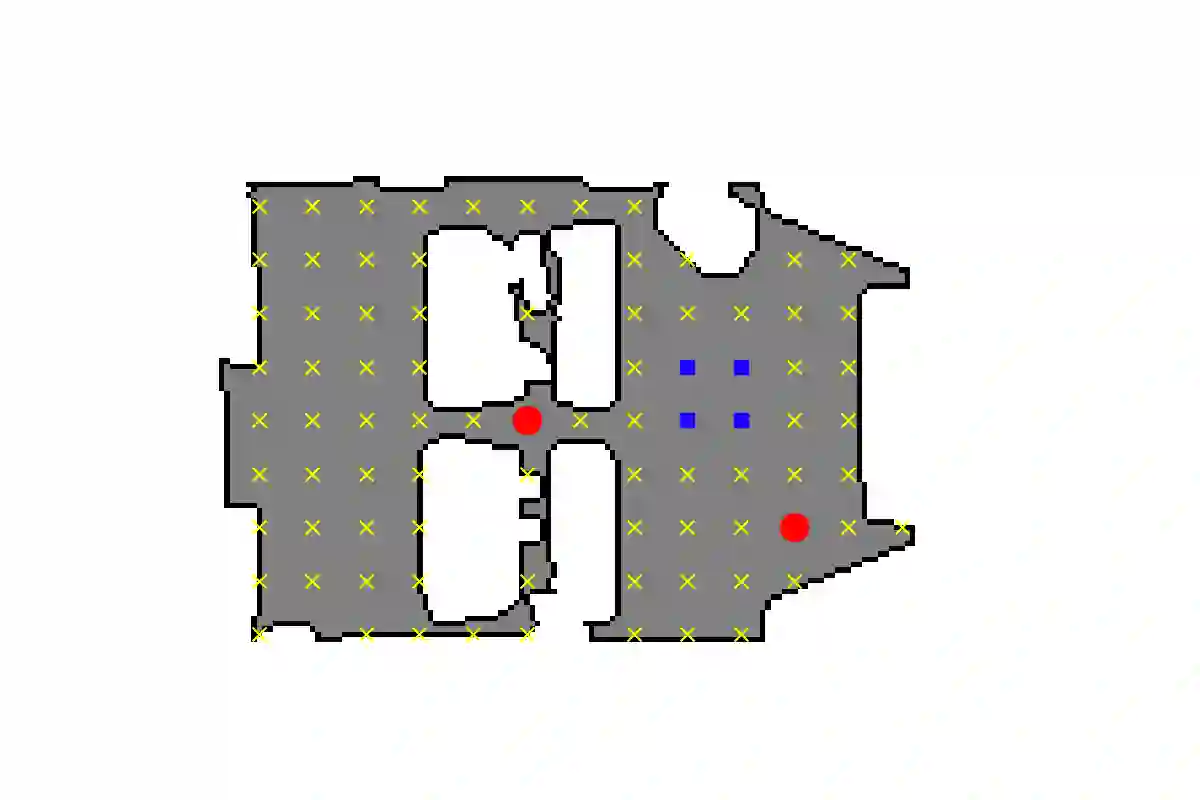
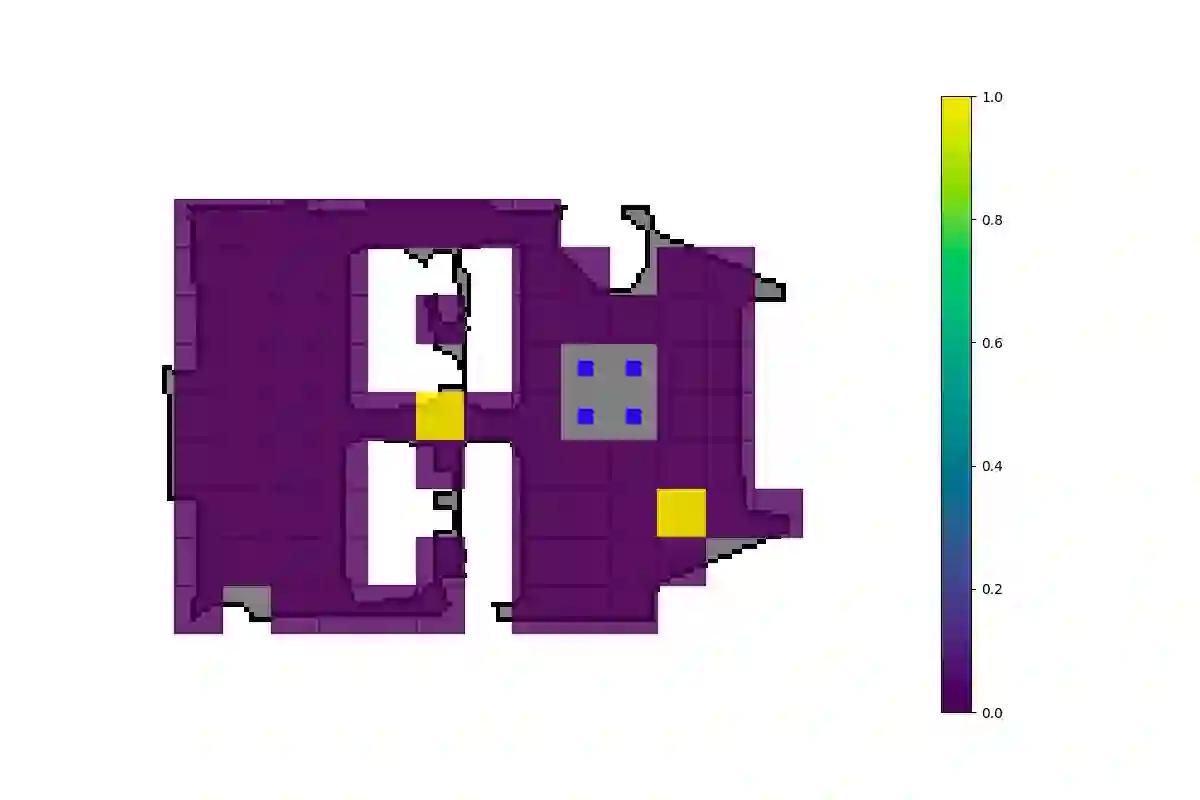
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
翻译:我们研究了将盲音频记录与3D场景信息相结合对新视角声学合成的益处。给定来自2-4个麦克风的音频记录以及包含多个未知声源的场景的3D几何与材质信息,我们可估计场景中任意位置的声场。我们指出新视角声学合成的主要挑战在于声源定位、分离和去混响。尽管直接训练端到端网络无法产生高质量结果,但我们证明:引入基于3D重建房间导出的房间冲激响应(RIRs)能使同一网络协同处理这些任务。我们的方法优于针对各子任务设计的现有方法,展现了利用3D视觉信息的有效性。在Matterport3D-NVAS数据集上的仿真研究中,我们的模型在声源定位任务上达到近乎完美的准确率,在声源分离和去混响任务上实现26.44 dB的PSNR和14.23 dB的SDR,最终在新视角声学合成任务上达到25.55 dB的PSNR和14.20 dB的SDR。代码、预训练模型及视频结果详见项目主页(https://github.com/apple/ml-nvas3d)。