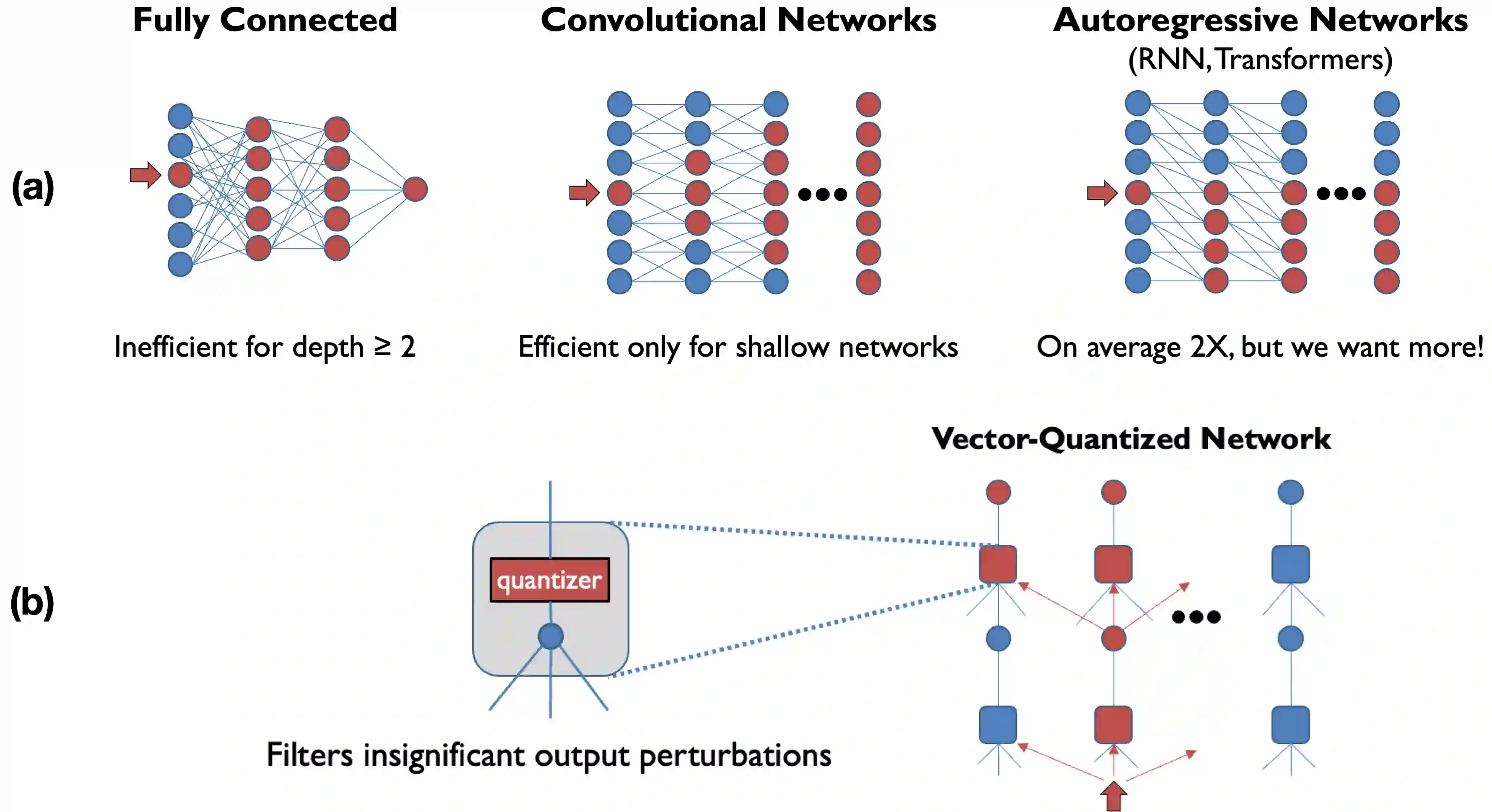
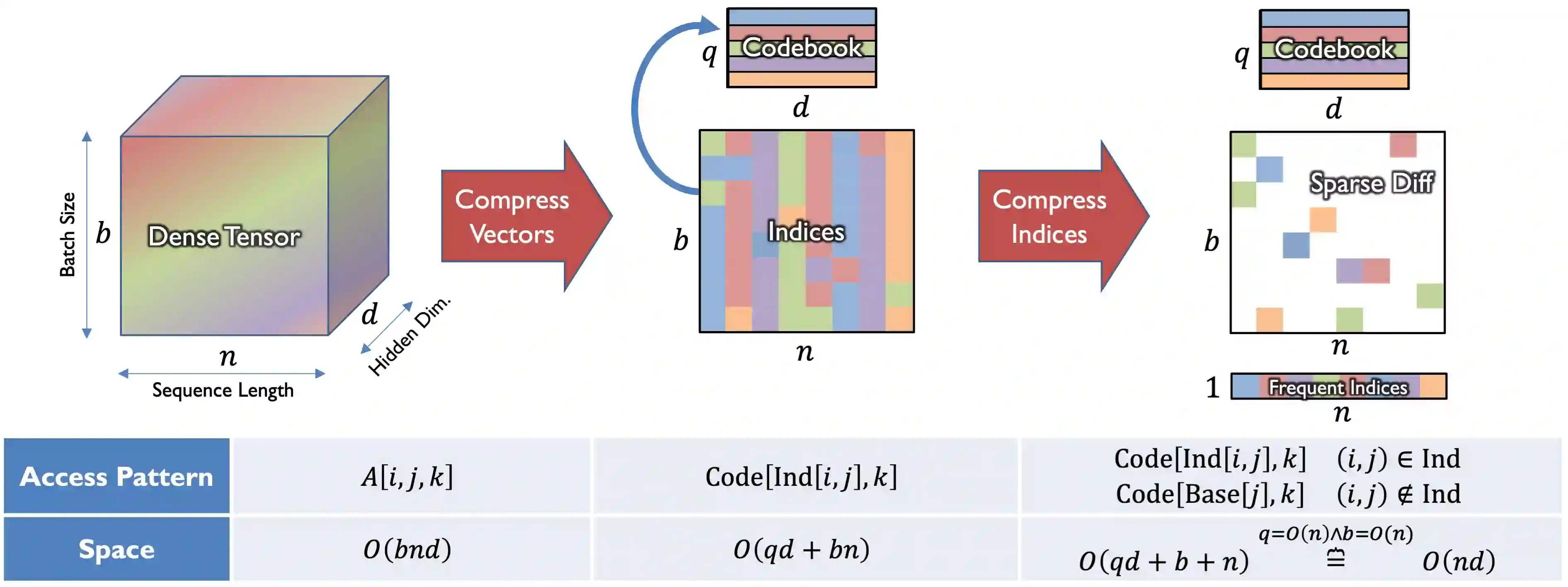
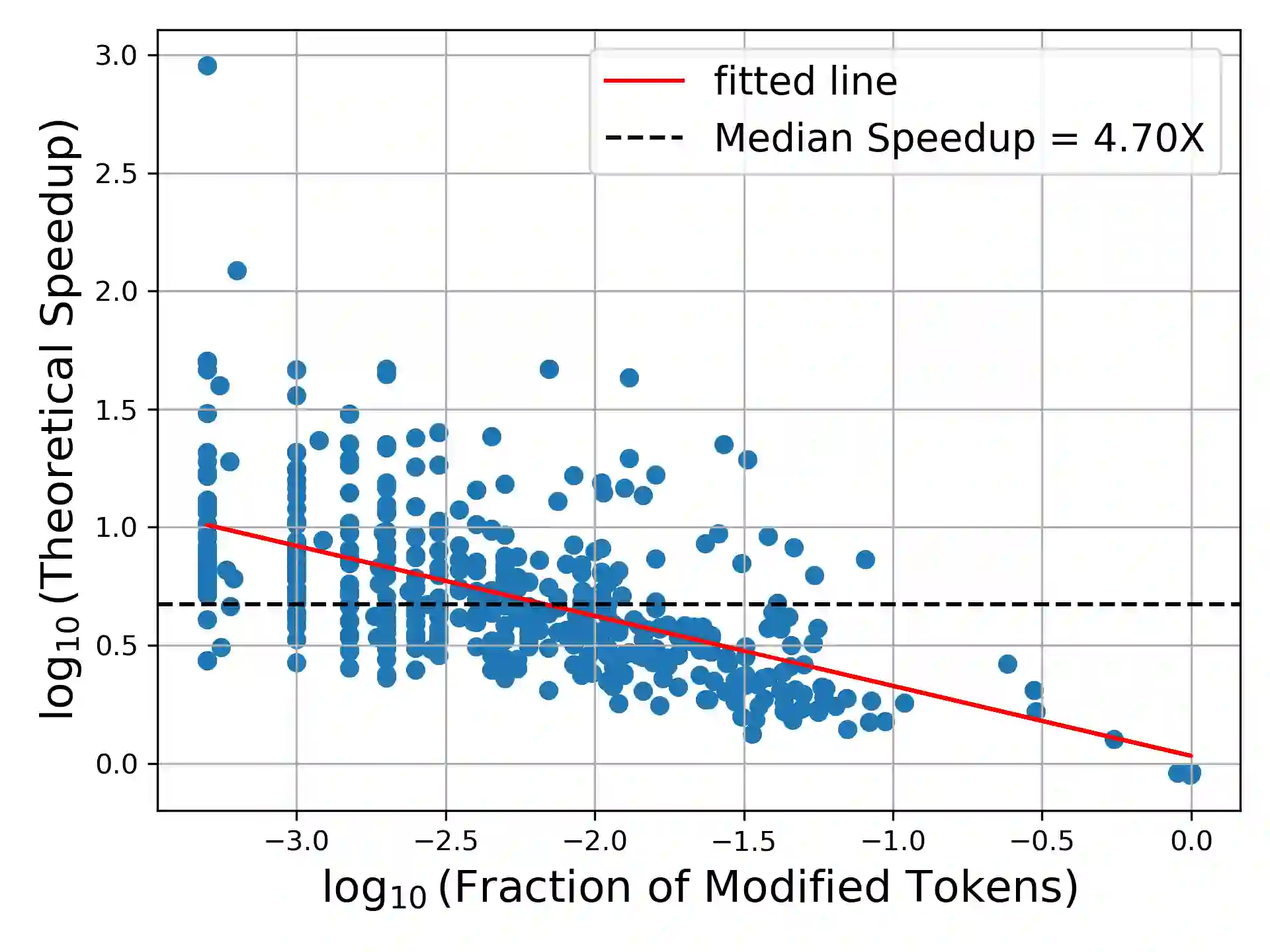
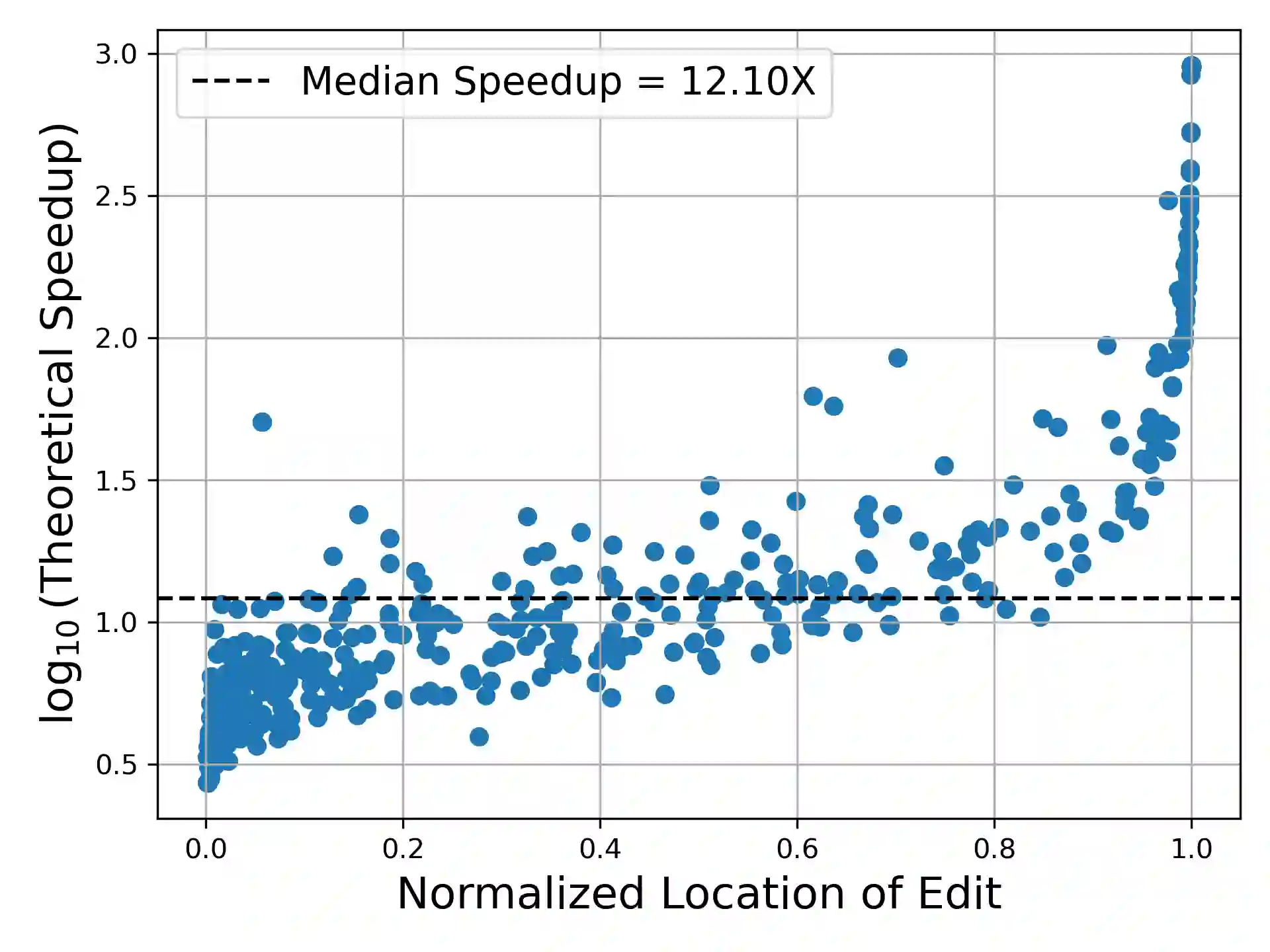
Deep learning often faces the challenge of efficiently processing dynamic inputs, such as sensor data or user inputs. For example, an AI writing assistant is required to update its suggestions in real time as a document is edited. Re-running the model each time is expensive, even with compression techniques like knowledge distillation, pruning, or quantization. Instead, we take an incremental computing approach, looking to reuse calculations as the inputs change. However, the dense connectivity of conventional architectures poses a major obstacle to incremental computation, as even minor input changes cascade through the network and restrict information reuse. To address this, we use vector quantization to discretize intermediate values in the network, which filters out noisy and unnecessary modifications to hidden neurons, facilitating the reuse of their values. We apply this approach to the transformers architecture, creating an efficient incremental inference algorithm with complexity proportional to the fraction of the modified inputs. Our experiments with adapting the OPT-125M pre-trained language model demonstrate comparable accuracy on document classification while requiring 12.1X (median) fewer operations for processing sequences of atomic edits.
翻译:深度学习经常面临高效处理动态输入(如传感器数据或用户输入)的挑战。例如,AI写作助手需要在文档被编辑时实时更新其建议。即使采用知识蒸馏、剪枝或量化等压缩技术,每次重新运行模型代价仍然高昂。为此,我们采用增量计算方法,期望在输入发生变化时复用已有计算结果。然而,传统架构的密集连接性对增量计算构成了重大障碍——即便是微小的输入变化也会在网络中层叠传播,限制信息复用。为解决这一问题,我们利用向量量化将网络中间值离散化,从而滤除对隐藏神经元的噪声性及非必要修改,促进其值复用。我们将该方法应用于Transformer架构,设计出高效的增量推理算法,其计算复杂度与修改输入的比例成正比。在基于OPT-125M预训练语言模型的实验中,我们的方法在文档分类任务中保持相当准确率的同时,处理连续原子编辑序列时所需运算量中位数减少了12.1倍。