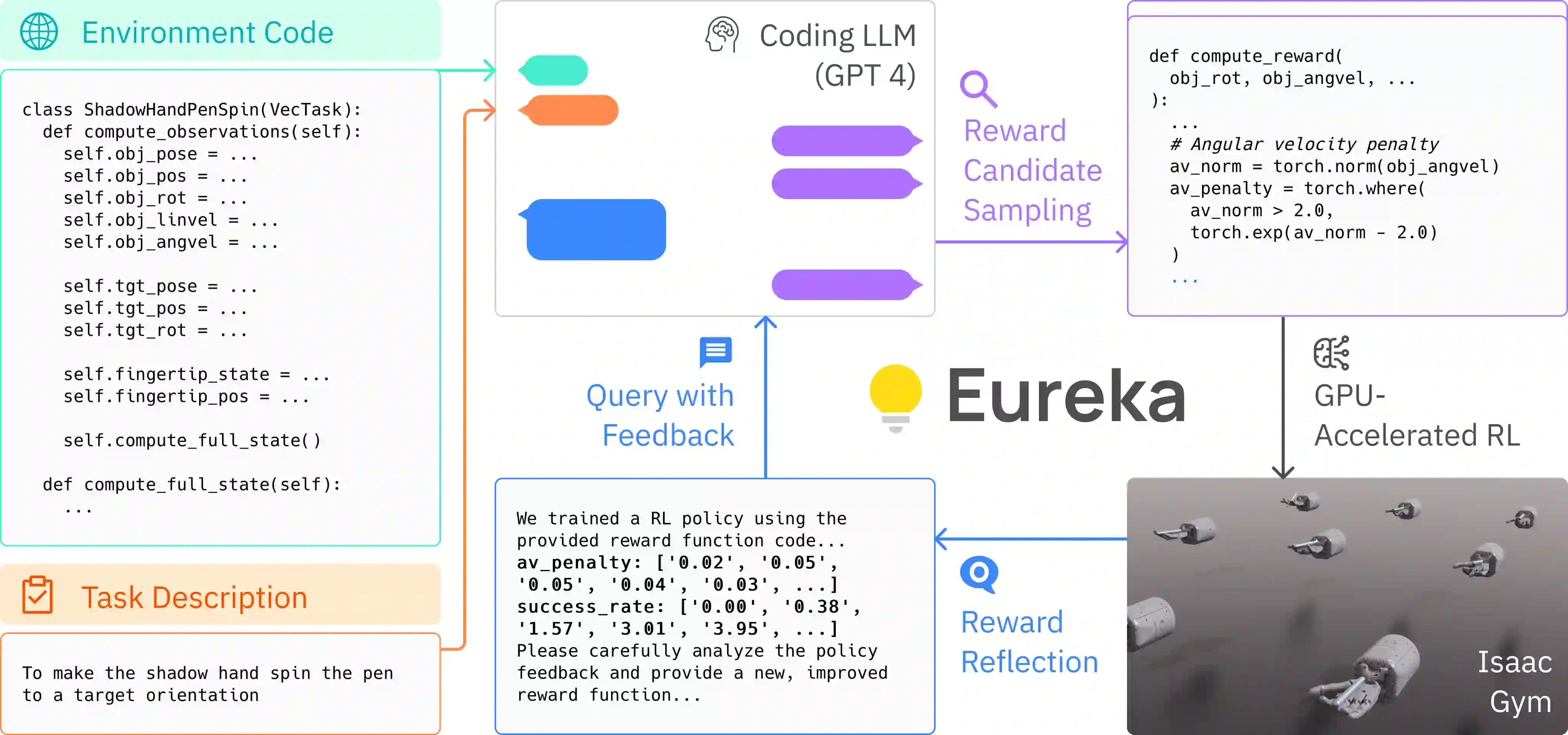
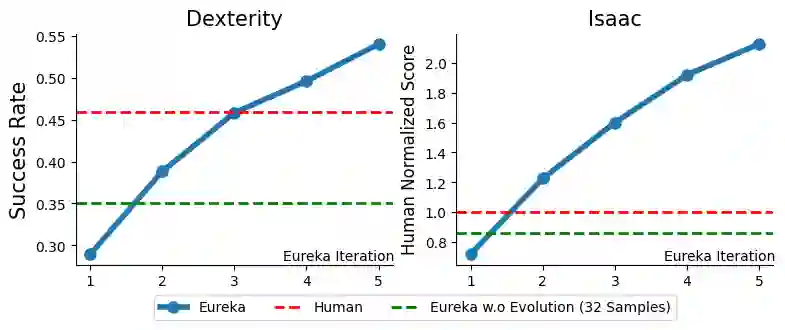
Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridge this fundamental gap and present Eureka, a human-level reward design algorithm powered by LLMs. Eureka exploits the remarkable zero-shot generation, code-writing, and in-context improvement capabilities of state-of-the-art LLMs, such as GPT-4, to perform evolutionary optimization over reward code. The resulting rewards can then be used to acquire complex skills via reinforcement learning. Without any task-specific prompting or pre-defined reward templates, Eureka generates reward functions that outperform expert human-engineered rewards. In a diverse suite of 29 open-source RL environments that include 10 distinct robot morphologies, Eureka outperforms human experts on 83% of the tasks, leading to an average normalized improvement of 52%. The generality of Eureka also enables a new gradient-free in-context learning approach to reinforcement learning from human feedback (RLHF), readily incorporating human inputs to improve the quality and the safety of the generated rewards without model updating. Finally, using Eureka rewards in a curriculum learning setting, we demonstrate for the first time, a simulated Shadow Hand capable of performing pen spinning tricks, adeptly manipulating a pen in circles at rapid speed.
翻译:大语言模型(LLMs)在序列决策任务中作为高层语义规划器表现出色,然而如何利用它们学习复杂的低层操控任务(例如灵巧的转笔)仍是一个开放性问题。我们弥合了这一根本差距,提出了Eureka——一种由LLMs驱动的人类级别奖励设计算法。Eureka利用先进LLMs(如GPT-4)卓越的零样本生成、代码编写和上下文改进能力,对奖励代码进行进化优化。由此产生的奖励可通过强化学习获取复杂技能。无需任何任务特定提示或预定义奖励模板,Eureka生成的奖励函数超越人类专家精心设计的奖励。在包含10种不同机器人形态的29个开源强化学习环境中,Eureka在83%的任务上优于人类专家,平均标准化提升达52%。Eureka的通用性还催生了一种基于人类反馈的无梯度上下文强化学习新方法,可轻松融入人类输入以提升生成奖励的质量与安全性,且无需模型更新。最后,在课程学习设置中应用Eureka奖励,我们首次展示了能够执行转笔技巧的模拟Shadow Hand——以高速流畅地旋转笔杆。