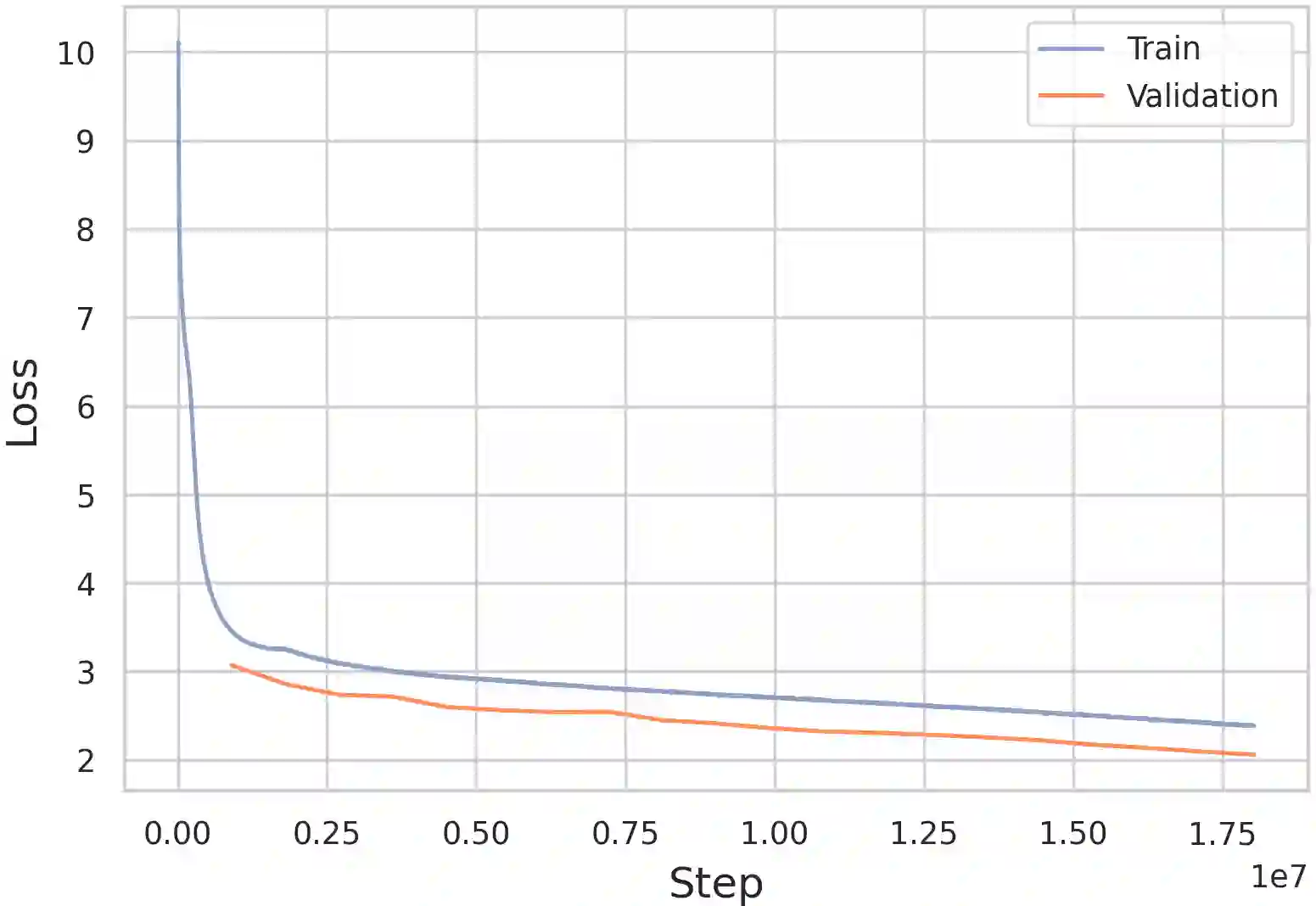
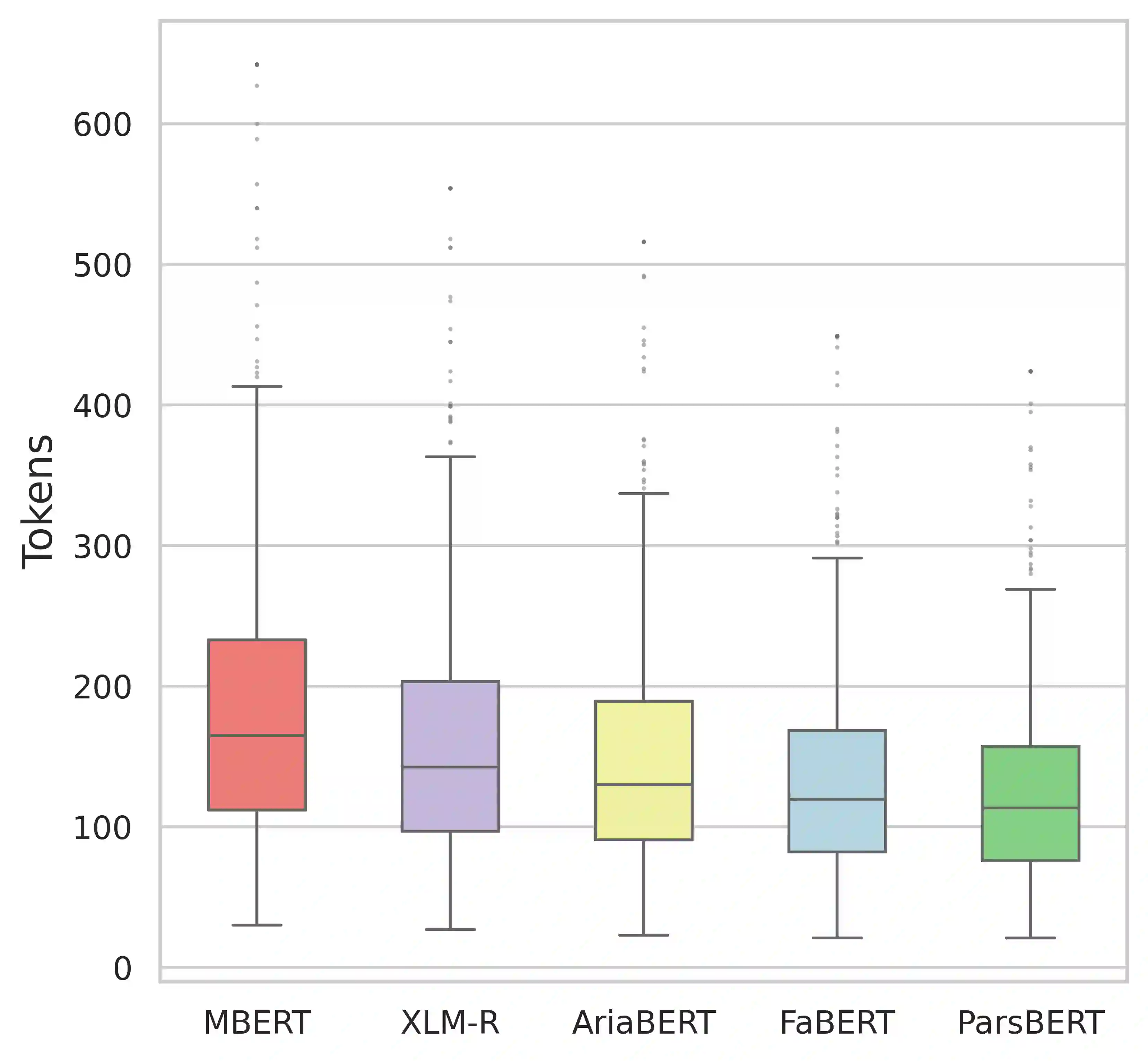
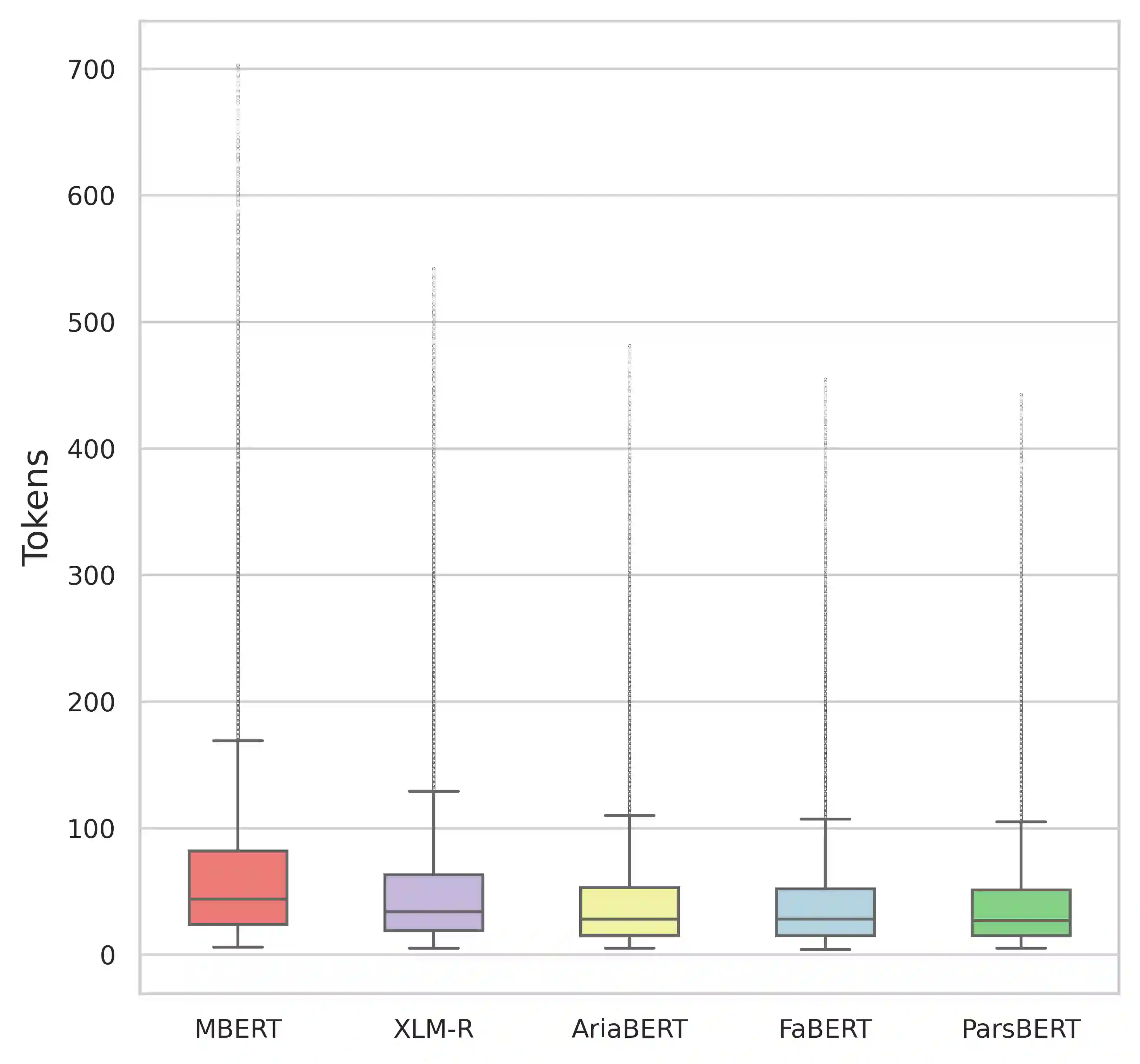
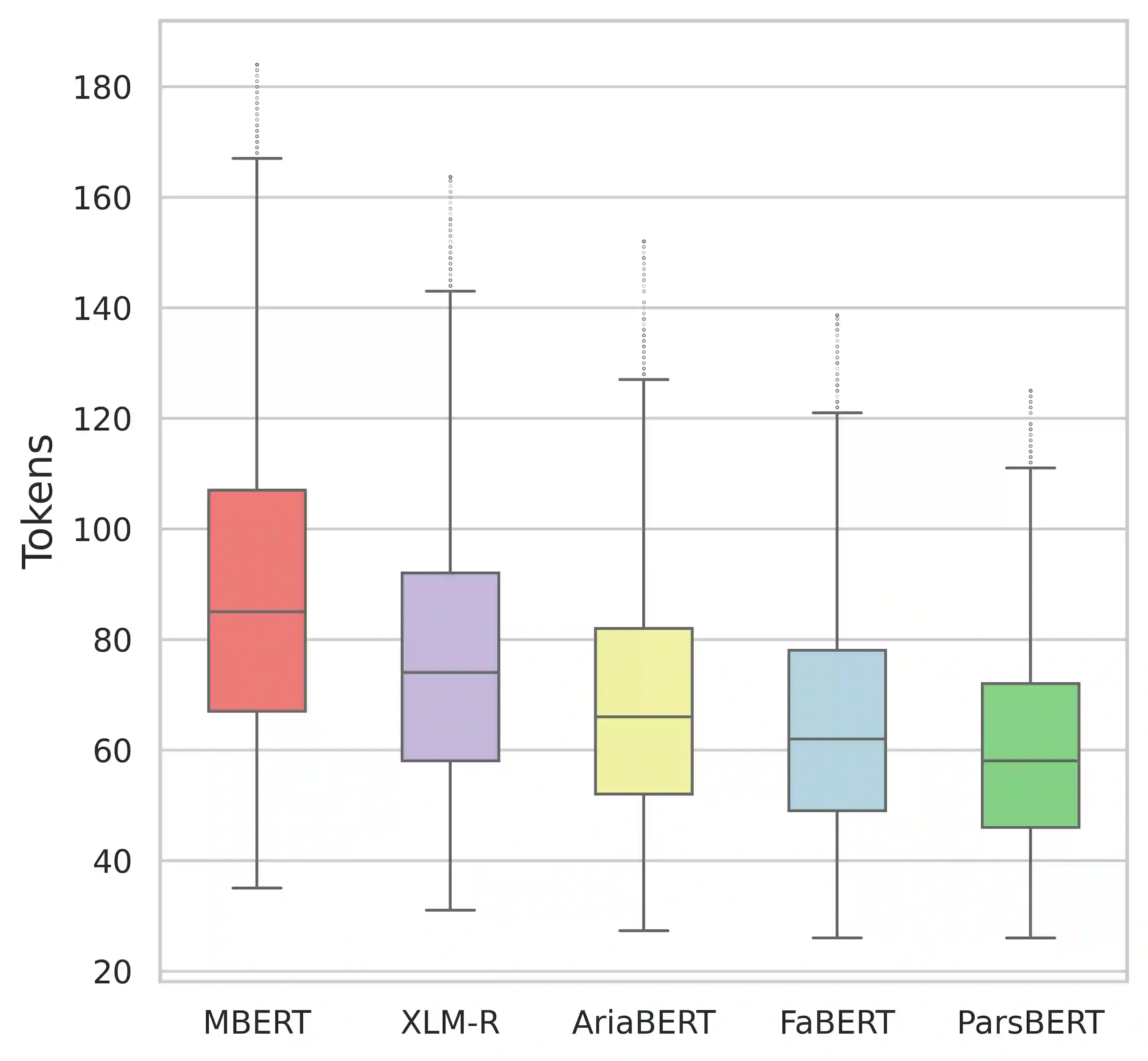
We introduce FaBERT, a Persian BERT-base model pre-trained on the HmBlogs corpus, encompassing both informal and formal Persian texts. FaBERT is designed to excel in traditional Natural Language Understanding (NLU) tasks, addressing the intricacies of diverse sentence structures and linguistic styles prevalent in the Persian language. In our comprehensive evaluation of FaBERT on 12 datasets in various downstream tasks, encompassing Sentiment Analysis (SA), Named Entity Recognition (NER), Natural Language Inference (NLI), Question Answering (QA), and Question Paraphrasing (QP), it consistently demonstrated improved performance, all achieved within a compact model size. The findings highlight the importance of utilizing diverse and cleaned corpora, such as HmBlogs, to enhance the performance of language models like BERT in Persian Natural Language Processing (NLP) applications. FaBERT is openly accessible at https://huggingface.co/sbunlp/fabert
翻译:我们提出了FaBERT,一个在HmBlogs语料库上预训练的波斯语BERT-base模型,该语料库涵盖非正式和正式的波斯语文本。FaBERT旨在传统自然语言理解任务中表现出色,处理波斯语中多样的句子结构和语言风格所固有的复杂性。在我们对12个数据集进行的包括情感分析、命名实体识别、自然语言推理、问答和问题释义在内的下游任务全面评估中,FaBERT始终展现出改进的性能,所有这些均在一个紧凑的模型大小内实现。研究结果强调了利用多样化且清洗过的语料库(如HmBlogs)对于提升类似BERT的语言模型在波斯语自然语言处理应用中性能的重要性。FaBERT可在 https://huggingface.co/sbunlp/fabert 公开获取。