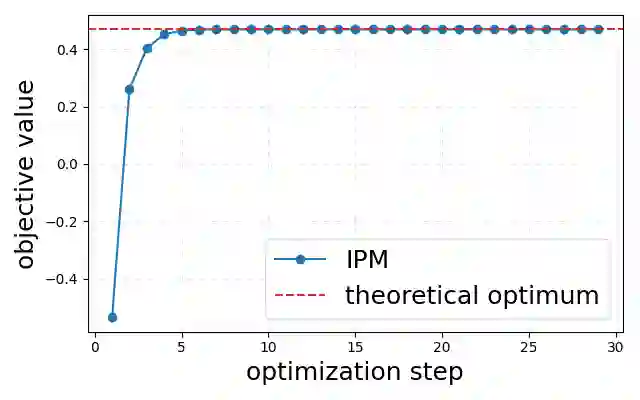
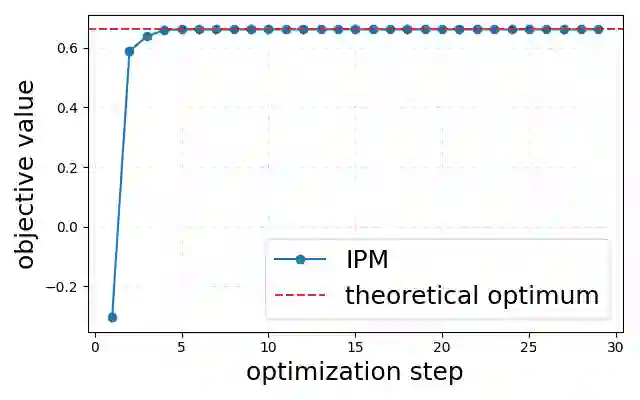
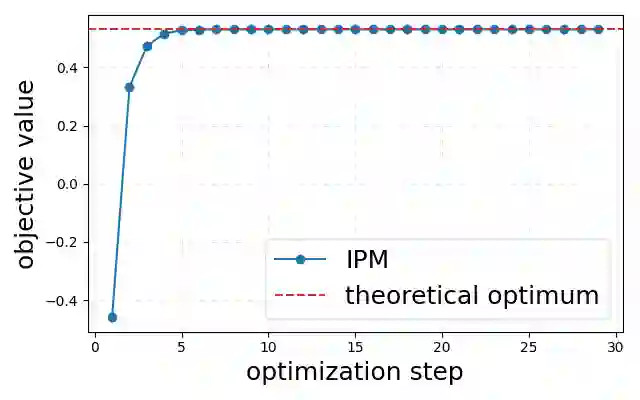
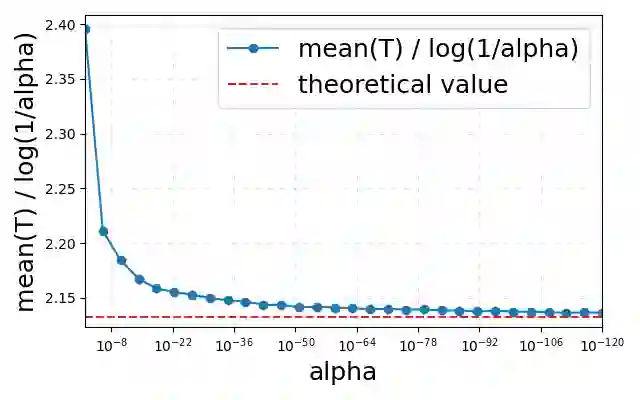
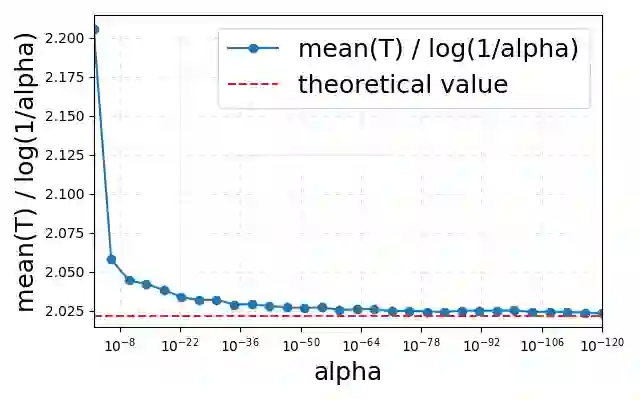
The proliferation of Large Language Models (LLMs) necessitates efficient mechanisms to distinguish machine-generated content from human text. While statistical watermarking has emerged as a promising solution, existing methods suffer from two critical limitations: the lack of a principled approach for selecting sampling distributions and the reliance on fixed-horizon hypothesis testing, which precludes valid early stopping. In this paper, we bridge this gap by developing the first e-value-based watermarking framework, Anchored E-Watermarking, that unifies optimal sampling with anytime-valid inference. Unlike traditional approaches where optional stopping invalidates Type-I error guarantees, our framework enables valid, anytime-inference by constructing a test supermartingale for the detection process. By leveraging an anchor distribution to approximate the target model, we characterize the optimal e-value with respect to the worst-case log-growth rate and derive the optimal expected stopping time. Our theoretical claims are substantiated by simulations and evaluations on established benchmarks, showing that our framework can significantly enhance sample efficiency, reducing the average token budget required for detection by 13-15% relative to state-of-the-art baselines.
翻译:大型语言模型(LLM)的激增迫切需要高效的机制来区分机器生成内容与人类文本。尽管统计水印已成为一种有前景的解决方案,但现有方法存在两个关键局限:缺乏选择采样分布的原则性方法,以及依赖固定水平假设检验,这排除了有效的早期停止。在本文中,我们通过开发首个基于e值的水印框架——锚定E水印,弥合了这一差距,该框架将最优采样与任意时间有效推断相统一。与传统方法中可选停止会使第一类错误保证失效不同,我们的框架通过为检测过程构建一个检验超鞅,实现了有效的任意时间推断。通过利用锚定分布来近似目标模型,我们刻画了关于最坏情况对数增长率的最优e值,并推导出最优期望停止时间。我们的理论主张通过仿真和在既定基准上的评估得到了证实,结果表明,相对于最先进的基线方法,我们的框架能够显著提升样本效率,将检测所需的平均令牌预算减少13-15%。