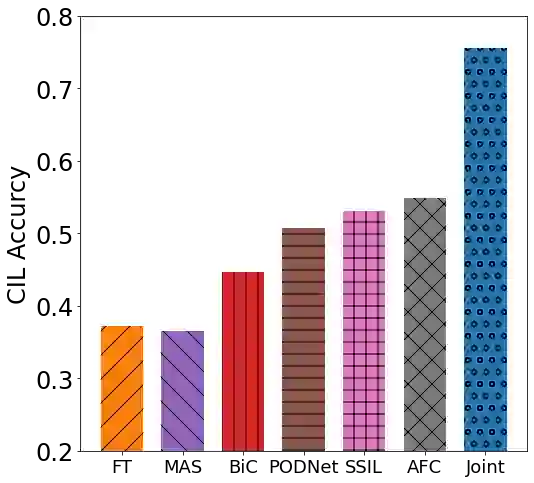
Class incremental learning (CIL) algorithms aim to continually learn new object classes from incrementally arriving data while not forgetting past learned classes. The common evaluation protocol for CIL algorithms is to measure the average test accuracy across all classes learned so far -- however, we argue that solely focusing on maximizing the test accuracy may not necessarily lead to developing a CIL algorithm that also continually learns and updates the representations, which may be transferred to the downstream tasks. To that end, we experimentally analyze neural network models trained by CIL algorithms using various evaluation protocols in representation learning and propose new analysis methods. Our experiments show that most state-of-the-art algorithms prioritize high stability and do not significantly change the learned representation, and sometimes even learn a representation of lower quality than a naive baseline. However, we observe that these algorithms can still achieve high test accuracy because they enable a model to learn a classifier that closely resembles an estimated linear classifier trained for linear probing. Furthermore, the base model learned in the first task, which involves single-task learning, exhibits varying levels of representation quality across different algorithms, and this variance impacts the final performance of CIL algorithms. Therefore, we suggest that the representation-level evaluation should be considered as an additional recipe for more diverse evaluation for CIL algorithms.
翻译:类别增量学习(CIL)算法旨在从增量到达的数据中持续学习新的对象类别,同时不遗忘过去已学习的类别。CIL算法的通用评估协议是测量迄今为止学习的所有类别的平均测试准确率——然而,我们认为仅仅专注于最大化测试准确率,未必能开发出也能持续学习和更新表征的CIL算法,而这些表征可能迁移至下游任务。为此,我们使用表征学习中的多种评估协议,对通过CIL算法训练的神经网络模型进行了实验分析,并提出了新的分析方法。我们的实验表明,大多数最先进的算法优先考虑高稳定性,并未显著改变已学习的表征,有时甚至学习到比朴素基线质量更低的表征。然而,我们观察到这些算法仍能实现较高的测试准确率,因为它们使模型能够学习到一个与为线性探测训练而估计的线性分类器非常相似的分类器。此外,在第一个任务(涉及单任务学习)中学习到的基础模型,在不同算法间表现出不同水平的表征质量,这种差异影响了CIL算法的最终性能。因此,我们建议应将表征层面的评估视为对CIL算法进行更多样化评估的附加方案。