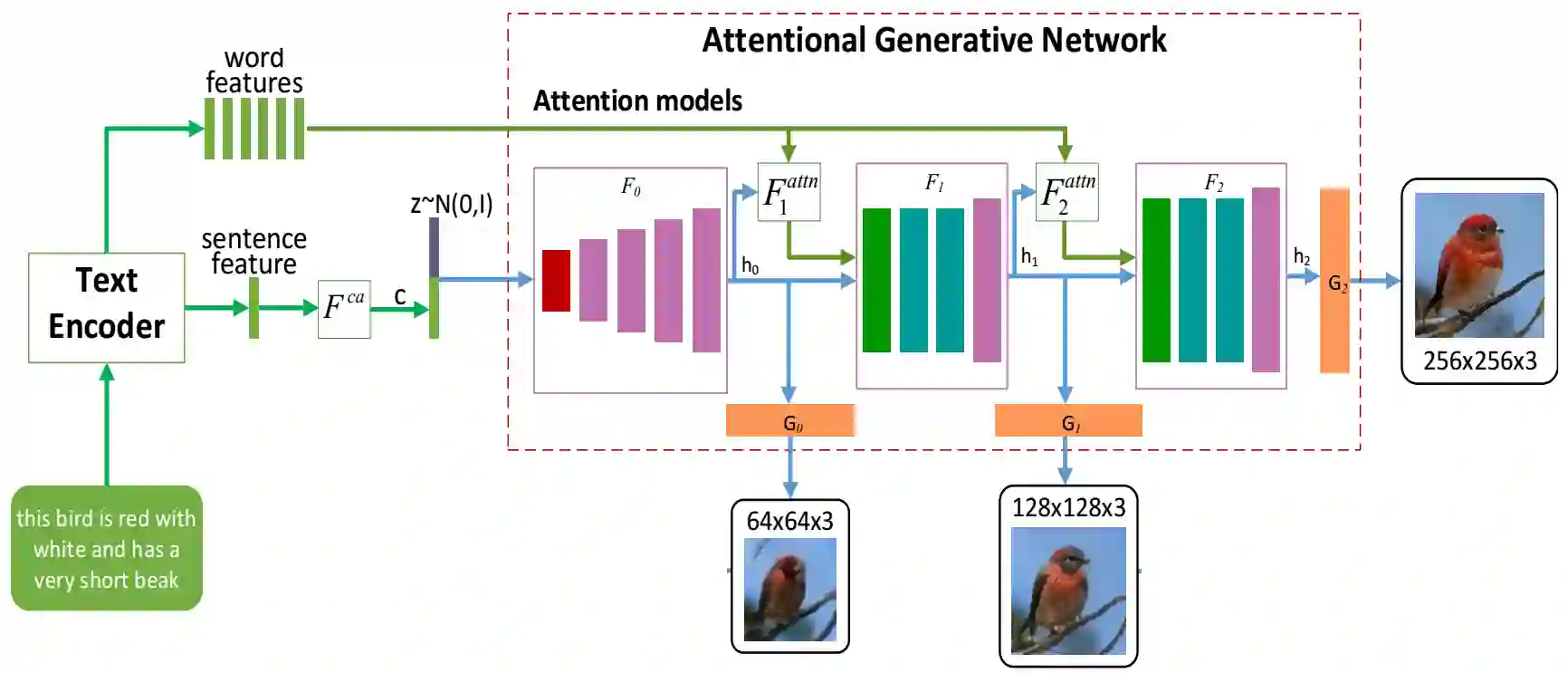
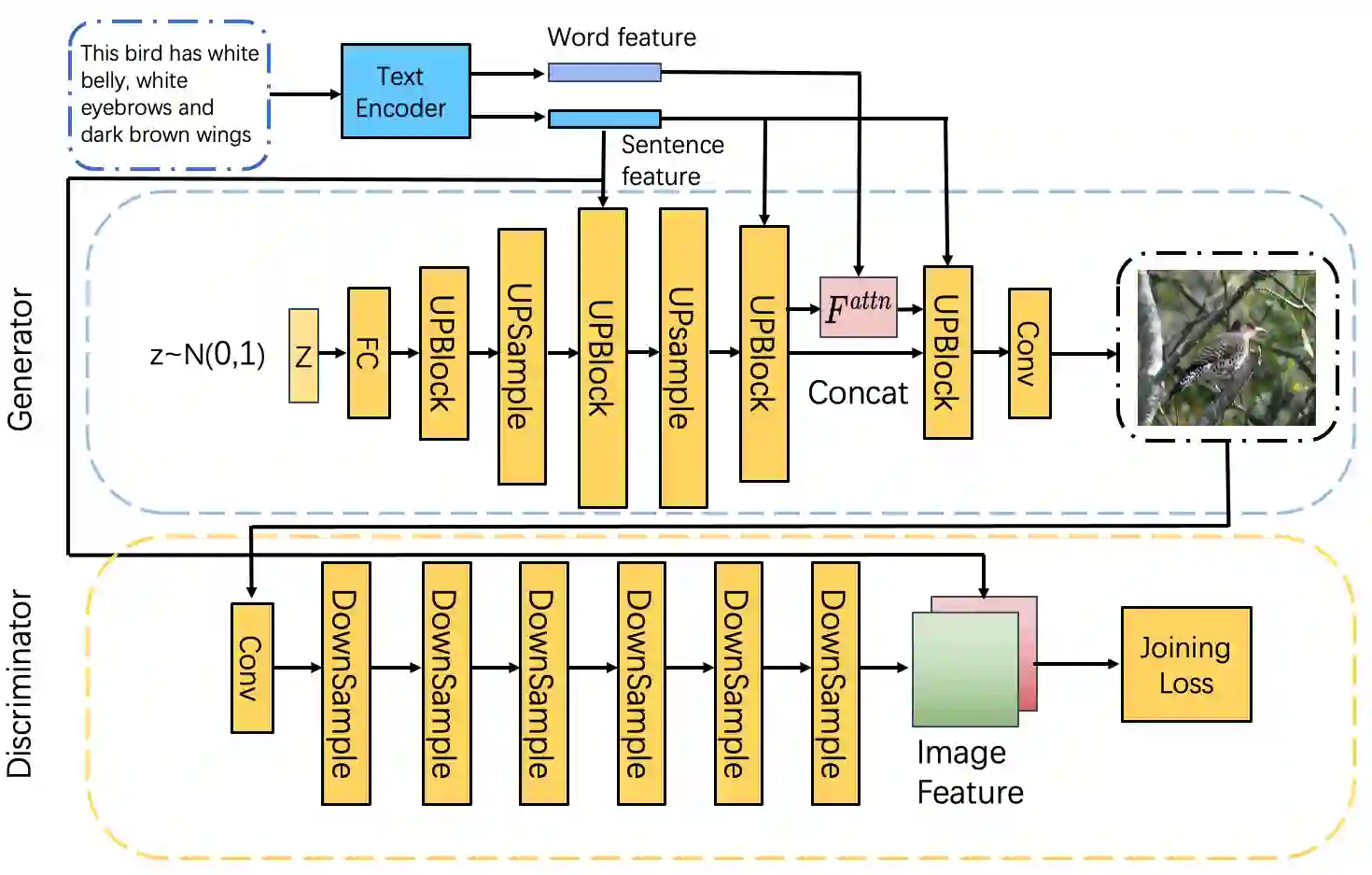
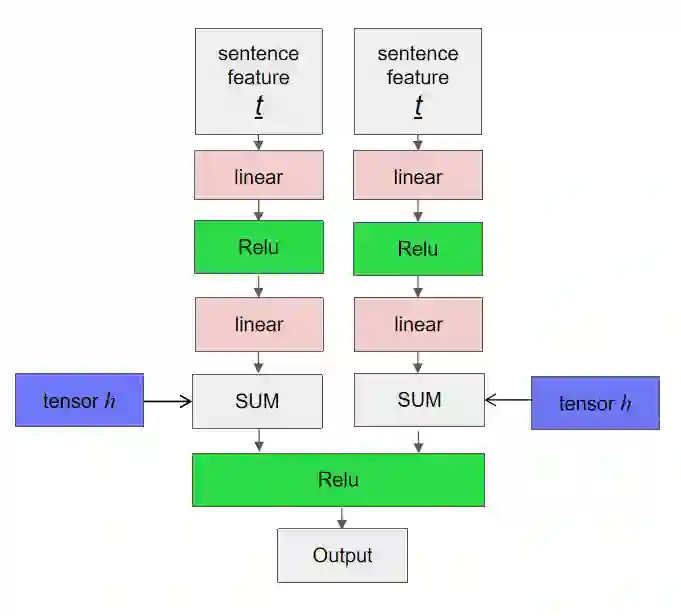
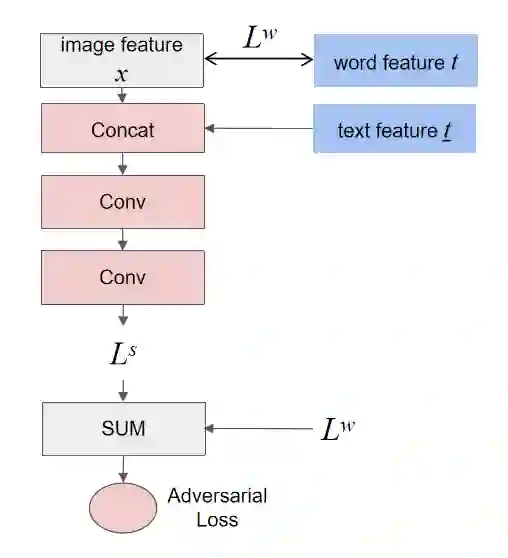
Synthesising a text-to-image model of high-quality images by guiding the generative model through the Text description is an innovative and challenging task. In recent years, AttnGAN based on the Attention mechanism to guide GAN training has been proposed, SD-GAN, which adopts a self-distillation technique to improve the performance of the generator and the quality of image generation, and Stack-GAN++, which gradually improves the details and quality of the image by stacking multiple generators and discriminators. However, this series of improvements to GAN all have redundancy to a certain extent, which affects the generation performance and complexity to a certain extent. We use the popular simple and effective idea (1) to remove redundancy structure and improve the backbone network of AttnGAN. (2) to integrate and reconstruct multiple losses of DAMSM. Our improvements have significantly improved the model size and training efficiency while ensuring that the model's performance is unchanged and finally proposed our SEAttnGAN. Code is avalilable at https://github.com/jmyissb/SEAttnGAN.
翻译:通过文本描述引导生成模型合成高质量图像的文本到图像模型是一项创新且具有挑战性的任务。近年来,基于注意力机制引导GAN训练的AttnGAN、采用自蒸馏技术提升生成器性能和图像生成质量的SD-GAN,以及通过堆叠多个生成器和判别器逐步提升图像细节与质量的Stack-GAN++相继被提出。然而,这一系列针对GAN的改进在一定程度上均存在冗余问题,影响了生成性能和复杂度。我们采用流行的"简单有效"思想:(1) 去除冗余结构,改进AttnGAN的主干网络;(2) 集成并重构DAMSM的多重损失函数。我们的改进在确保模型性能不变的同时,显著减小了模型尺寸并提升了训练效率,最终提出了SEAttnGAN。代码开源地址:https://github.com/jmyissb/SEAttnGAN。