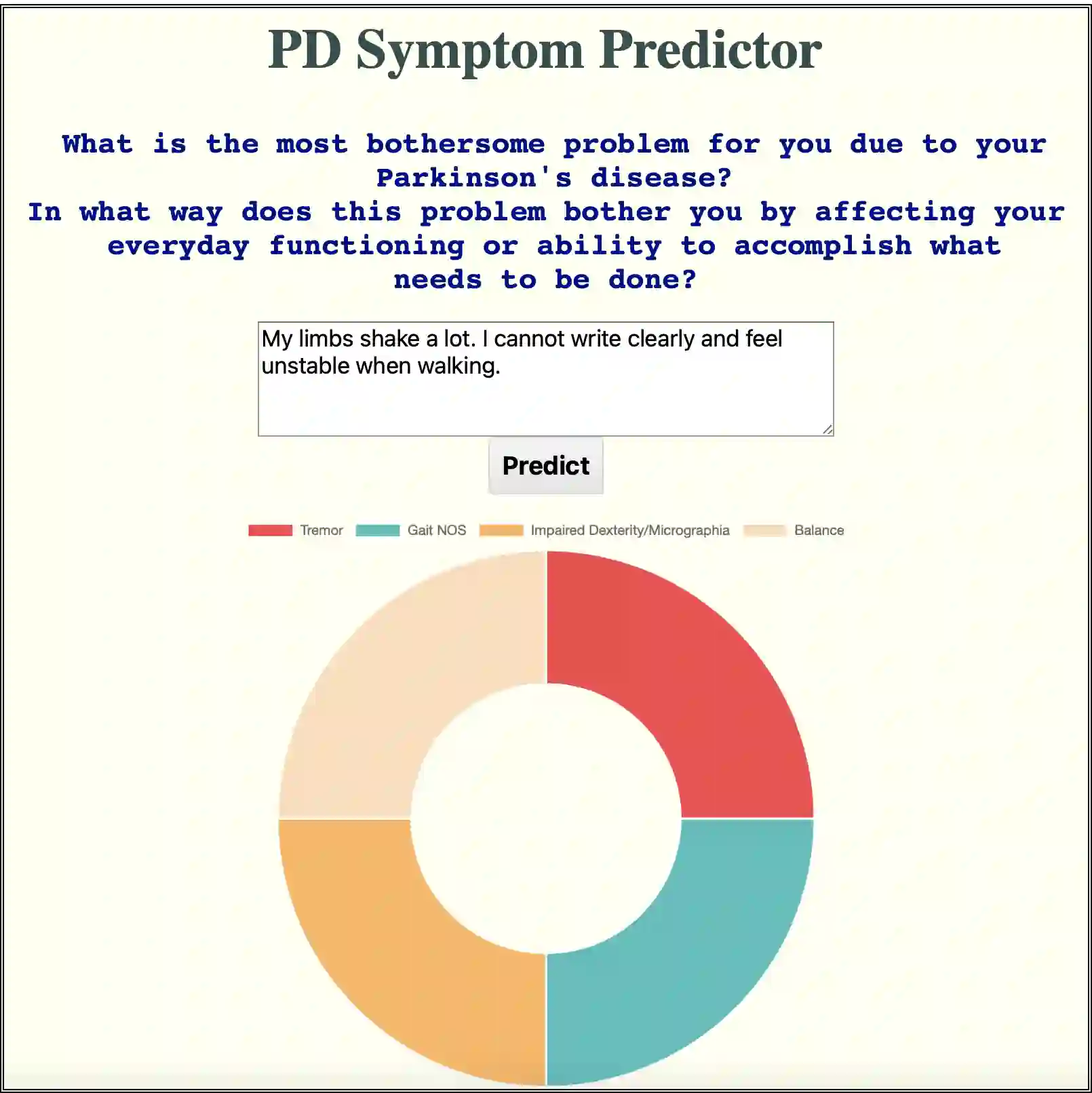
The USA Food and Drug Administration has accorded increasing importance to patient-reported problems in clinical and research settings. In this paper, we explore one of the largest online datasets comprising 170,141 open-ended self-reported responses (called "verbatims") from patients with Parkinson's (PwPs) to questions about what bothers them about their Parkinson's Disease and how it affects their daily functioning, also known as the Parkinson's Disease Patient Report of Problems. Classifying such verbatims into multiple clinically relevant symptom categories is an important problem and requires multiple steps - expert curation, a multi-label text classification (MLTC) approach and large amounts of labelled training data. Further, human annotation of such large datasets is tedious and expensive. We present a novel solution to this problem where we build a baseline dataset using 2,341 (of the 170,141) verbatims annotated by nine curators including clinical experts and PwPs. We develop a rules based linguistic-dictionary using NLP techniques and graph database-based expert phrase-query system to scale the annotation to the remaining cohort generating the machine annotated dataset, and finally build a Keras-Tensorflow based MLTC model for both datasets. The machine annotated model significantly outperforms the baseline model with a F1-score of 95% across 65 symptom categories on a held-out test set.
翻译:美国食品药品监督管理局日益重视临床和研究场景中患者报告问题的重要性。本文探索了最大的在线数据集之一,包含170,141份帕金森患者对"帕金森病困扰因素及其对日常功能影响"问题的开放式自我报告(称为"原始陈述"),即帕金森病患者问题报告。将这些原始陈述分类至多个临床相关症状类别是一项重要任务,需经专家审核、多标签文本分类方法及大量标注训练数据等多个步骤。此外,人工标注如此大规模数据集既繁琐又昂贵。我们提出一种创新解决方案:首先利用9位审核员(包括临床专家和帕金森患者)标注的2,341份原始陈述构建基线数据集;继而结合基于自然语言处理技术的规则型语言词典与基于图数据库的专家短语查询系统,将标注扩展至剩余队列并生成机器标注数据集;最终基于Keras-Tensorflow框架为两个数据集构建多标签文本分类模型。在包含65个症状类别的留存测试集上,机器标注模型的F1分数达95%,显著优于基线模型。