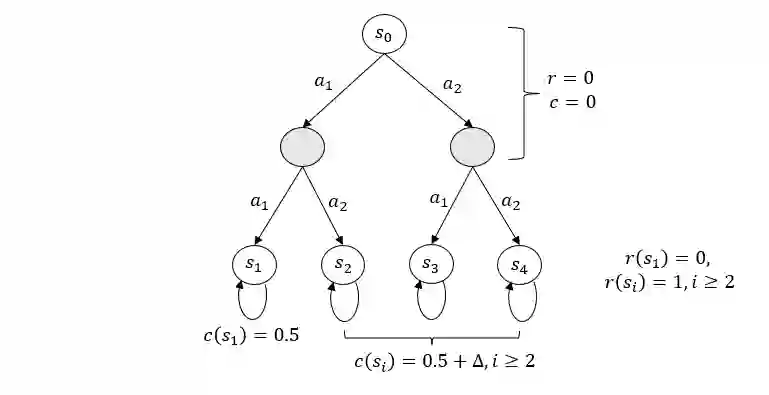
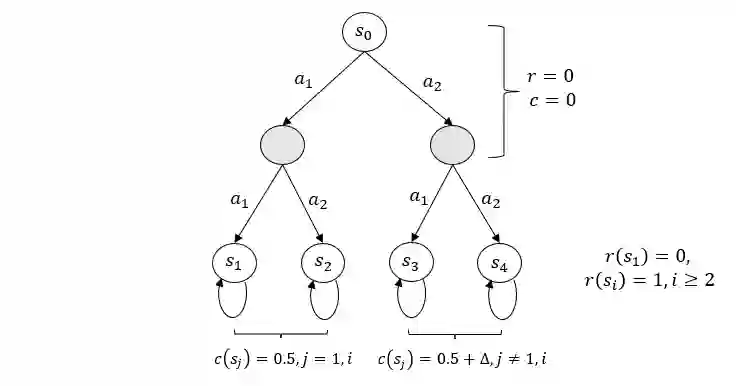
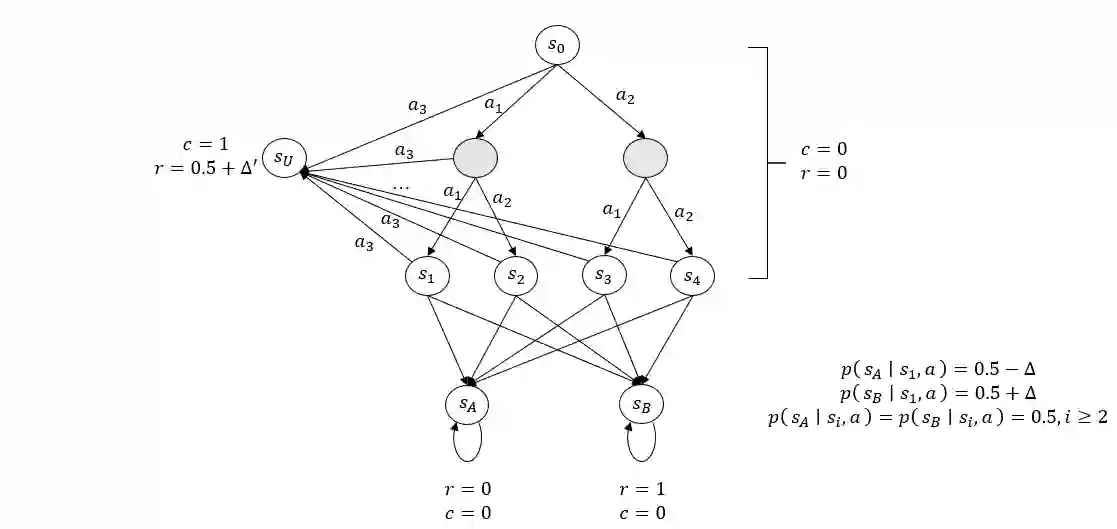
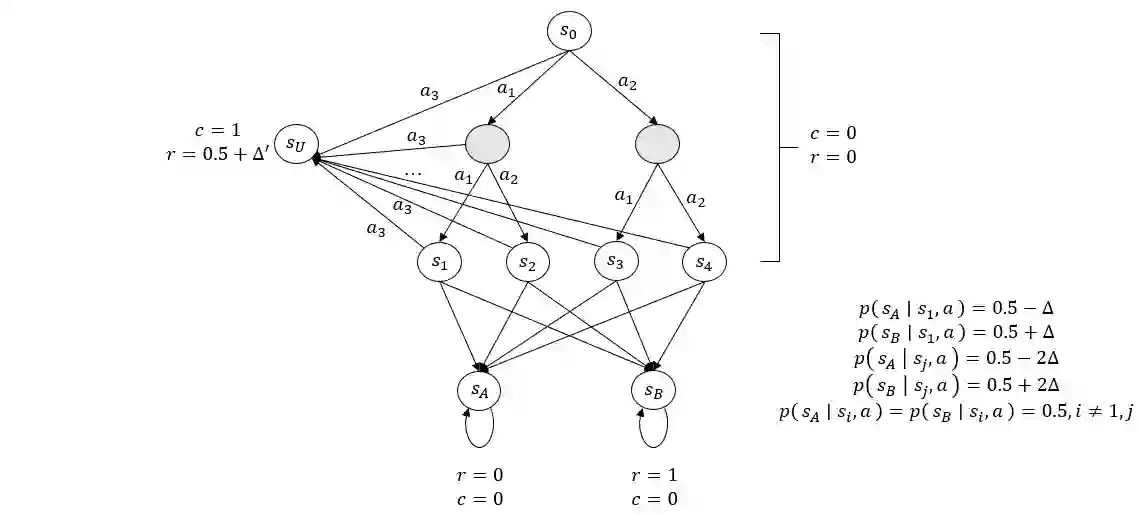
In this paper, we investigate a novel safe reinforcement learning problem with step-wise violation constraints. Our problem differs from existing works in that we consider stricter step-wise violation constraints and do not assume the existence of safe actions, making our formulation more suitable for safety-critical applications which need to ensure safety in all decision steps and may not always possess safe actions, e.g., robot control and autonomous driving. We propose a novel algorithm SUCBVI, which guarantees $\widetilde{O}(\sqrt{ST})$ step-wise violation and $\widetilde{O}(\sqrt{H^3SAT})$ regret. Lower bounds are provided to validate the optimality in both violation and regret performance with respect to $S$ and $T$. Moreover, we further study a novel safe reward-free exploration problem with step-wise violation constraints. For this problem, we design an $(\varepsilon,\delta)$-PAC algorithm SRF-UCRL, which achieves nearly state-of-the-art sample complexity $\widetilde{O}((\frac{S^2AH^2}{\varepsilon}+\frac{H^4SA}{\varepsilon^2})(\log(\frac{1}{\delta})+S))$, and guarantees $\widetilde{O}(\sqrt{ST})$ violation during the exploration. The experimental results demonstrate the superiority of our algorithms in safety performance, and corroborate our theoretical results.
翻译:本文研究了一种具有逐步违反约束的新型安全强化学习问题。与现有工作不同,我们考虑了更严格的逐步违反约束,且不假设存在安全动作,这使得我们的公式更适用于需要在所有决策步骤中确保安全性且可能不具备安全动作的安全关键应用,例如机器人控制和自动驾驶。我们提出了一种新颖算法SUCBVI,该算法保证了$\widetilde{O}(\sqrt{ST})$的逐步违反和$\widetilde{O}(\sqrt{H^3SAT})$的遗憾值。通过下界验证了在违反和遗憾性能方面关于$S$和$T$的最优性。此外,我们进一步研究了具有逐步违反约束的新型安全无奖励探索问题。针对此问题,我们设计了一种$(\varepsilon,\delta)$-PAC算法SRF-UCRL,其实现了近乎最先进的样本复杂度$\widetilde{O}((\frac{S^2AH^2}{\varepsilon}+\frac{H^4SA}{\varepsilon^2})(\log(\frac{1}{\delta})+S))$,并在探索过程中保证了$\widetilde{O}(\sqrt{ST})$的违反。实验结果证明了我们算法在安全性能上的优越性,并验证了我们的理论结果。