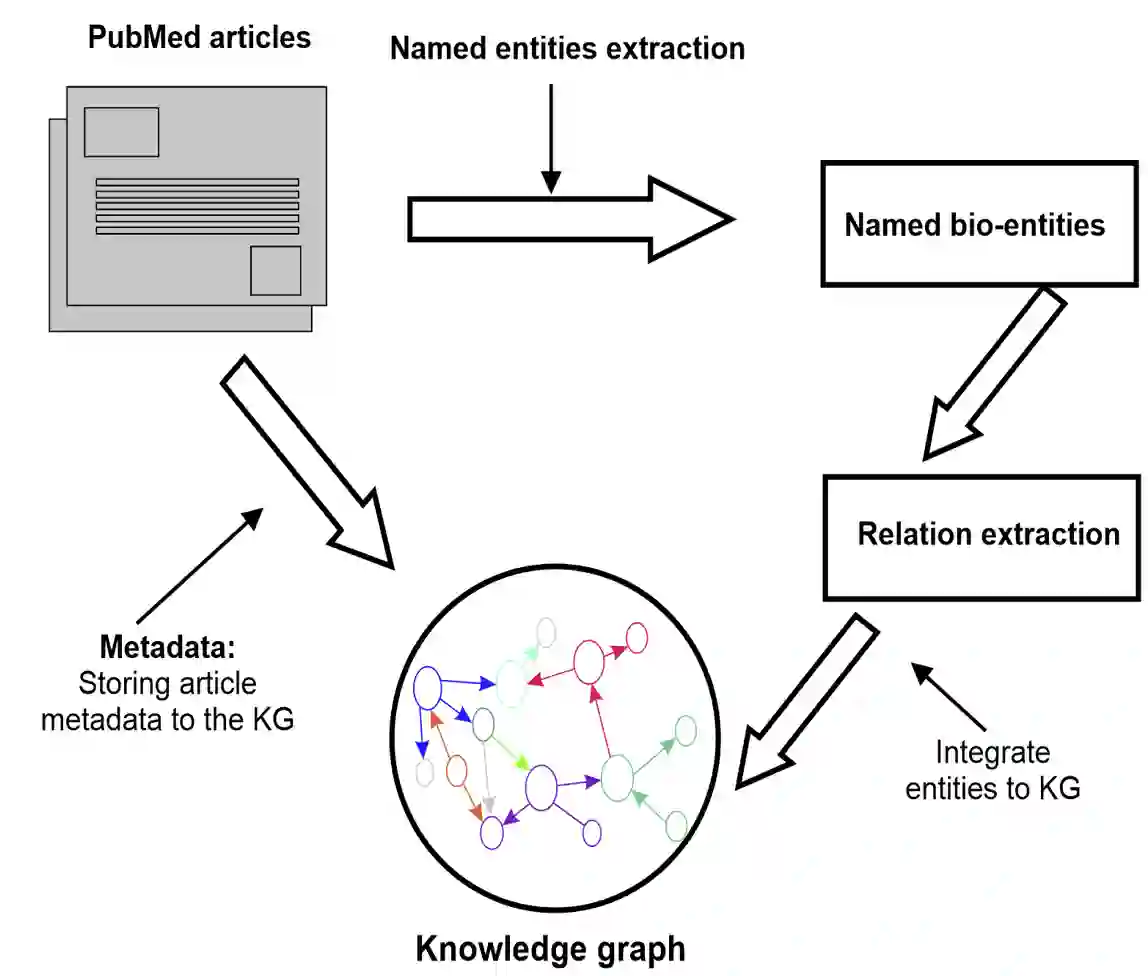
Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A domain-specific knowledge graph~(KG) is an explicit conceptualization of a specific subject-matter domain represented w.r.t semantically interrelated entities and relations. A KG can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. Such a KG will not only allow deducing new knowledge and question answering(QA) but also allows domain experts to explore. Since cross-disciplinary explanations are important for accurate diagnosis, it is important to query the KG to provide interactive explanations about learned biomarkers. Inspired by these, we construct a domain-specific KG, particularly for cancer-specific biomarker discovery. The KG is constructed by integrating cancer-related knowledge and facts from multiple sources. First, we construct a domain-specific ontology, which we call OncoNet Ontology (ONO). The ONO ontology is developed to enable semantic reasoning for verification of the predictions for relations between diseases and genes. The KG is then developed and enriched by harmonizing the ONO, additional metadata schemas, ontologies, controlled vocabularies, and additional concepts from external sources using a BERT-based information extraction method. BioBERT and SciBERT are finetuned with the selected articles crawled from PubMed. We listed down some queries and some examples of QA and deducing knowledge based on the KG.
翻译:关于药物、基因、蛋白质、病毒及其作用机制的结构化与非结构化数据及事实,分散于海量科学文献中。这些文献作为大规模知识源,对传播特定生物过程机制的相关知识具有重大影响。领域特定知识图谱是对特定领域概念的显式化表达,涉及具有语义关联的实体及其关系。通过整合此类事实与数据构建知识图谱,可用于数据集成、探索及联邦查询。然而,由于缺乏对底层数据资产或语义技术的了解,特定用户群体在探索和查询大规模知识图谱时面临困难。此类知识图谱不仅能推导新知识、实现问答系统,还可支持领域专家进行探索。鉴于跨学科解释对精准诊断至关重要,通过查询知识图谱对已习得的生物标志物进行交互式解释具有重要价值。受此启发,我们构建了面向癌症特异性生物标志物发现的领域知识图谱。该图谱通过整合多源癌症相关知识与事实构建:首先开发领域本体OncoNet本体(ONO),其设计目标在于通过语义推理对疾病与基因关系的预测结果进行验证;随后通过整合ONO、附加元数据模式、本体、受控词汇表及外部来源概念并采用基于BERT的信息抽取方法,构建并丰富知识图谱。我们基于从PubMed抓取的精选文献对BioBERT和SciBERT进行微调实验,并列举了基于该知识图谱的查询示例、问答系统实例及知识推导案例。