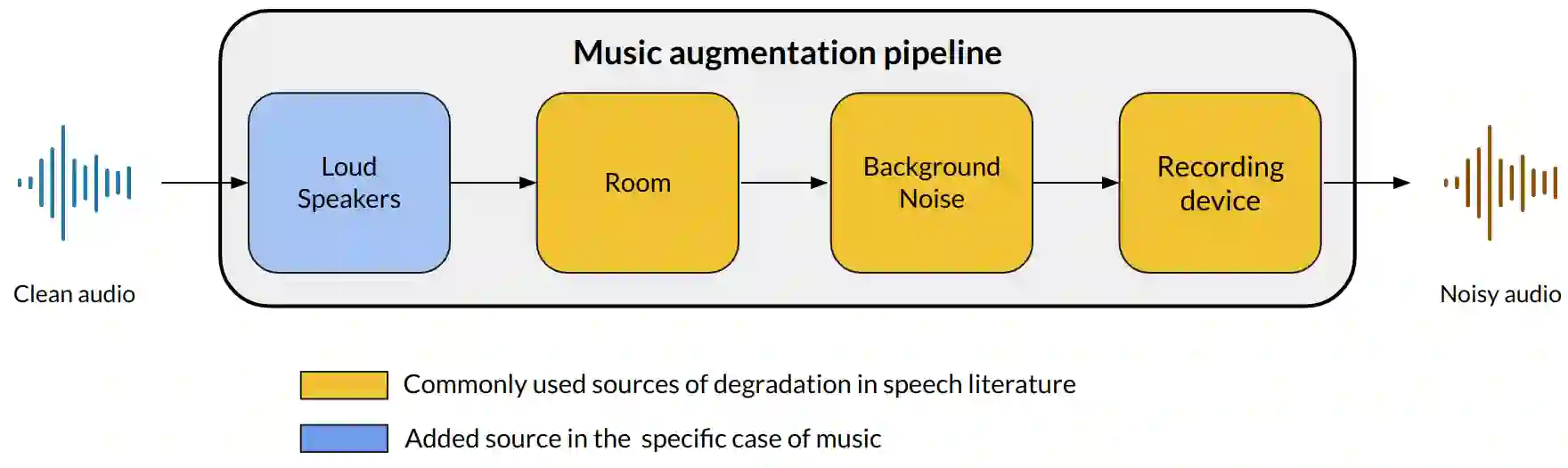
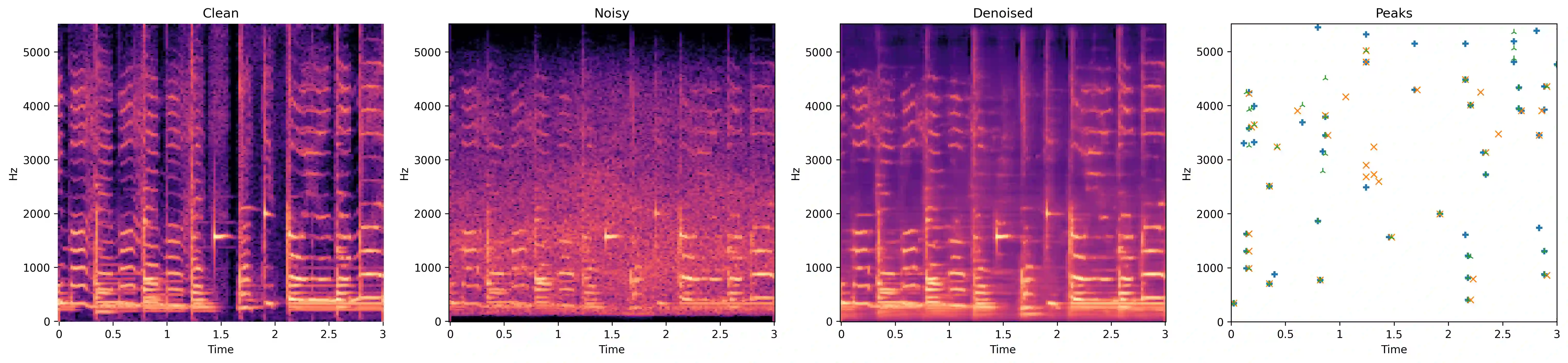
Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions.
翻译:音频指纹是一种从短录音片段中识别歌曲的成熟解决方案。主流方法依赖稀疏表示(通常为频谱峰值)的提取,已被证明兼具准确性、快速性及大规模数据库的扩展性。然而,音频识别的实际应用常发生在嘈杂环境中,这可能导致此类系统失效。本研究通过引入并开源一种新型音频增强流水线来解决该问题,该流水线通过随机模拟真实场景,以贴近实际的方式向音乐片段添加噪声。我们进一步提出并开源一个深度学习模型,用于从频谱图中去除噪声成分,以提升基于峰值指纹系统的准确性。实验表明,即使在高噪声条件下,引入该模型也能显著提高常用音频指纹系统的识别性能。